一.hdfs写数据流程(面试重点)
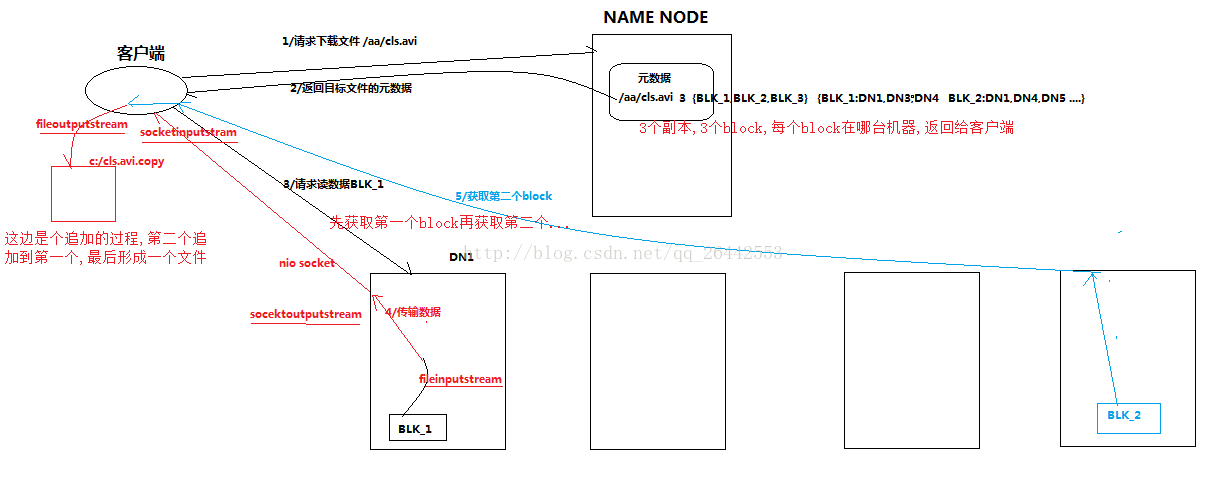
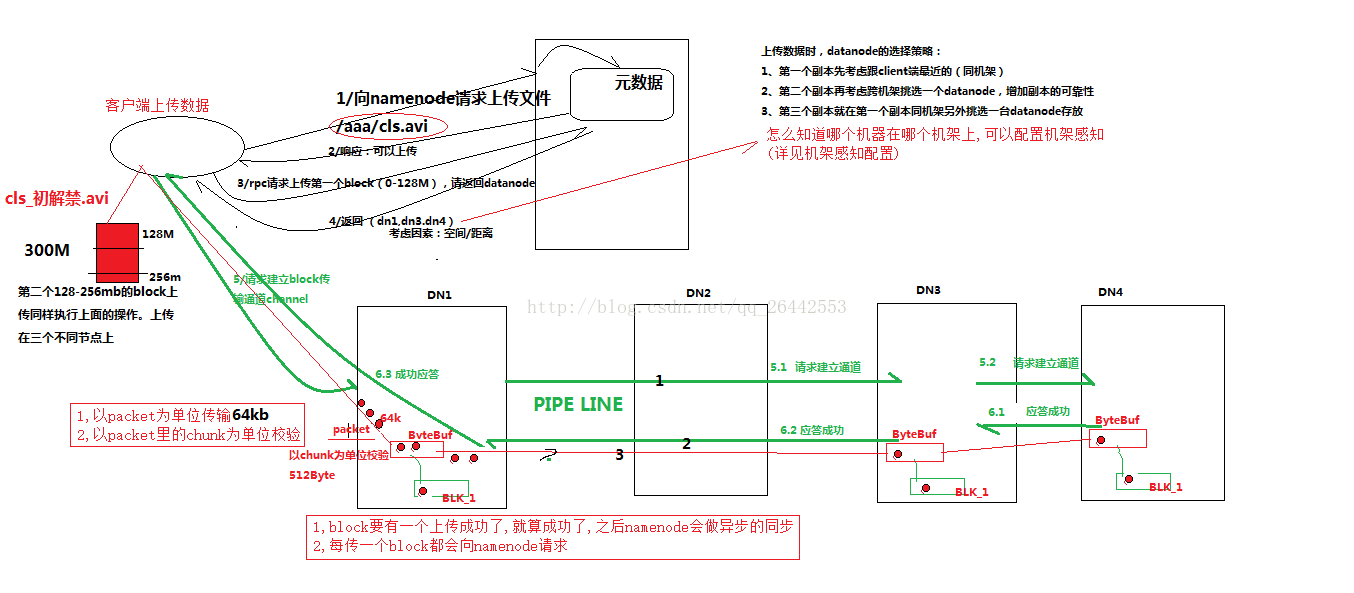
1)客户端(fs)向namenode请求上传文件,namenode检查目标文件是否已存在,父目录是否存在。
2)namenode返回是否可以上传。
3)客户端请求第一个 block上传到哪几个datanode服务器上。
4)namenode返回3个datanode节点,分别为dn1、dn2、dn3。
5)客户端请求dn1上传数据,dn1收到请求会继续调用dn2,然后dn2调用dn3,(本质上是一个RPC调用,建立pipeline)将这个通信管道建立完成
6)dn1、dn2、dn3逐级应答客户端
7)客户端开始往dn1上传第一个block(先从磁盘读取数据放到一个本地内存缓存),以packet为单位,dn1收到一个packet就会传给dn2,dn2传给dn3;dn1每传一个packet会放入一个应答队列等待应答
8)当一个block传输完成之后,客户端再次请求namenode上传第二个block的服务器。(重复执行3-7步)
补充注意:
1.namenode 实际客户端只上传一个 datanode, 其余两个是 namenode 完成的。让 datenote 自己复制的。然后复制完成以后逐级返回结果给 namenode. 如果 2,3datanode 复制失败,再有 namenode 分配新的 datanode 地址。对于客户端来说默认上传一个 datanode 就可以了,其余的由 datanode 自己复制。
2.datanode 切片是由客户端完成的。 datanode 第二三个副本的上传和第一个上传是异步的。
二:hdfs读出数据流程
{var%20f='http://v.t.sina.com.cn/share/share.php?appkey=1515056452',u=z||d.location,p=['&url=',e(u),'&title=',e(t||d.title),'&source=',e(r),'&sourceUrl=',e(l),'&content=',c||'gb2312','&pic=',e(p||'')].join('');function%20a(){if(!window.open([f,p].join(''),'mb',['toolbar=0,status=0,resizable=1,width=440,height=430,left=',(s.width-440)/2,',top=',(s.height-430)/2].join('