我上次分享过关于爬取豆瓣电影top250的实战:BeautifulSoup爬取豆瓣电影top250信息 和 python BeautifulSoup爬取豆瓣电影top250信息并写入Excel表格 ,豆瓣网没有反爬虫机制,对于学习爬虫的小白是一个不错的学习对象,python xpath我是初步学习,对豆瓣图书 Top 250 进行实战学习,xpath的优点之一就是可以直接复制获取信息的节点,如图:
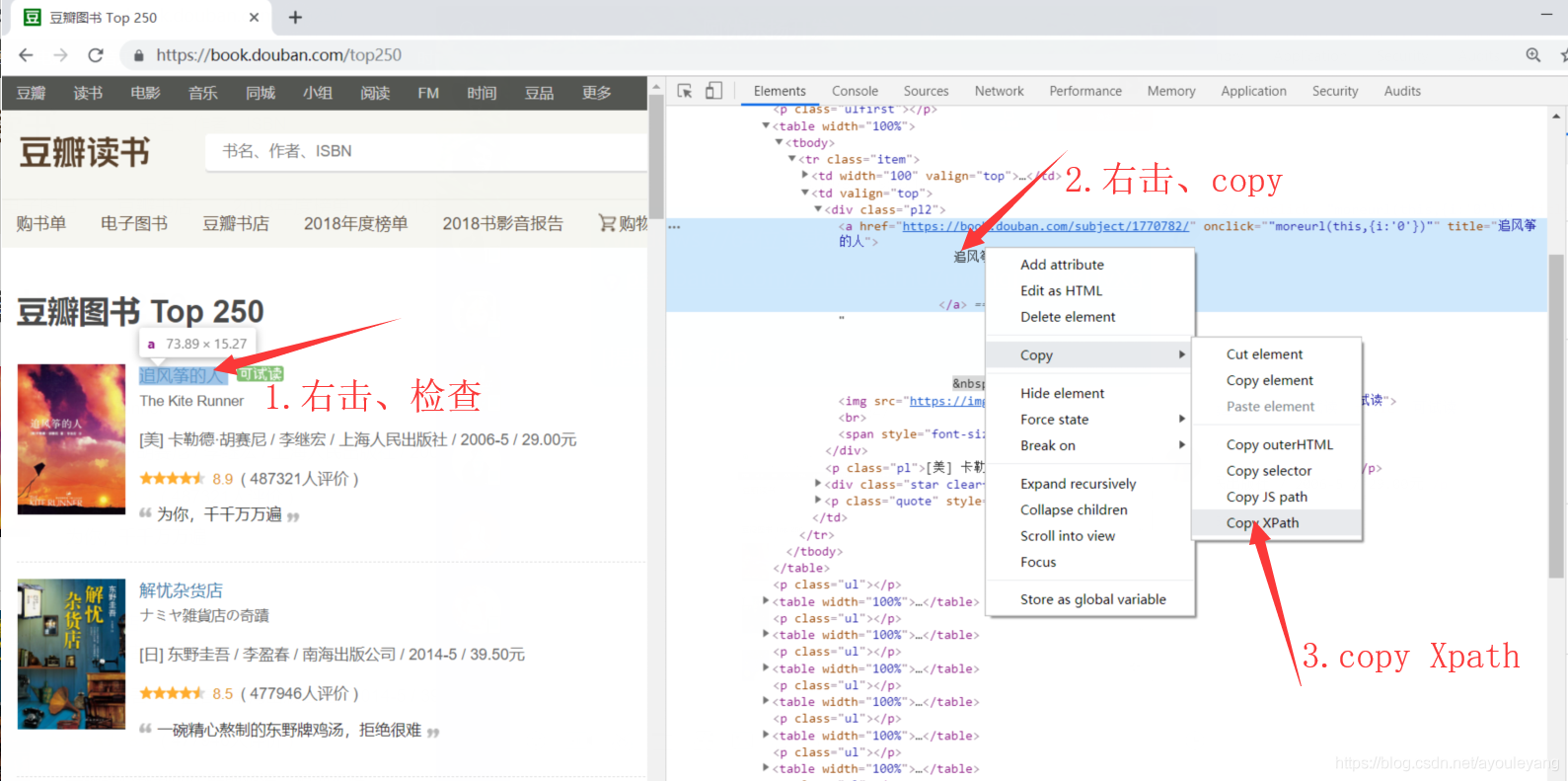
我要爬取的数据还是比较全面的,几乎都没有放过,有(排名,书名,地址,作者,翻译,星级,评分,评价,单价,出版社,出版日期,国家,评价),其中“排名”在网页上没有,需要自己加上去,相比于豆瓣电影,豆瓣图书的坑更多。
![]()
![]() 爬豆瓣图书需要注意的几个坑!!!
