{var%20f='http://v.t.sina.com.cn/share/share.php?appkey=1515056452',u=z||d.location,p=['&url=',e(u),'&title=',e(t||d.title),'&source=',e(r),'&sourceUrl=',e(l),'&content=',c||'gb2312','&pic=',e(p||'')].join('');function%20a(){if(!window.open([f,p].join(''),'mb',['toolbar=0,status=0,resizable=1,width=440,height=430,left=',(s.width-440)/2,',top=',(s.height-430)/2].join('')))u.href=[f,p].join('');};if(/Firefox/.test(navigator.userAgent))setTimeout(a,0);else%20a();})(screen,document,encodeURIComponent,'','','http://www.shouhuola.com/static/css/dist/css/images/default.jpg', '推荐 野的像风 的文章《python BeautifulSoup爬取豆瓣电影top250信息并写入Excel表格》','http://www.shouhuola.com/article-52283.html','页面编码gb2312|utf-8默认gb2312'));){kind=link}
豆瓣是一个社区网站,创立于2005年3月6日。该网站以书影音起家,提供关于书籍,电影,音乐等作品信息,其描述和评论都是由用户提供的,是Web2.0网站中具有特色的一个网站。
豆瓣电影top250网址:https://movie.douban.com/top250?start=0&filter=
BeautifulSoup解析提取信息的具体过程请看BeautifulSoup爬取豆瓣电影top250信息 ,我在其中具体讲解了BeautifulSoup的用法,下面的内容是我把它输出的内容写入Excel表格。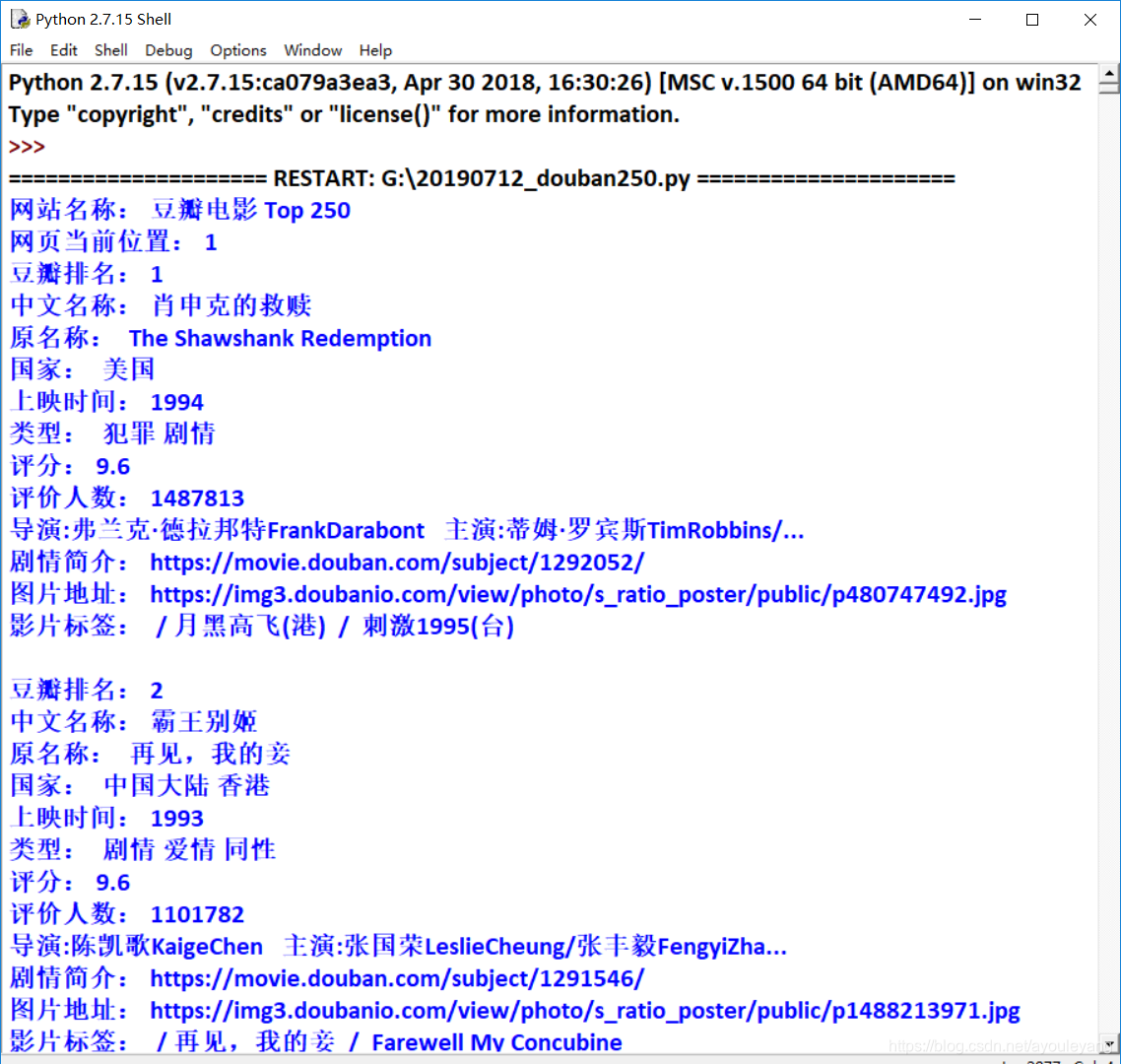
![]()
