装hive 解压hive到指定的目录中,一般解压在/usr/local/hivetar -zxvf hive-xxx.tar.gz11配置系统环境 配置hive-env.sh的环境 配置hadoop的家目录,配置hive的家目录,已及配置hive配置文件的目录配置hive-site.xmlhive.metastore.localtruejavax.jdo.option.ConnectionURLjdbc:mysql://192.168.1.3:3306/hivejavax.jdo.option.ConnectionDriverNamecom.mysql.jdbc.Driverjavax.jdo.option.ConnectionUserNamerootjavax.jdo.option.ConnectionPasswordmysql123456789101112131415161718192021222324252627282930注意,我用的是windows下的mysql,还有,将mysql的驱动jar包放在hive的lib下启动hive,启动之前必须初始化数据库:我初始化的是mysql数据库./schemaTool --initSchema --dbType mysql11启动hive./hive11HDFS上面也有建好的数据表启动spark,启动之前将mysql的驱动包,加入到spark的lib下启动spark-shell建表:HDFS上面也有spark建好的数据表注意: 1.需要把配置好的hive-site.xml文件copy到spark的安装目录的conf下。 2.在spark的conf下的spark-env.sh中添加hive配置:Spark整合hive完毕
{var%20f='http://v.t.sina.com.cn/share/share.php?appkey=1515056452',u=z||d.location,p=['&url=',e(u),'&title=',e(t||d.title),'&source=',e(r),'&sourceUrl=',e(l),'&content=',c||'gb2312','&pic=',e(p||'')].join('');function%20a(){if(!window.open([f,p].join(''),'mb',['toolbar=0,status=0,resizable=1,width=440,height=430,left=',(s.width-440)/2,',top=',(s.height-430)/2].join('')))u.href=[f,p].join('');};if(/Firefox/.test(navigator.userAgent))setTimeout(a,0);else%20a();})(screen,document,encodeURIComponent,'','','/static/images/logo.png', '推荐 十一郎 的问题《spark和hive是怎么整合的?》','http://www.shouhuola.com/answer/28473/59381.html','页面编码gb2312|utf-8默认gb2312'));){kind=link}
装hive
解压hive到指定的目录中,一般解压在/usr/local/hive
1
配置系统环境
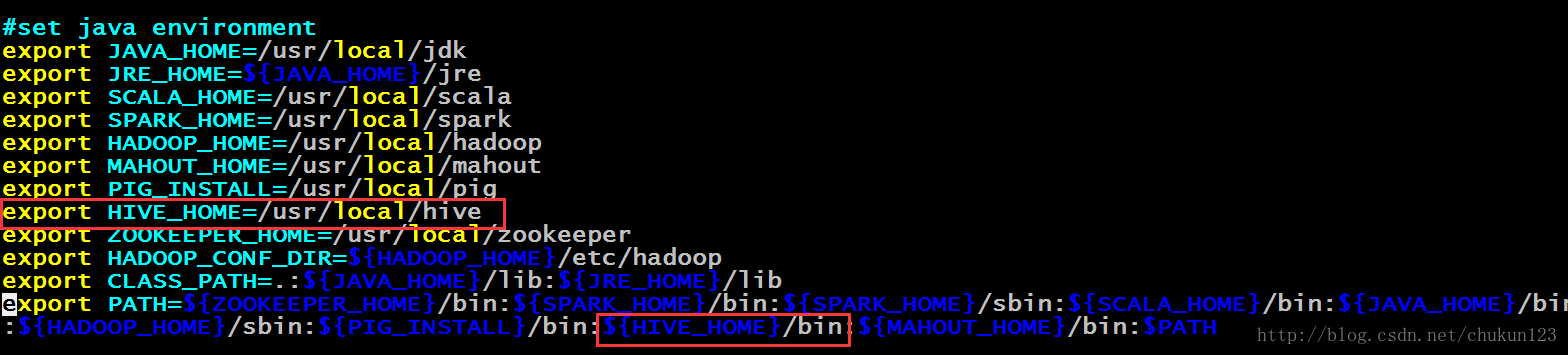
配置hive-env.sh的环境
配置hadoop的家目录,配置hive的家目录,已及配置hive配置文件的目录
配置hive-site.xml
注意,我用的是windows下的mysql,还有,将mysql的驱动jar包放在hive的lib下
启动hive,启动之前必须初始化数据库:我初始化的是mysql数据库
1
启动hive
1
HDFS上面也有建好的数据表
启动spark,启动之前将mysql的驱动包,加入到spark的lib下
启动spark-shell
建表:
HDFS上面也有spark建好的数据表
注意:
1.需要把配置好的hive-site.xml文件copy到spark的安装目录的conf下。
2.在spark的conf下的spark-env.sh中添加hive配置:
Spark整合hive完毕
一周热门 更多>