爬豆瓣图书需要注意的几个坑!!!
1、图书在top250的排名
2、从p标签中截取作者、翻译者
3、获取星级数
4、截取国家
5、评价
6、csv乱码 (其实没错,就是乱码)
![]()
![]() 下面来讲解一下我解决这几个坑的的思路:
下面来讲解一下我解决这几个坑的的思路:
1、图书在top250的排名
在网页中没有显示它的排名,但我们都知道它是降序排的,从1~250,所有就直接通过循环写进csv就行了,但是初始值一定不能放在循环函数内,否则它就会被重新赋值或者只输出一个值,正确方法如下:
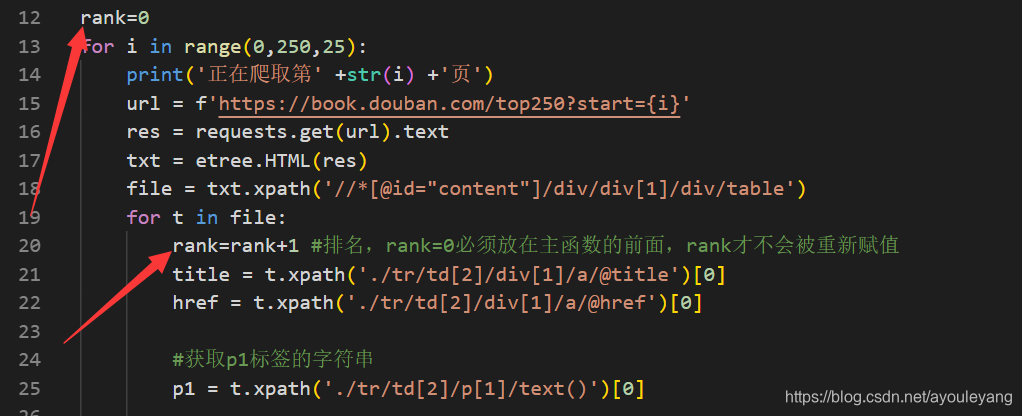
2、从p标签中截取作者、翻译者
这些信息都在p标签中,但国外的著作和国内的排布不一样,国外的会有翻译者在其中,中国的就只有作者一个,排名31的《倾城之恋》就没有作者。