![]() 把上面的信息改为写进表格,源码如下:
把上面的信息改为写进表格,源码如下:
#!/usr/bin/env python3# -*- coding: utf-8 -*-import reimport urllib.requestfrom bs4 import BeautifulSoupimport xlwt
urls = "https://movie.douban.com/top250"html = urllib.request.urlopen(urls).read()soup = BeautifulSoup(html, "html.parser")all_page=[]print(u'网站名称:', soup.title.string.replace("\n", ""))# 定位代码范围、爬虫部分def part(url):
html = urllib.request.urlopen(url).read()
soup = BeautifulSoup(html, "html.parser")
for tag in soup.find_all(attrs={"class": "item"}):
try:
ta=tag.find('em').string #print(u'豆瓣排名:', ta)
name=tag.find('span').string
#print(u'中文名称:', name)
English = tag.find_all('span')[1].get_text()
yuanName = English.split('/')[1]
#print(u'原名称:', yuanName)
country = tag.p.get_text().split('/')[-2]
#print(u'国家:', country)
time = tag.p.get_text().split('\n')[2].split('/')[0].replace(" ", "")
#print(u'上映时间:', time)
Leixing = tag.p.get_text().split('\n')[2].split('/')[-1]
#print(u'类型:', Leixing)
# 电影评分
# print tag.find_all('span')[4].get_text() 方法1(不建议使用,多处出错)
price = tag.find_all(attrs={"class": "rating_num"}) # 方法2
