-- 设置小文件合并 set hive.merge.mapfiles=true; set hive.merge.mapredfiles=true; set hive.merge.size.per.task = 256000000 ; set hive.merge.smallfiles.avgsize= 256000000 ;

然而现实并非如此,废话不多说,you can you code,no can no bb.
原分析表数据在HDFS存储为551个小文件,下面所有的测试都是基于这个文件。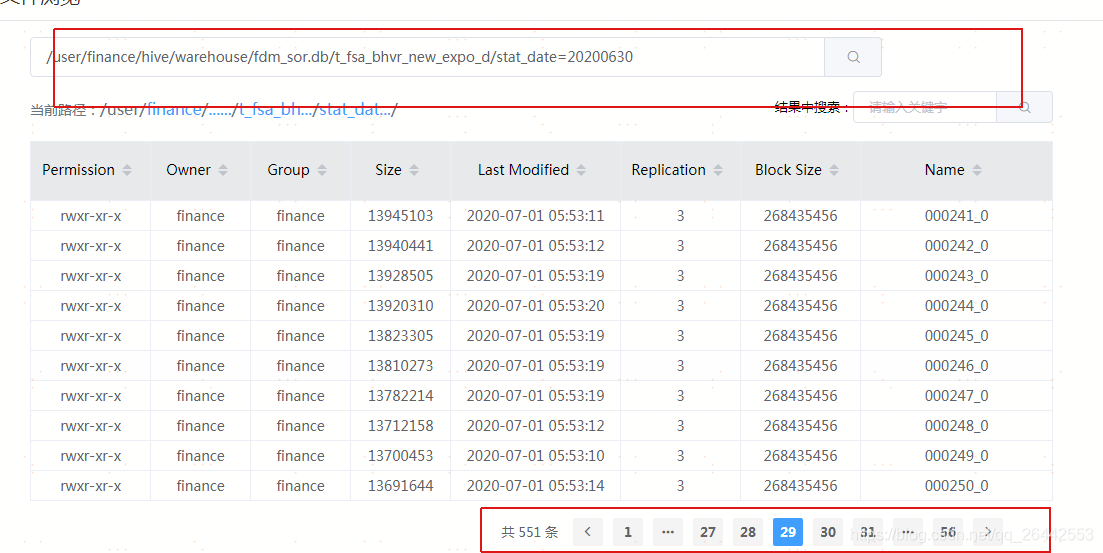
1.测试代码方案1
set hive.input.format = org.apache.hadoop.hive.ql.io.CombineHiveInputFormat; --官方默认值,也是当前平台默认值 set hive.merge.smallfiles.avgsize=16000000; --官方默认值,也是当前平台默认值 set hive.merge.size.per.task=256000000; --官方默认值,也是当前平台默认值 set hive.merge.mapfiles =true ; --官方默认值,也是当前平台默认值 set hive.merge.mapredfiles = true ; --官方默认值,也是当前平台默认值 drop table if exists FDM_SOR.T_FSA_BHVR_NEW_EXPO_D_tmp_tmp; create table FDM_SOR.t_fsa_bhvr_new_expo_d_tmp_tmp stored as orc as select * from FDM_SOR.t_fsa_bhvr_new_expo_d where stat_date = '20200630'
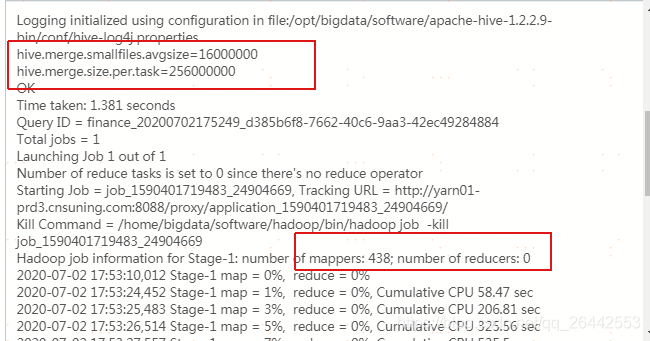

2.测试代码方案2
set hive.input.format = org.apache.hadoop.hive.ql.io.CombineHiveInputFormat; --官方默认值,也是当前平台默认值 set hive.merge.smallfiles.avgsize=256000000; --改了这个值,由默认的16Mb,改成256Mb