2.1、国外著作p标签内容为:
<p class="pl">[国家] 作者 / 翻译者 / 出版社 /出版日期 / 价格</p>1

获取的方法:

2.2、国内著作p标签内容为:
<p class="pl">作者 / 出版社 /出版日期 / 价格</p>1

获取的方法:

2.3、没有作者的情况:

获取的方法:
(1)先对p标签分割成字符串
(2)len(p1.split(’/’)) 算出字符串的长度,这里的3是我先计算出来的,如果字符串长度等于3,说明它没有作者。
elif len(p1.split('/'))==3:
author = ' '123、获取星级数
注意: 字符串不能直接被除,需要转化为int型


4、截取国家
只要会截取作者和翻译者,这个问题就不大了。也是通过“[外国]”来判断它的国籍的,中国的都没有写出来,所有没有“[ ]”的,我全部默认为中国,包括没有作者的。
#截取国家
if '[' in p1:
country = p1.split('[')[1].split(']')[0]
else:
country = '中' #没有国家的我默认为“中国”12345
5、评价
评价不是没有本书都有,所有必须要进行判断,才能获取
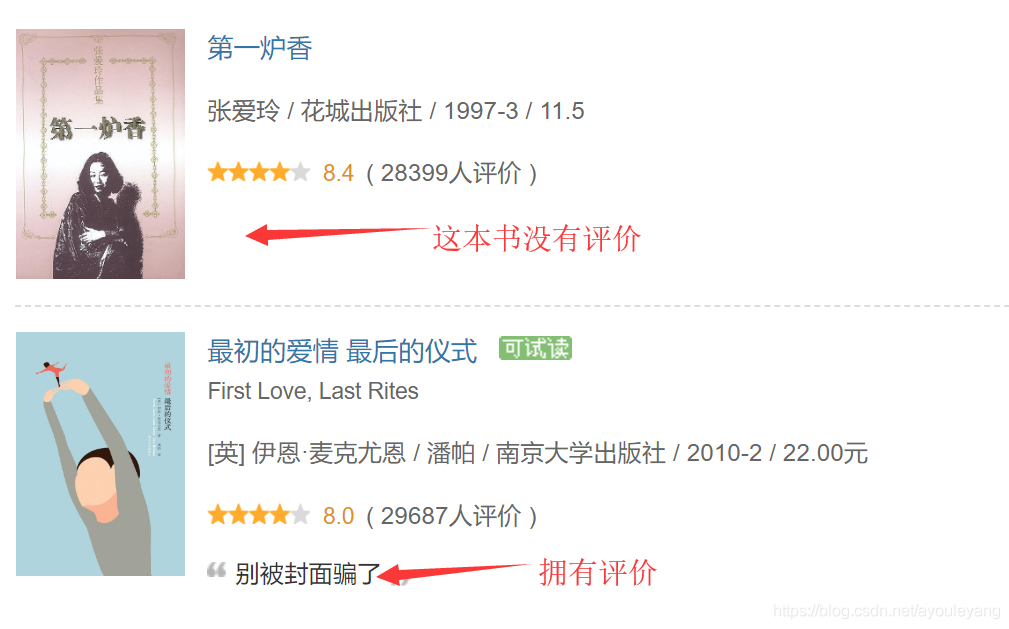
代码实现方式:
(1)先获取评价在的位置
(2)通过字符串长度判断它是否存在,如果字符串长度不等于0,就截取comments[0],否则为空。
#评价comments = t.xpath('./tr/td/p/span/text()')comment = comments[0] if len(comments) != 0 else ""123