sore = price[0].get_text()
#print(u'评分:', sore)
# 评价人数 方法1 (在第220名《我不是药神》网页错乱会导致出错)
#valuation = tag.find_all('span')[-2].get_text()
#regex = re.compile(r"\d+\.?\d*") # 使用正则表达式保留数字
#people = regex.findall(valuation)[0]
#print(u'评价人数:',people)
# 评价人数 方法2(节点重新定位,建议使用)
for peo in tag.find_all(attrs={"class":"star"}):
valuation = peo.find_all('span')[-1].get_text()
regex = re.compile(r"\d+\.?\d*")
people = regex.findall(valuation)[0]
#print(u'评价人数:',people)
# 导演及主演
join = tag.p.next_element # p的后节点
role = join.replace("\n", "").replace(" ", "")
#print(role)
introduce = tag.a.get('href')
#print(u'剧情简介:', introduce)
img = tag.img.get('src')
#print(u'图片地址:',img)
lab = tag.find_all(attrs={"class": "other"})
lable = lab[0].get_text()
#print(u'影片标签:', lable)
#print()
page=[ta,name,yuanName,country,time,Leixing,sore,people,role,introduce,img,lable]
all_page.append(page)
# print(all_page)
except IndexError:
passif __name__ == '__main__':
i = 0
while i < 10:
print(u'网页当前位置:', (i + 1))
