一、集群部署规划

![]()
![]() 二、 配置集群
二、 配置集群
![]()
![]() 2.1 配置文件
2.1 配置文件
![]()
![]() 2.1.1 hadoop-env.sh
2.1.1 hadoop-env.sh
Linux系统中获取JDK的安装路径
echo $JAVA_HOME1
进入hadoop-2.7.3/etc/hadoop下
修改JAVA_HOME路径
cd /usr/hadoop/hadoop-2.7.3/etc/hadoop
vi hadoop-env.sh
export JAVA_HOME=/usr/java/jdk1.8.0_171123
测试在hadoop-2.7.3文件下
bin/hadoop1
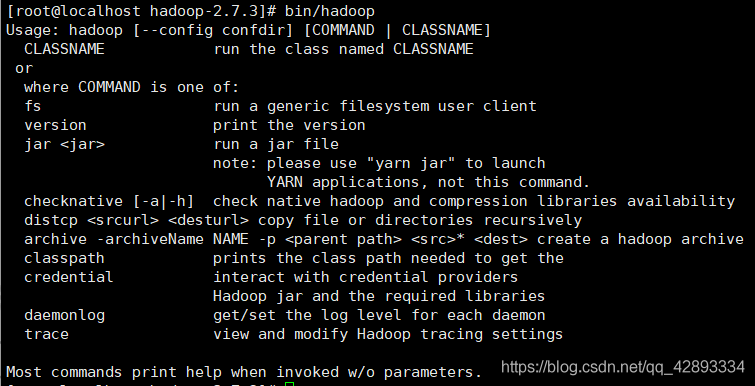 如图显示,配置成功
如图显示,配置成功
![]()
![]() 2.1.1 core-site.xml(核心文件)
2.1.1 core-site.xml(核心文件)
进入hadoop-2.7.3/etc/hadoop下
su
vi core-site.xml12
在该文件中编写如下配置(namenode的地址2改为该地址的虚拟机名字)
<!-- 指定HDFS中NameNode的地址-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://2:9000</value>
</property>
<!-- 指定Hadoop运行时产生文件的存储目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-2.7.3/data/tmp</value>
</property>1234567891011
![]()
![]() 2.1.2 hdfs-site.xml
2.1.2 hdfs-site.xml
单一节点至多存储一个节点。
3根据节点数更改
4改为辅助名称的虚拟机名字。
进入hadoop-2.7.3/etc/hadoop下
vi hdfs-site.xml1
<!-- 指定HDFS副本的数量 --><!-- 伪分布式为1-->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- 指定hadoop辅助名称节点主机配置--><!-- 伪分布式不需要添加-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>4:50090</value>
</property>1234567891011
![]()
![]() 2.1.3 mapred-site.xml
2.1.3 mapred-site.xml
进入hadoop-2.7.3/etc/hadoop下
默认情况下,/usr/local/hadoop/etc/hadoop/文件夹下有mapred.xml.template文件,我们要复制该文件,并命名为mapred.xml
复制并重命名
cp mapred-site.xml.template mapred-site.xml1
vi mapred-site.xml1
添加以下内容
<!-- 指定MR运行在YARN上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>12345
![]()
![]() 2.1.4 yarn-site.xml
2.1.4 yarn-site.xml
进入hadoop-2.7.3/etc/hadoop下
3改为RM的虚拟机名字
vi yarn-site.xml1
添加
<!-- Reducer获取数据的方式-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定YARN的ResourceManager的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>3</value>
</property>1234567891011
![]()
![]() 2.1.5 yarn-env.sh
2.1.5 yarn-env.sh
进入hadoop-2.7.3/etc/hadoop下
vi yarn-env.sh1
修改原来注释的export JAVA_HOME
export JAVA_HOME=/usr/java/jdk1.8.0_1711
![]()
![]() 2.1.6 mapred-env.sh
2.1.6 mapred-env.sh
进入hadoop-2.7.3/etc/hadoop下
vi mapred-env.sh1
修改原来注释的export JAVA_HOME
export JAVA_HOME=/usr/java/jdk1.8.0_1711
![]()
![]() 2.2 xsync分发脚本
2.2 xsync分发脚本
![]()
![]() 2.2.1 创建
2.2.1 创建
mkdir bin
cd bin/
touch xsync
vi xsync12345
![]()
![]() 2.2.2 编写
2.2.2 编写
#! /bin/bash
#1获取输入参数的个数,如果没有参数直接退出
pcount=$#
if((pcount==0));then
echo no args;
exit;
fi
#2 获取文件名称
p1=$1
fname='basename $p1'
echo fname=$fname
#3 获取上级目录到绝对路径
pdir='cd -P $(dirname $p1);pwd'
echo pdir=$pdir
#4 获取当前用户的名称
user='whoami'
#5循环
for((host=2;host<5;host++));do
echo -----------hadoop$host-----------
rsync -av $pdir/$fname $user@hadoop$host:$pdir
done123456789101112131415161718192021
出现如图内容,namenode启动成功
在hadoop-2.7.3下
hadoop-daemon.sh start/stop namenode/datanode/secondartnamenode1
必须保证NameNode和DataNode已经启动
yarn-daemon.sh start/stop resourcemanager/nodemanager
转载自:CSDN 作者:LinGavinQ
原文链接:https://blog.csdn.net/qq_42893334/article/details/107450447
{var%20f='http://v.t.sina.com.cn/share/share.php?appkey=1515056452',u=z||d.location,p=['&url=',e(u),'&title=',e(t||d.title),'&source=',e(r),'&sourceUrl=',e(l),'&content=',c||'gb2312','&pic=',e(p||'')].join('');function%20a(){if(!window.open([f,p].join(''),'mb',['toolbar=0,status=0,resizable=1,width=440,height=430,left=',(s.width-440)/2,',top=',(s.height-430)/2].join('')))u.href=[f,p].join('');};if(/Firefox/.test(navigator.userAgent))setTimeout(a,0);else%20a();})(screen,document,encodeURIComponent,'','','http://www.shouhuola.com/static/css/dist/css/images/default.jpg', '推荐 爬虫大王 的文章《【Hadoop技术】——集群配置》','http://www.shouhuola.com/article-1945.html','页面编码gb2312|utf-8默认gb2312'));){kind=link}