6、csv乱码
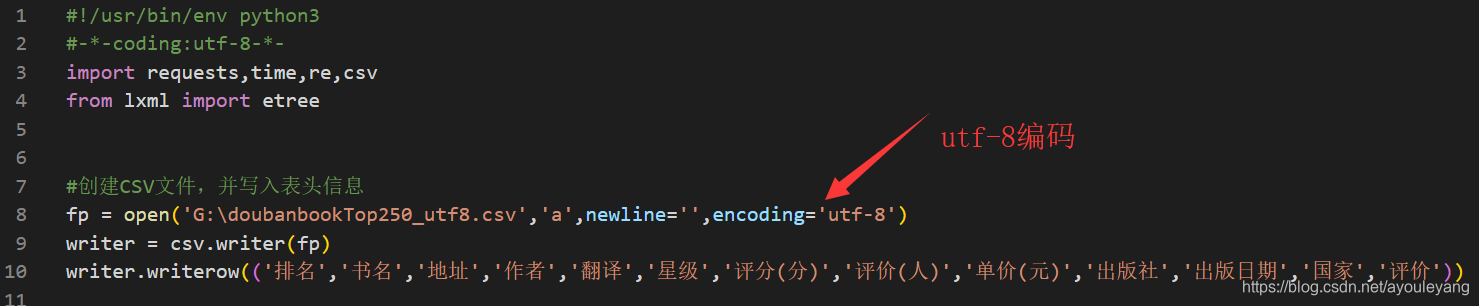
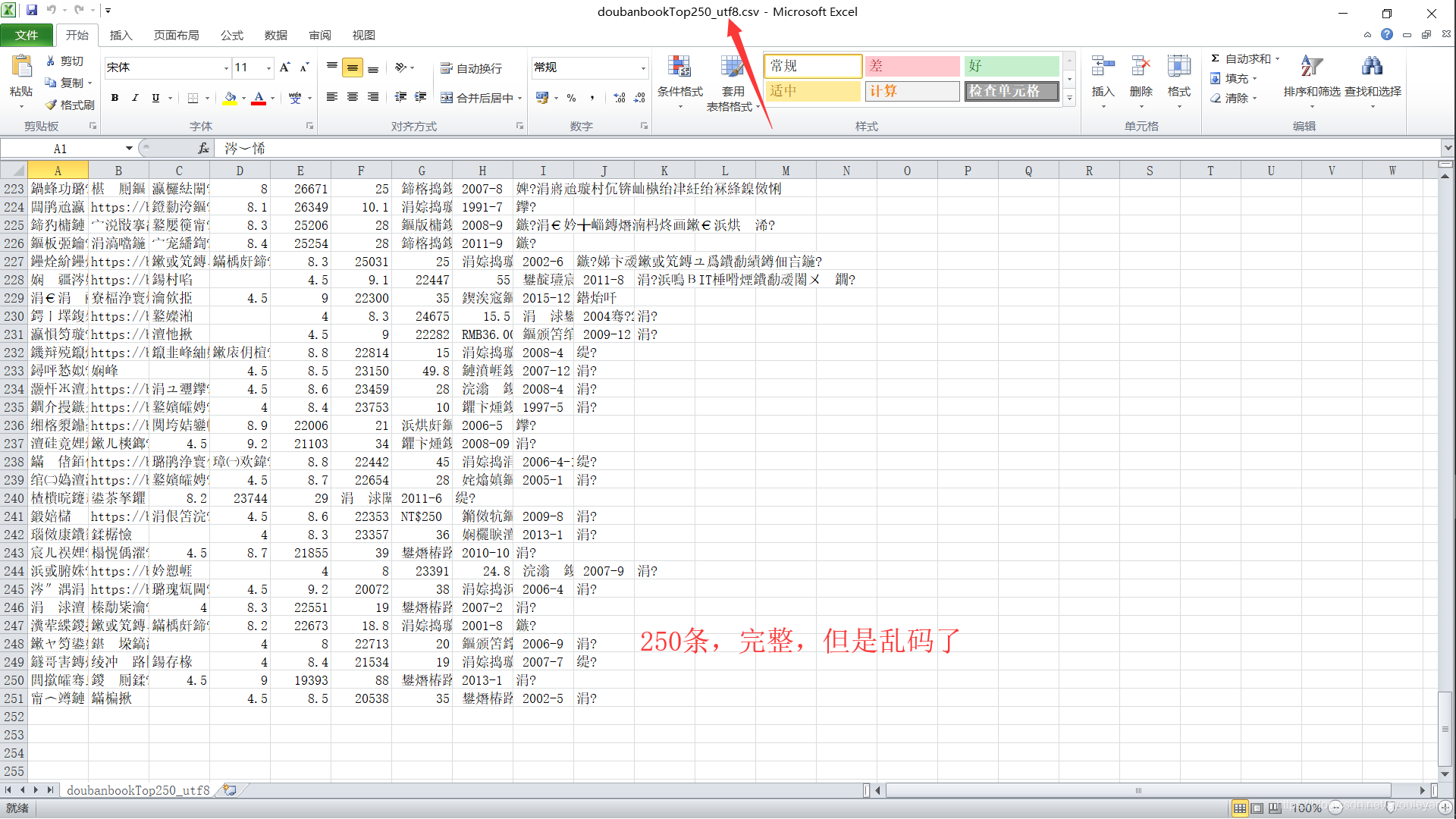
注意:这并不是编码方式不对。我重新更换保存在csv的方法,没有解决,后来我把我电脑的编码的方式也调成了默认utf-8,也没有解决问题。
成功的解决方法:
(1)新建一个Excel文件并打开
(2)数据>自文本>找到刚爬取的.csv文件导入
(3)弹出框,勾选“分隔符号”>下一步>取消“Tab键”,勾选“逗号”>下一步>勾选“常规”>完成>确定
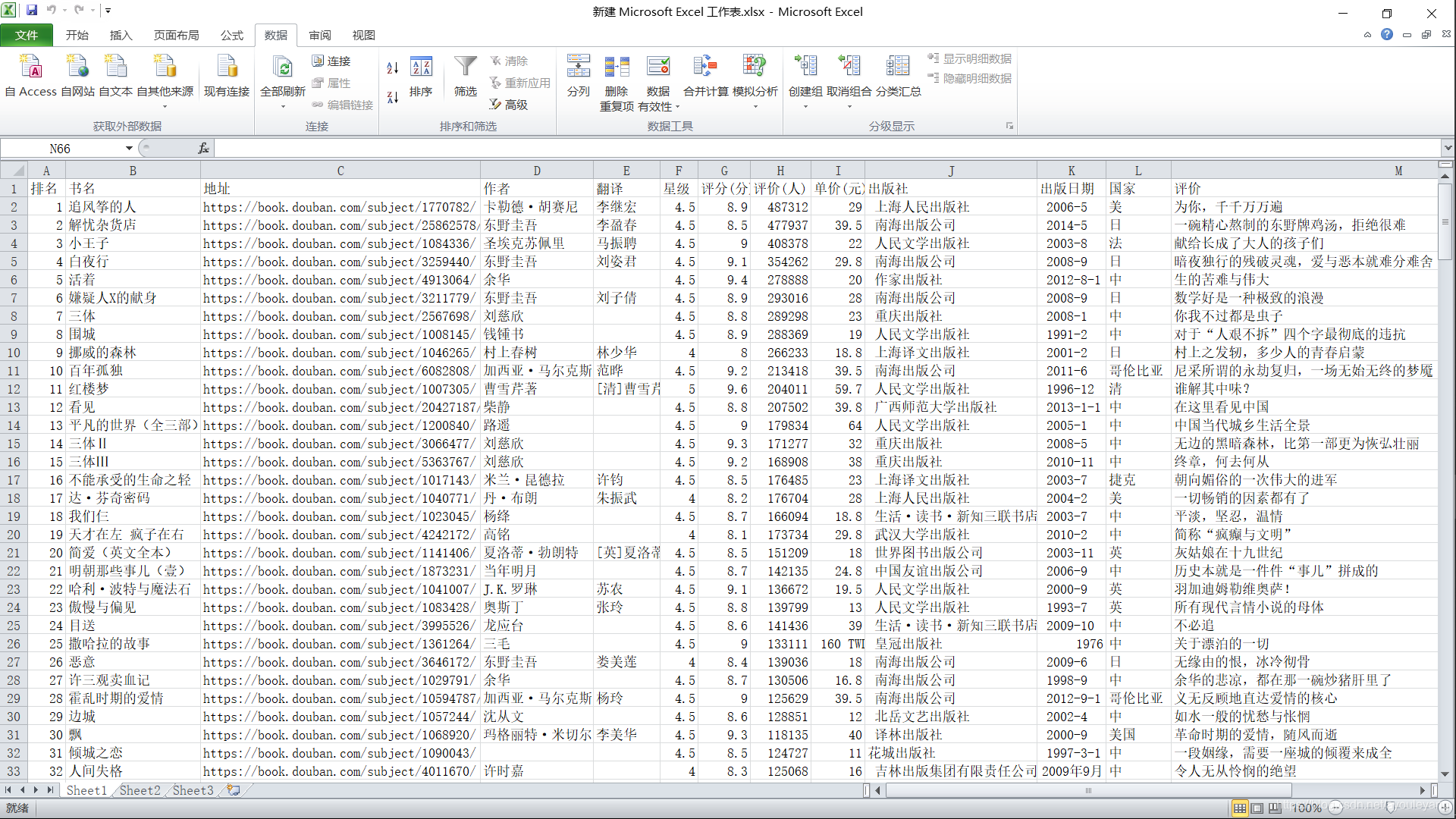
完美显示内容!!!