num = i * 25
url = 'https://movie.douban.com/top250?start=' + str(num) + '&filter='
part(url)
book = xlwt.Workbook(encoding='utf-8')
sheet = book.add_sheet('电影排名表')
head = ['豆瓣排名','电影名', '原名称','国家','时间','类型','评分','评价人数','角色','介绍','图片地址','影片标签']
for h in range(len(head)):
sheet.write(0,h,head[h])
j=1
for list in all_page:
k=0
for data in list:
#print(data)
sheet.write(j,k,data)
k=k+1
j+=1
book.save('豆瓣电影top250.xls')
i = i + 1
123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869707172737475767778798081828384858687888990919293949596979899100101102103104105106107写入表格的结果: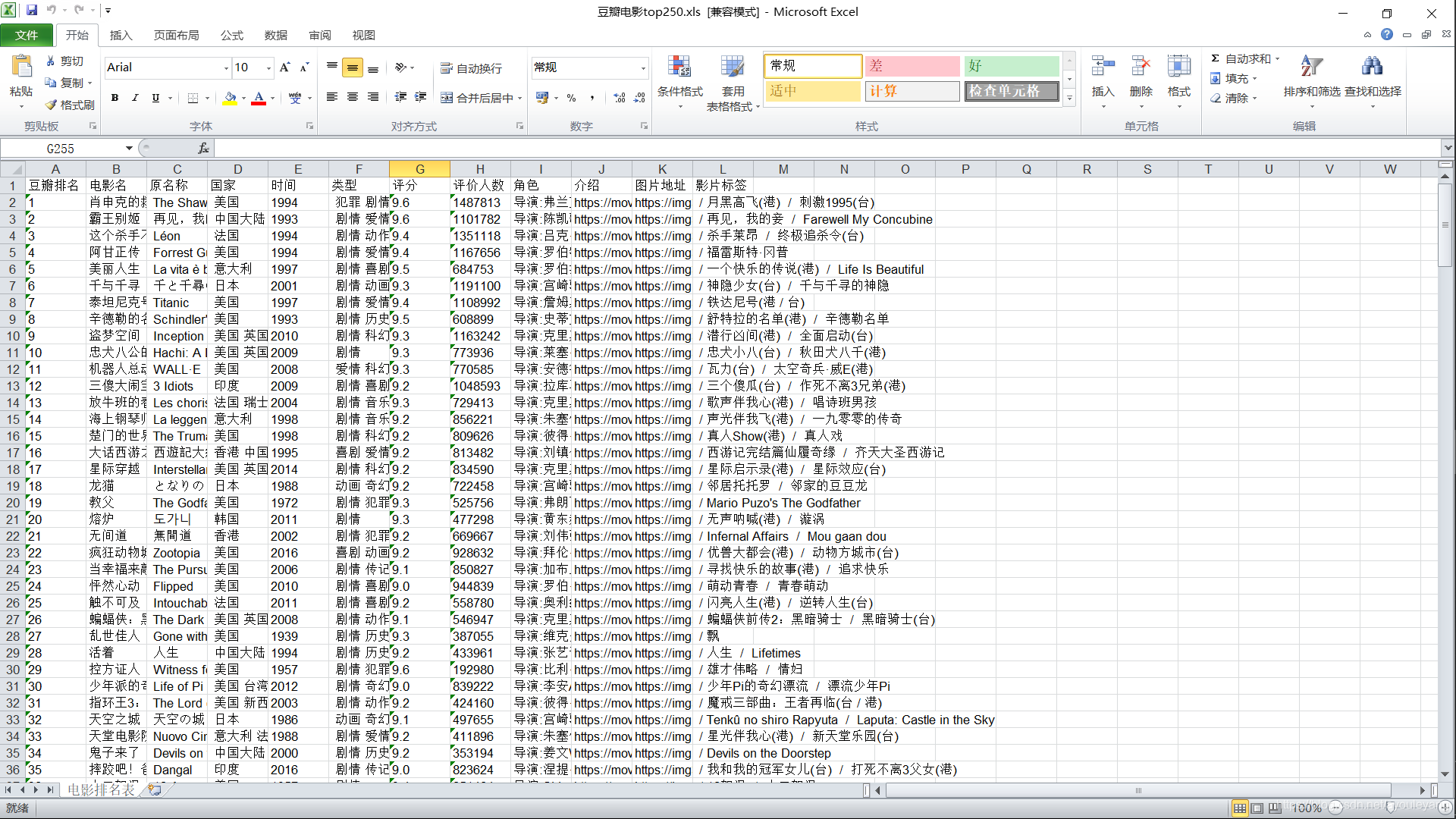
![]()
![]() 注意:
注意:
上面代码评价人数获取方法一运行会出现一个错:
出现的原因: 《我不是药神》模块缺少一个P便签中的<span> ,所有导致tag.find_all('span')[-2].get_text() 定位出现错乱,在此停止了运行,如图所示: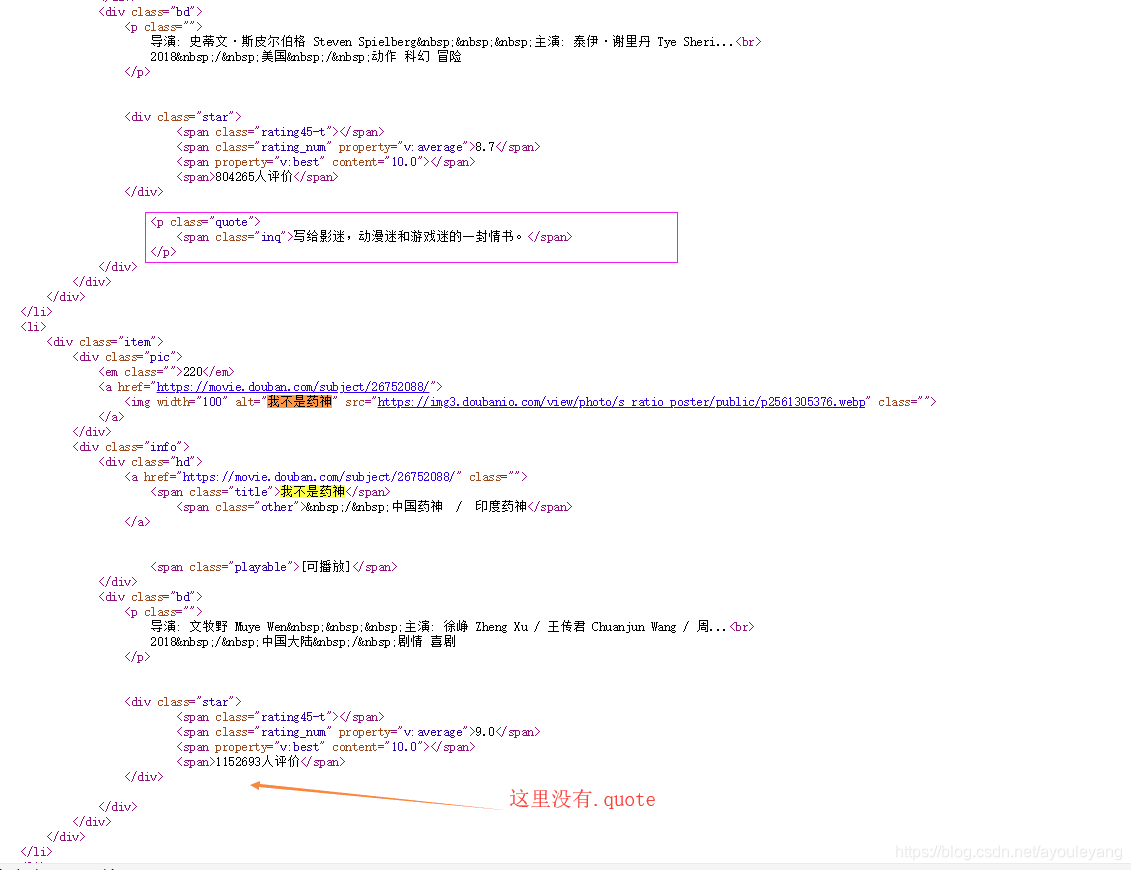
我重新用tag.find_all(attrs={"class":"star"})进行定位,精确模块查找!
源码解析内容详情:https://blog.csdn.net/ayouleyang/article/details/95719813
作者:阿优乐扬
链接:https://blog.csdn.net/ayouleyang/article/details/96023950
来源:CSDN
著作权归作者所有,转载请联系作者获得授权,切勿私自转载。