京东商城: 京东JD.COM-专业的综合网上购物商城,中国自营式电商企业,创始人刘强东担任京东集团董事局主席兼首席执行官。销售超数万品牌、4020万种商品,囊括家电、手机、电脑、母婴、服装等13大品类。1998年6月18日在中关村成立京东公司。2013年正式获得虚拟运营商牌照。2014年5月在美国纳斯达克证券交易所正式挂牌上市。
爬取京东商品: 产品名称、价格、评论人数、商店
操作环境: python3.6+Jupyter notebook、 win10 、谷歌
python库: selenium、lxml、time
技术难点:
1. 控制爬取的页数
为什么要控制爬取的页数?当你随便搜索一个商品,它加载的数据就会有好几十页,甚至高达100页,后面的商品可能只是类似商品或者重复的商品,我们就只截取一部分来练习,不可能爬个不停,能自己控制范围更方便控制数据。
2. 模拟下拉加载数据
京东商城为了节约用户的数据流量,网页使用下拉加载的方式,用户下拉到哪里,它的商品数据就加载到哪里,提高网页的请求速度。如果我们不模拟下拉(鼠标向下滚动)加载,可能就只能获取前面商品的数据,因为后面的商品都还没有加载出来呢。
技术思路:
1、控制浏览器打开京东官网
2、获取搜索的关键词并回车
3、打印出网页最大页数并输入要获取的页数
4、模拟下拉网页加载数据
5、获取网页源码
6、使用lxml库提取数据并判断是否进行下一页
7、满足条件就点击下一页
8、跳转到下一页继续模拟下拉加载数据爬取
9、直到爬完输入页才结束
![]() 技术难点介绍:
技术难点介绍:
一、 控制爬取的页数
1.1、必须先让程序打印最大页我们才知道最大可以获取多少页
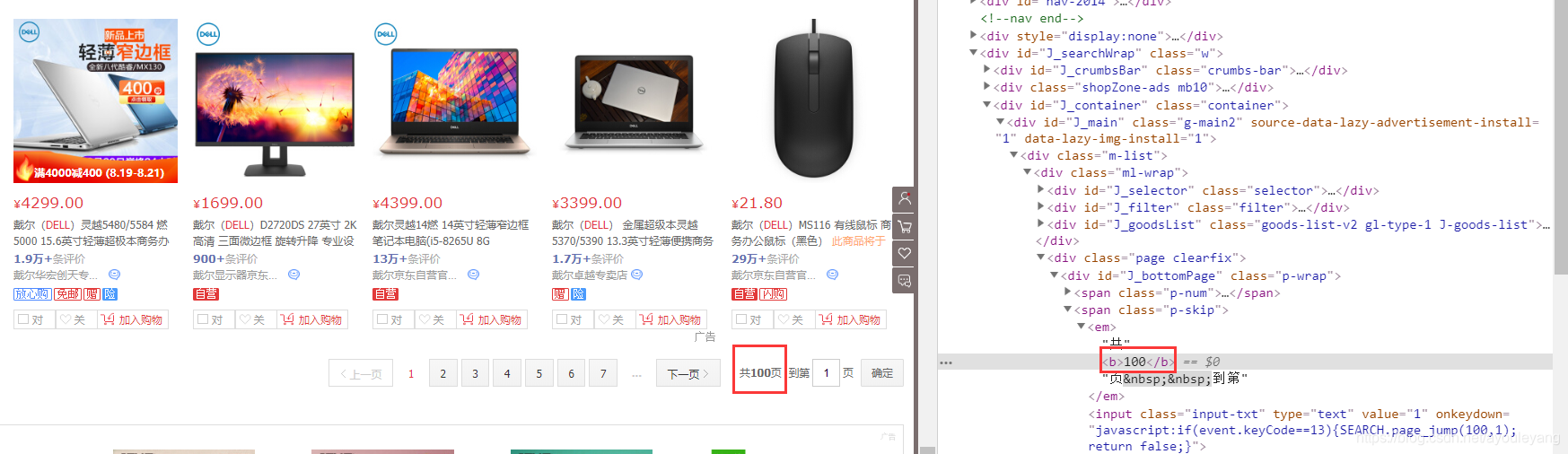
打开网页就可以直接查看它的最大页数,然后把网页的最大的页数打印出来供我们选择爬取的页数,就可以输入需要获取的页数了。
max_page = driver.find_element_by_xpath('//*[@id="J_bottomPage"]/span[2]/em[1]/b').text#找到当前商品的最大页数
print ("你查询的当前商品共%s页"%max_page)
global endPage#声明作为全局变量使用
endPage = int(input("请输入你要获取到的页数:"))1234运行结果:
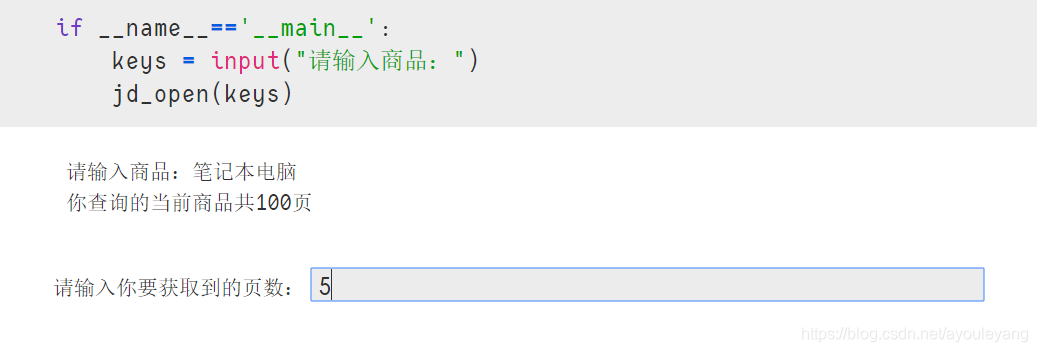
1.2、是否点击下一页
可以在本页爬取数据以后再进行判断是否继续点击下一页,实现代码如下:
global endPage#声明要使用上面的全局变量
global p#作为循环的页数使用
while p < endPage:#商品页面太多,有必要选取爬取
p = p + 1
print ("正在获取第%s页"%p)
next_page()123456重点: 需要把p和输入的endPage作为为全局变量使用,在主函数前声明这是一个全局变量并附初始值。在使用前必须使用关键词global 声明要用这个全局变量,否则每次循环它都会默认为这是第一次做循环。
二、 模拟下拉加载数据
2.1、查询网页下拉加载的总长度
可以直接选择手动获取:
