2020-08-27 09:36发布
flink算子的数据传输 2种形式
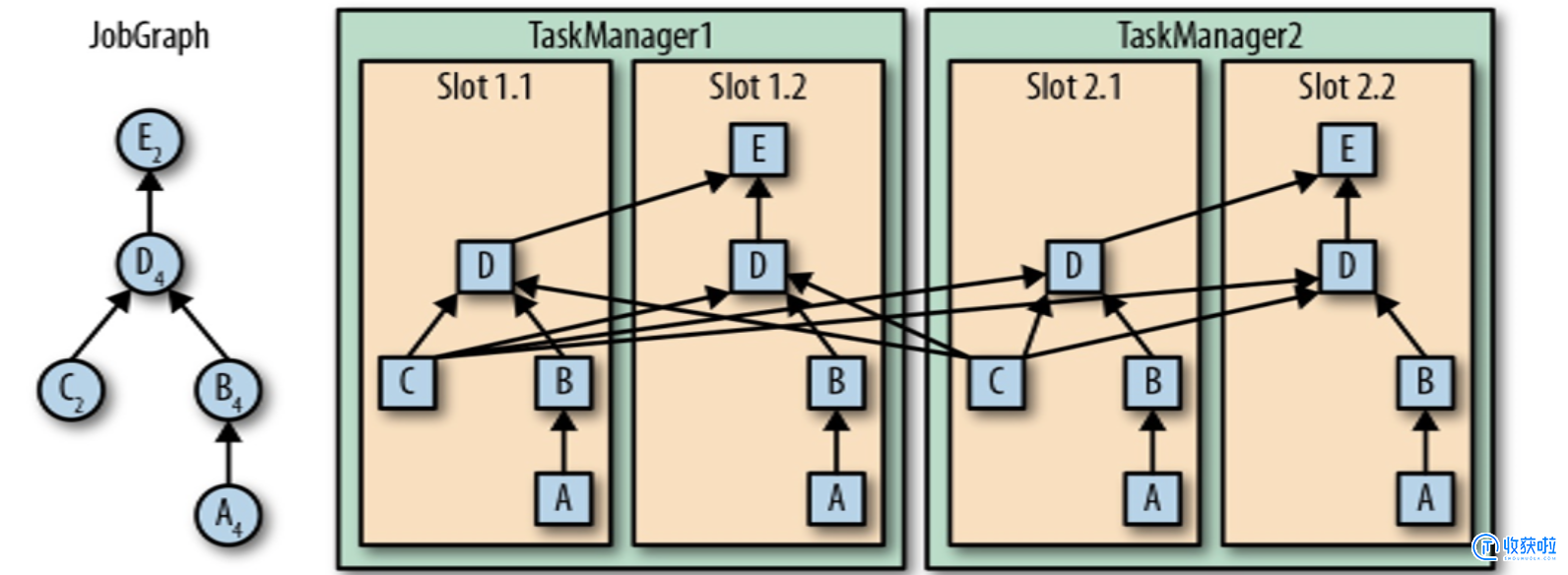
算子之间传输数据的形式可以是one-to-one (forwarding)的模式也可以是redistributing的模式,具体是哪一种形式,取决于算子的种类。
one-to-one (forwarding)
redistributing
One-to-one: Stream(比如在 source 和 map operator 之间)维护着分区以及元素的顺序。那意味着 map 算子的子任务看到的元素的个数以及顺序跟 source 算子的子任务生产的元素的个数、顺序相同,map、fliter、flatMap 等算子都是 one-to-one 的对应关系(类似于 spark 中的窄依赖)。
One-to-one:
(类似于 spark 中的窄依赖)
Redistributing: Stream(map()跟 keyBy/window 之间或者 keyBy/window 跟 sink 之间)的分区会发生改变。每一个算子的子任务依据所选择的 transformation 发送数据到不同的目标任务。例如,keyBy() 基于 hashCode 重分区、broadcast 和 rebalance 会随机重新分区,这些算子都会引起 redistribute 过程,而 redistribute 过程就类似于Spark 中的 shuffle 过程(类似于Spark 中的宽依赖)。
Redistributing:
(类似于Spark 中的宽依赖)
相同并行度的 one to one 操作, Flink 这样相连的算子链接在一起形成一个 task,原来的算子成为里面的一部分。将算子链接成 task 是非常有效的优化:它能减少线程之间的切换和基于缓存区的数据交换,在减少时延的同时提升吞吐量。
最多设置5个标签!
{var%20f='http://v.t.sina.com.cn/share/share.php?appkey=1515056452',u=z||d.location,p=['&url=',e(u),'&title=',e(t||d.title),'&source=',e(r),'&sourceUrl=',e(l),'&content=',c||'gb2312','&pic=',e(p||'')].join('');function%20a(){if(!window.open([f,p].join(''),'mb',['toolbar=0,status=0,resizable=1,width=440,height=430,left=',(s.width-440)/2,',top=',(s.height-430)/2].join('')))u.href=[f,p].join('');};if(/Firefox/.test(navigator.userAgent))setTimeout(a,0);else%20a();})(screen,document,encodeURIComponent,'','','/static/images/logo.png', '推荐 十一郎 的问题《flink算子的数据传输 2种形式》','http://www.shouhuola.com/answer/28215/135138.html','页面编码gb2312|utf-8默认gb2312'));){kind=link}
算子之间传输数据的形式可以是
one-to-one (forwarding)的模式也可以是redistributing的模式,具体是哪一种形式,取决于算子的种类。One-to-one:Stream(比如在 source 和 map operator 之间)维护着分区以及元素的顺序。那意味着 map 算子的子任务看到的元素的个数以及顺序跟 source 算子的子任务生产的元素的个数、顺序相同,map、fliter、flatMap 等算子都是 one-to-one 的对应关系(类似于 spark 中的窄依赖)。Redistributing:Stream(map()跟 keyBy/window 之间或者 keyBy/window 跟 sink 之间)的分区会发生改变。每一个算子的子任务依据所选择的 transformation 发送数据到不同的目标任务。例如,keyBy() 基于 hashCode 重分区、broadcast 和 rebalance 会随机重新分区,这些算子都会引起 redistribute 过程,而 redistribute 过程就类似于Spark 中的 shuffle 过程(类似于Spark 中的宽依赖)。相同并行度的 one to one 操作, Flink 这样相连的算子链接在一起形成一个 task,原来的算子成为里面的一部分。将算子链接成 task 是非常有效的优化:它能减少线程之间的切换和基于缓存区的数据交换,在减少时延的同时提升吞吐量。
一周热门 更多>