')))u.href=[f,p].join('');};if(/Firefox/.test(navigator.userAgent))setTimeout(a,0);else%20a();})(screen,document,encodeURIComponent,'','','http://www.shouhuola.com/static/css/dist/css/images/default.jpg', '推荐 上瘾入骨i 的文章《hdfs读写文件核心流程详解巧说》','http://www.shouhuola.com/article-1908.html','页面编码gb2312|utf-8默认gb2312'));){kind=link}
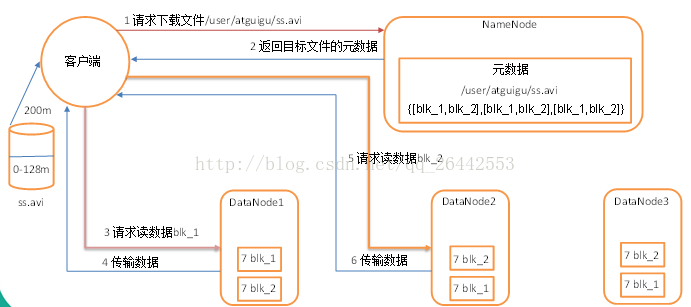
1 )客户端向 namenode 请求下载文件, namenode 通过查询元数据,找到文件块所在的 datanode 地址。
2 ) 挑选一台 datanode (就近原则,然后随机)服务器,请求读取数据。
3 ) datanode 开始传输数据给客户端(从磁盘里面读取数据放入流,以 packet 为单位来做校验)。
4 )客户端以 packet 为单位接收 ,先在本地缓存,然后写入目标文件。
三:一致性模型
1 ) debug 调试如下代码
@Test public void writeFile() throws Exception{ // 1 创建配置信息对象 Configuration configuration = new Configuration(); fs = FileSystem.get(configuration);
// 2 创建文件输出流 Path path = new Path("hdfs://hadoop102:8020/user/robot/hello.txt"); FSDataOutputStream fos = fs.create(path);
// 3 写数据 fos.write("hello".getBytes()); // 4 一致性刷新 fos.hflush();
fos.close(); } |
2 )总结
写入数据时,如果希望数据被其他 client 立即可见,调用如下方法
FsDataOutputStream. hflush (); // 清理客户端缓冲区数据,被其他 client 立即可见
作者:涤生手记
链接:https://hero78.blog.csdn.net/article/details/78529212
来源:CSDN
著作权归作者所有,转载请联系作者获得授权,切勿私自转载。