右键检查---->Console---->document.documentElement.scrollTop
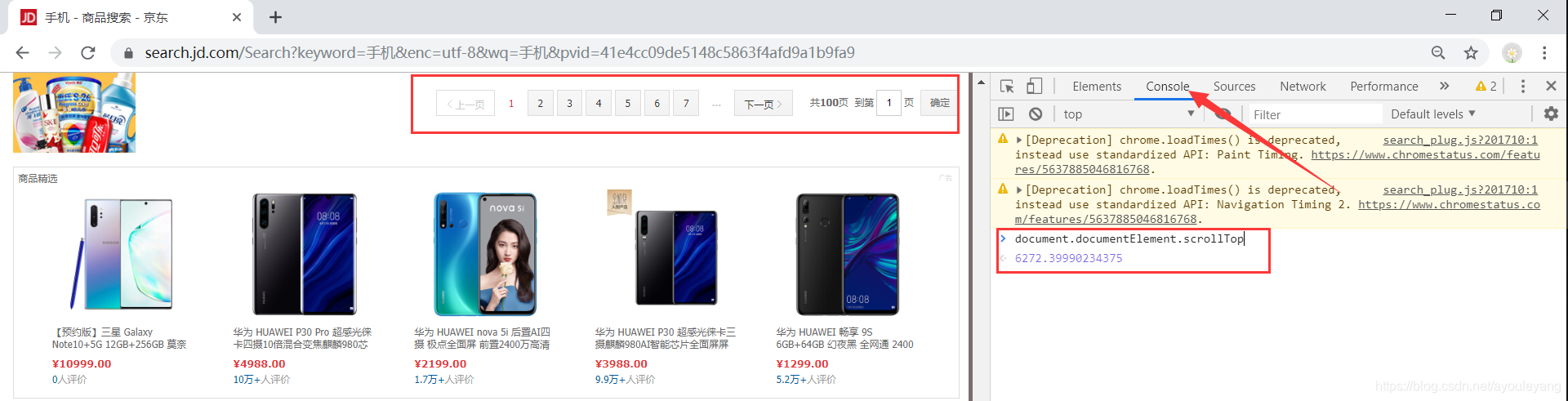
2.2、每次下拉加载的长度不能叠加
如第一次下拉920像素,第二次要大于920,可以在第一次的基础上加920实现,相当于每次都从零算起,10860是它的总像素。
for t in range(920,10860,920):
time.sleep(0.8)#延时,模拟人为加载
js=f"document.documentElement.scrollTop={t}"#下拉加载
driver.execute_script(js)1234三、源代码汇总
from selenium import webdriverfrom selenium.webdriver.common.keys import Keysfrom lxml import etreeimport time
driver = webdriver.Chrome()driver.get('https://www.jd.com/')global endPage#先定义一个全局变量,并附初始值为0endPage = 0global p
p=1def jd_open(keys): #输入商品
search = driver.find_element_by_xpath('//*[@id="key"]')#找到搜索框
search.send_keys(keys)#获取输入的商品
time.sleep(1)
search.send_keys(Keys.ENTER)#回车
time.sleep(3)
max_page = driver.find_element_by_xpath('//*[@id="J_bottomPage"]/span[2]/em[1]/b').text#找到当前商品的最大页数
print ("你查询的当前商品共%s页"%max_page)
global endPage#声明作为全局变量使用
endPage = int(input("请输入你要获取到的页数:"))
page_down()
def page_down():
#模拟下拉,因为京东网的数据是通过下来加载的
for t in range(920,10860,920):#第一次下拉920像素,第二次要大于920,相当于从零算起,10860是它的总像素
time.sleep(0.8)#延时,模拟人为加载
js=f"document.documentElement.scrollTop={t}"#下拉加载
driver.execute_script(js)
source = driver.page_source#获取源网页代码
spider(source)#传值给spiderdef spider(html):#爬虫函数,html接收source
html = etree.HTML(html)#解析源网页
for et in html.xpath('//*[@id="J_goodsList"]/ul/li'):
name = et.xpath('./div/div[4]/a/em/text()[1]')#获取名称
price = et.xpath('./div/div[3]/strong/i/text()')#获取价格
