这篇文章讲述的是R语言中关于数据框的相关知识。希望这篇R语言文章对您有所帮助!如果您有想学习的知识或建议,可以给作者留言~
![]() Chapter05 | 因子
Chapter05 | 因子
在R中名义型变量和有序性变量称为因子,factor。这些分类变量的可能值称为一个水平,level,例如good,better,best,都称为一个leve。
由这些水平值构成的向量就称为因子。
所有元素构成因子
因子类型的数据:
state.division
state.region
因子的应用:
1、计算频数
2、独立性检验
3、相关性检验
4、方差分析
5、主成分分析
6、因子分析
1、频数统计
# cyl这一列可以当作因子类型> mtcars$cyl
[1] 6 6 4 6 8 6 8 4 4 6 6 8 8 8 8 8 8 4 4 4 4 8 8 8 8 4 4 4 8 6 8 4> table(mtcars$cyl)
4 6 8 11 7 14 1234567
使用factor()函数
> f <- factor(c("red","red","green","red","blue","green","blue","blue"))> f[1] red red green red blue green blue blue
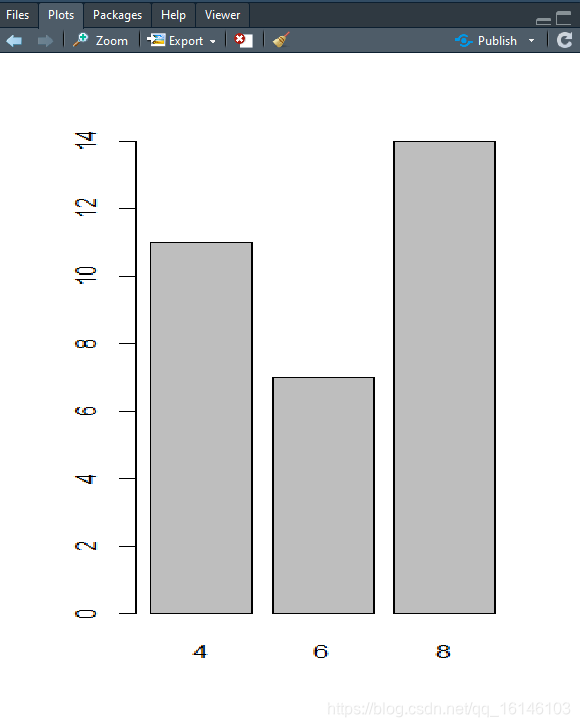
Levels: blue green red# 有序性变量也可以作为因子# 不定义levels时levels自动去重> week <- factor(c("Mon","Fri","Thu","Wed","Mon","Fri","Sun"))> week[1] Mon Fri Thu Wed Mon Fri SunLevels: Fri Mon Sun Thu Wed# 自定义levels不允许重复> week <- factor(c("Mon","Fri","Thu","Wed","Mon","Fri","Sun"),order = TRUE,+ levels = c("Mon","Tue","Wed","Thu","Fri","Sat","Sun"))> week[1] Mon Fri Thu Wed Mon Fri SunLevels: Mon < Tue < Wed < Thu < Fri < Sat < Sun# 一个向量转换成因子,直接输入到factor()内即可> fcyl <- factor(mtcars$cyl)> fcyl [1] 6 6 4 6 8 6 8 4 4 6 6 8 8 8 8 8 8 4 4 4 4 8 8 8 8 4 4 4 8 6 8 4Levels: 4 6 812345678910111213141516171819202122232425plot(mtcars$cyl)1
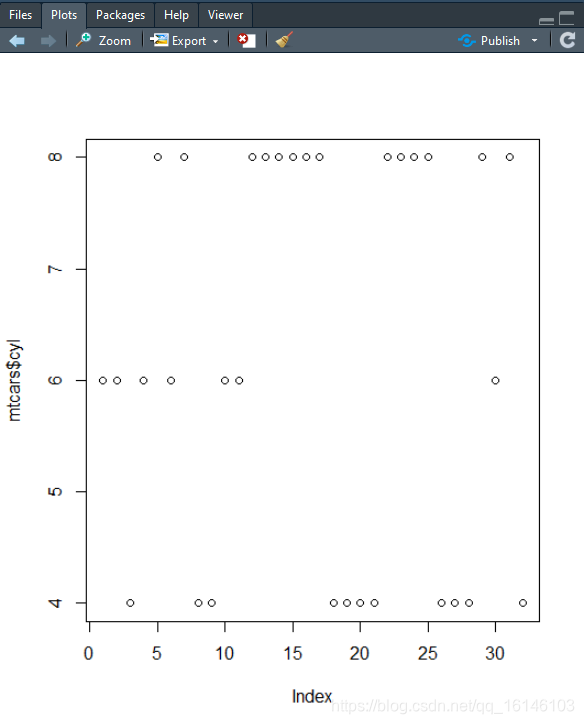
plot(fcyl)1
cut函数可以将连续性变量x分割为n个水平的因子
> num <- c(1:100)> num [1] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22
[23] 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44
[45] 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66
[67] 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88
[89] 89 90 91 92 93 94 95 96 97 98 99 100# 每隔10个进行分组> cut (num,c(seq(0,100,10)))
[1] (0,10] (0,10] (0,10] (0,10] (0,10] (0,10] (0,10] (0,10] (0,10]