完整源代码如下:
#!/usr/bin/env python3#-*-coding:utf-8-*-import requests,time,re,csvfrom lxml import etree#创建CSV文件,并写入表头信息fp = open('G:\doubanbookTop250_utf8.csv','a',newline='',encoding='utf-8')writer = csv.writer(fp)writer.writerow(('排名','书名','地址','作者','翻译','星级','评分(分)','评价(人)','单价(元)','出版社','出版日期','国家','评价'))rank=0for i in range(0,250,25):
print('正在爬取第' +str(i) +'页')
url = f'https://book.douban.com/top250?start={i}'
res = requests.get(url).text
txt = etree.HTML(res)
file = txt.xpath('//*[@id="content"]/div/div[1]/div/table')
for t in file:
rank=rank+1 #排名,rank=0必须放在主函数的前面,rank才不会被重新赋值
title = t.xpath('./tr/td[2]/div[1]/a/@title')[0]
href = t.xpath('./tr/td[2]/div[1]/a/@href')[0]
#获取p1标签的字符串
p1 = t.xpath('./tr/td[2]/p[1]/text()')[0]
#截取作者
if '[' in p1:
author = p1.split(']')[1].split('/')[0].replace(" ","")
elif len(p1.split('/'))==3:
author = ' '
elif '[' not in p1:
author = p1.split('/')[-4].replace(" ","")
else:
author = ' '
#获取翻译者
if '[' in p1:
translator = p1.split('/')[-4].replace(" ","")
elif len(p1.split('/'))==3:
translator = ' '
else:
translator = ' '
#获取星级数
str1 = t.xpath('./tr/td[2]/div[2]/span[1]/@class')[0].replace("allstar","")
num = int(str1)
star = num/10
#获取评分
score = t.xpath('./tr/td[2]/div[2]/span[2]/text()')[0]
#获取评价人数
n = t.xpath('./tr/td[2]/div[2]/span[3]/text()')[0]
people = re.sub("\D","",n)
#截取单价
if '元' in p1:
price = p1.split('/')[-1].split('元')[0]
else:
price = p1.split('/')[-1]
#截取出版社
publisher = p1.split('/')[-3]
#截取出版时间
time = p1.split('/')[-2]
#截取国家
if '[' in p1:
country = p1.split('[')[1].split(']')[0]
else:
country = '中' #没有国家的我默认为“中国”
#评价
comments = t.xpath('./tr/td/p/span/text()')
comment = comments[0] if len(comments) != 0 else ""
# 写入数据
writer.writerow((rank,title,href,author,translator,star,score,people,price,publisher,time,country,comment))# 关闭文件fp.close()
作者:阿优乐扬
链接:https://blog.csdn.net/ayouleyang/article/details/98397482
来源:CSDN
著作权归作者所有,转载请联系作者获得授权,切勿私自转载。
{var%20f='http://v.t.sina.com.cn/share/share.php?appkey=1515056452',u=z||d.location,p=['&url=',e(u),'&title=',e(t||d.title),'&source=',e(r),'&sourceUrl=',e(l),'&content=',c||'gb2312','&pic=',e(p||'')].join('');function%20a(){if(!window.open([f,p].join(''),'mb',['toolbar=0,status=0,resizable=1,width=440,height=430,left=',(s.width-440)/2,',top=',(s.height-430)/2].join('')))u.href=[f,p].join('');};if(/Firefox/.test(navigator.userAgent))setTimeout(a,0);else%20a();})(screen,document,encodeURIComponent,'','','http://www.shouhuola.com/static/css/dist/css/images/default.jpg', '推荐 野的像风 的文章《python xpath爬取豆瓣图书Top 250存入csv文件并解决csv乱码问题》','http://www.shouhuola.com/article-52285.html','页面编码gb2312|utf-8默认gb2312'));){kind=link}