marker = et.xpath('./div/div[5]/strong/a/text()')#评价人数
store = et.xpath('./div/div[7]/span/a/text()')#获取商店
print (name,price,marker,store,'\n')
global endPage#声明要使用上面的全局变量
global p while p < endPage:#商品页面太多,有必要选取爬取
p = p + 1
print ("正在获取第%s页"%p)
next_page()
print ("京东商城 前%s页数据获取完毕!"%endPage)
def next_page():
driver.find_element_by_xpath('//*[@id="J_bottomPage"]/span[1]/a[9]').click()#获取下一页按钮并点击
page_down()if __name__=='__main__':
keys = input("请输入商品:")
jd_open(keys)12345678910111213141516171819202122232425262728293031323334353637383940414243444546474849505152535455565758运行结果:

作者:阿优乐扬
链接:https://blog.csdn.net/ayouleyang/article/details/99711640
来源:CSDN
著作权归作者所有,转载请联系作者获得授权,切勿私自转载。
{var%20f='http://v.t.sina.com.cn/share/share.php?appkey=1515056452',u=z||d.location,p=['&url=',e(u),'&title=',e(t||d.title),'&source=',e(r),'&sourceUrl=',e(l),'&content=',c||'gb2312','&pic=',e(p||'')].join('');function%20a(){if(!window.open([f,p].join(''),'mb',['toolbar=0,status=0,resizable=1,width=440,height=430,left=',(s.width-440)/2,',top=',(s.height-430)/2].join('')))u.href=[f,p].join('');};if(/Firefox/.test(navigator.userAgent))setTimeout(a,0);else%20a();})(screen,document,encodeURIComponent,'','','http://www.shouhuola.com/static/css/dist/css/images/default.jpg', '推荐 野的像风 的文章《selenium+lxml爬取京东商品信息》','http://www.shouhuola.com/article-52311.html','页面编码gb2312|utf-8默认gb2312'));){kind=link}