[10] (0,10] (10,20] (10,20] (10,20] (10,20] (10,20] (10,20] (10,20] (10,20]
[19] (10,20] (10,20] (20,30] (20,30] (20,30] (20,30] (20,30] (20,30] (20,30]
[28] (20,30] (20,30] (20,30] (30,40] (30,40] (30,40] (30,40] (30,40] (30,40]
[37] (30,40] (30,40] (30,40] (30,40] (40,50] (40,50] (40,50] (40,50] (40,50]
[46] (40,50] (40,50] (40,50] (40,50] (40,50] (50,60] (50,60] (50,60] (50,60]
[55] (50,60] (50,60] (50,60] (50,60] (50,60] (50,60] (60,70] (60,70] (60,70]
[64] (60,70] (60,70] (60,70] (60,70] (60,70] (60,70] (60,70] (70,80] (70,80]
[73] (70,80] (70,80] (70,80] (70,80] (70,80] (70,80] (70,80] (70,80] (80,90]
[82] (80,90] (80,90] (80,90] (80,90] (80,90] (80,90] (80,90] (80,90] (80,90]
[91] (90,100] (90,100] (90,100] (90,100] (90,100] (90,100] (90,100] (90,100] (90,100][100] (90,100]10 Levels: (0,10] (10,20] (20,30] (30,40] (40,50] (50,60] (60,70] (70,80] ... (90,100]123456789101112131415161718192021222324
如果数字较大,我们可以通过cut()函数进行频数统计,很方便
转载自:CSDN 作者:不温卜火
原文链接:https://blog.csdn.net/qq_16146103/article/details/105420919
{var%20f='http://v.t.sina.com.cn/share/share.php?appkey=1515056452',u=z||d.location,p=['&url=',e(u),'&title=',e(t||d.title),'&source=',e(r),'&sourceUrl=',e(l),'&content=',c||'gb2312','&pic=',e(p||'')].join('');function%20a(){if(!window.open([f,p].join(''),'mb',['toolbar=0,status=0,resizable=1,width=440,height=430,left=',(s.width-440)/2,',top=',(s.height-430)/2].join('')))u.href=[f,p].join('');};if(/Firefox/.test(navigator.userAgent))setTimeout(a,0);else%20a();})(screen,document,encodeURIComponent,'','','http://www.shouhuola.com/static/css/dist/css/images/default.jpg', '推荐 爬虫大王 的文章《R语言入门 Chapter05 | 因子》','http://www.shouhuola.com/article-2016.html','页面编码gb2312|utf-8默认gb2312'));){kind=link}