set hive.merge.size.per.task=256000000; --官方默认值,也是当前平台默认值 set hive.merge.mapfiles =true ; --官方默认值,也是当前平台默认值 set hive.merge.mapredfiles = true ; --官方默认值,也是当前平台默认值 drop table if exists FDM_SOR.T_FSA_BHVR_NEW_EXPO_D_tmp_tmp; create table FDM_SOR.t_fsa_bhvr_new_expo_d_tmp_tmp stored as orc as select * from FDM_SOR.t_fsa_bhvr_new_expo_d where stat_date = '20200630'
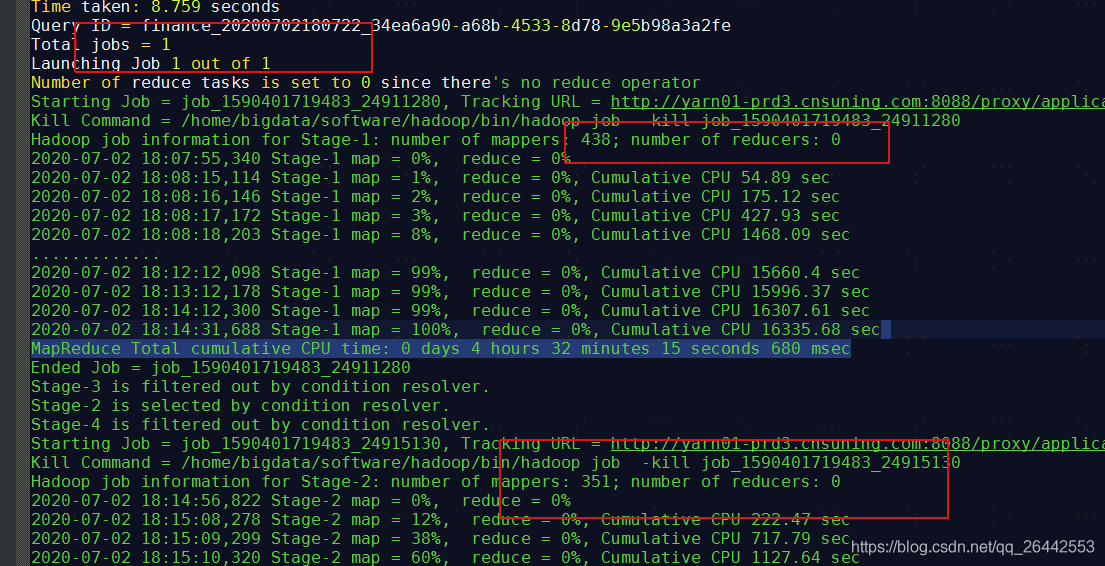
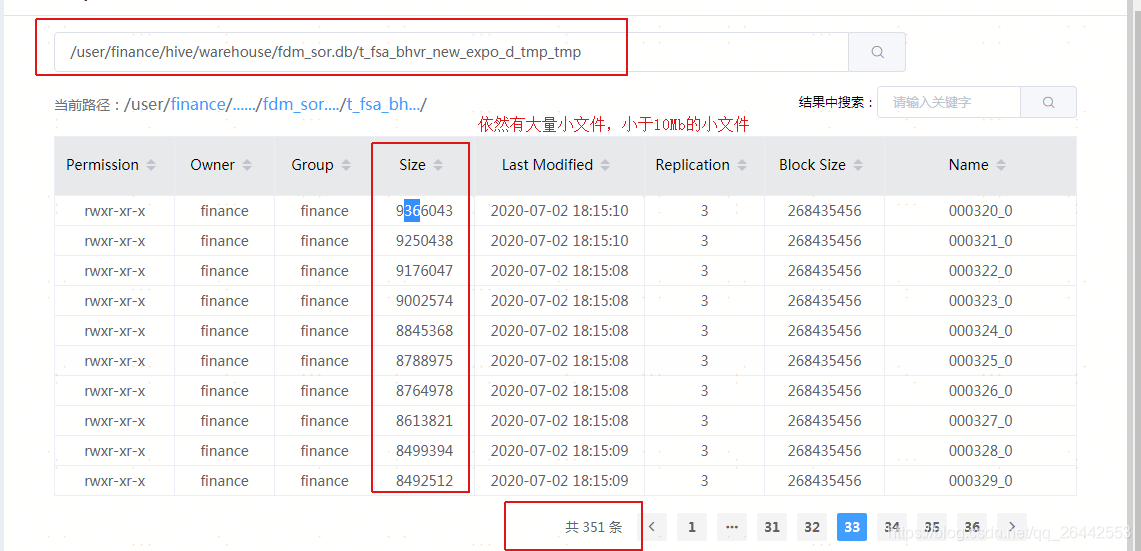


3.测试代码方案3
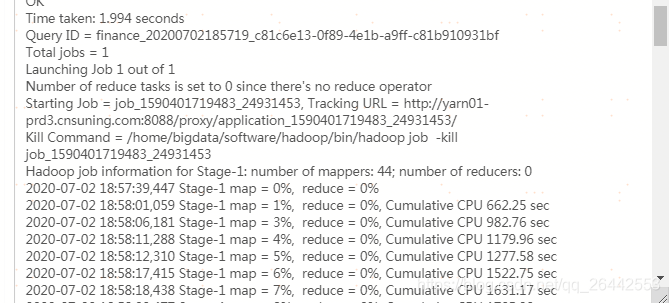
set mapred.max.split.size=256000000; set mapred.min.split.size.per.node=100000000; set mapred.min.split.size.per.rack=100000000; set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat; set hive.merge.mapfiles = true ; set hive.merge.mapredfiles = true ; set hive.merge.size.per.task = 256000000 ; set hive.merge.smallfiles.avgsize=160000000 ; drop table if exists FDM_SOR.T_FSA_BHVR_NEW_EXPO_D_tmp_tmp; create table FDM_SOR.T_FSA_BHVR_NEW_EXPO_D_tmp_tmp stored as orc as select * from FDM_SOR.T_FSA_BHVR_NEW_EXPO_D where stat_date = '20200630'
-- 设置小文件合并 set hive.merge.mapfiles=true; set hive.merge.mapredfiles=true; set hive.merge.size.per.task = 256000000 ; set hive.merge.smallfiles.avgsize= 256000000 ;
4.答案揭晓

{var%20f='http://v.t.sina.com.cn/share/share.php?appkey=1515056452',u=z||d.location,p=['&url=',e(u),'&title=',e(t||d.title),'&source=',e(r),'&sourceUrl=',e(l),'&content=',c||'gb2312','&pic=',e(p||'')].join('');function%20a(){if(!window.open([f,p].join(''),'mb',['toolbar=0,status=0,resizable=1,width=440,height=430,left=',(s.width-440)/2,',top=',(s.height-430)/2].join('')))u.href=[f,p].join('');};if(/Firefox/.test(navigator.userAgent))setTimeout(a,0);else%20a();})(screen,document,encodeURIComponent,'','','http://www.shouhuola.com/static/css/dist/css/images/default.jpg', '推荐 上瘾入骨i 的文章《大多数开发人员都弄错的Hive与MapReduce小文件合并问题》','http://www.shouhuola.com/article-1857.html','页面编码gb2312|utf-8默认gb2312'));){kind=link}
作者:涤生手记
链接:https://hero78.blog.csdn.net/article/details/107094409
来源:CSDN
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。