the output elements are distributed evenly to a subset of instances of the next operation in a round-robin fashion. The subset of downstream operations to which the upstream operation sends elements depends on the degree of parallelism of both the upstream and downstream operation. For example, if the upstream operation has parallelism 2 and the downstream operation has parallelism 4, then one upstream operation would distribute elements to two downstream operations while the other upstream operation would distribute to the other two downstream operations. If, on the other hand, the downstream operation has parallelism 2 while the upstream operation has parallelism 4 then two upstream operations will distribute to one downstream operation while the other two upstream operations will distribute to the other downstream operations. In cases where the different parallelisms are not multiples of each other one or several downstream operations will have a differing number of inputs from upstream operations.
the output values all go to the first instance of the next processing operator. Use this setting with care since it might cause a serious performance bottleneck in the application.
所有上游算子往下游算子的第一个并发发送
可能存在严重的性能问题,一般不用
适用于
所有结果汇总
global
broadcast
the output elements are broadcast to every parallel instance of the next operation.
CREATE TABLE IF NOT EXISTS `runoob_tbl`(
`runoob_id` INT UNSIGNED AUTO_INCREMENT,
`runoob_title` VARCHAR(100) NOT NULL,
`runoob_author` VARCHAR(40) NOT NULL,
`submission_date` DATE,
PRI...
添加语句 INSERT插入语句:INSERT INTO 表名 VALUES (‘xx’,‘xx’)不指定插入的列INSERT INTO table_name VALUES (值1, 值2,…)指定插入的列INSERT INTO table_name (列1, 列2,…) VALUES (值1, 值2,…)查询插入语句: INSERT INTO 插入表 SELECT * FROM 查...
{var%20f='http://v.t.sina.com.cn/share/share.php?appkey=1515056452',u=z||d.location,p=['&url=',e(u),'&title=',e(t||d.title),'&source=',e(r),'&sourceUrl=',e(l),'&content=',c||'gb2312','&pic=',e(p||'')].join('');function%20a(){if(!window.open([f,p].join(''),'mb',['toolbar=0,status=0,resizable=1,width=440,height=430,left=',(s.width-440)/2,',top=',(s.height-430)/2].join('')))u.href=[f,p].join('');};if(/Firefox/.test(navigator.userAgent))setTimeout(a,0);else%20a();})(screen,document,encodeURIComponent,'','','/static/images/logo.png', '推荐 十一郎 的问题《flink算子的数据传输 2种形式》','http://www.shouhuola.com/q-28215.html','页面编码gb2312|utf-8默认gb2312'));){kind=link}
具体讲一下flink中的数据传输:
在一个运行的application中,它的tasks在持续交换数据。TaskManager负责做数据传输。TaskManager的网络组件首先从缓冲buffer中收集records,然后再发送。也就是说,records并不是一个接一个的发送,而是先放入缓冲,然后再以batch的形式发送。这个技术可以高效使用网络资源,并达到高吞吐。类似于网络或磁盘 I/O 协议中使用的缓冲技术。
这里需要注意的是:传输缓冲buffer中的记录,隐含表示的是,Flink的处理模型是基于微批处理的。
每个TaskManager有一组网络缓冲池(默认每个buffer是32KB),用于发送与接受数据。如发送端和接收端位于不同的TaskManager进程中,则它们需要通过操作系统的网络栈进行交流。流应用需要以管道的模式进行数据交换,也就是说,每对TaskManager会维持一个永久的TCP连接用于做数据交换。在shuffle连接模式下(多个sender与多个receiver),每个sender task需要向每个receiver task,此时TaskManager需要为每个receiver task都分配一个缓冲区。下图展示了此架构:
在上图中,有四个sender 任务,对于每个sender,都需要有至少四个network buffer用于向每个receiver发送数据。每个receiver都需要有至少四个buffer用于接收数据。TaskManager之间的buffer以多路复用的方式使用同一网络连接。为了提供平滑的数据管道型的数据交换,一个TaskManager必须能提供足够的缓冲,以服务所有并行的出入连接。对于shuffle或broadcast 连接,每个发送任务和每个接受任务之间都需要一个buffer。Flink的默认网络缓冲配置足够适用与小型与中型的集群任务。对于大型的集群任务,需要对此配置进行调优。
若sender与receiver任务都运行在同一个TaskManager进程,则sender任务会将发送的条目做序列化,并存入一个字节缓冲。然后将缓冲放入一个队列,直到队列被填满。Receiver任务从队列中获取缓冲,并反序列化输入的条目。所以,在同一个TaskManager内,任务之间的数据传输并不经过网络交互。
Flink采用了不同的技术用于减少tasks之间的沟通成本。在接下来的部分中,我们会讨论基于积分的(credit-based )流控制与任务链(task chaining)。
DataStream上游算子向下游算子发送数据的不同方式:
forward (默认)
the output elements are forwarded to the local subtask of the next operation.
上游算子某个并发直接将数据发给同一个slot中的下游算子的并发,
适用于
上下游算子并发度一致
数据没有倾斜
forward
rebalance
the output elements are distributed evenly to instances of the next operation in a round-robin fashion.
按照round-robin的方式,决定上游算子的某个并发的数据发往下游的哪个并发。该方法可以保证从上游算子到下游算子的数据是绝对均匀发送的。但是不同并发之间的数据交互存在网络传输开销。
适用于
上下游算子并发度不一致
存在数据倾斜
rebalance
shuffle
the output elements are shuffled uniformly randomly to the next operation.
按照均匀分布的随机数,决定上游算子的某个并发的数据发往下游的哪个并发。该方法与rebalance类似,但是会增加随机数生成的开销。并且因为是随机的,最后结果未必是百分百均匀的,但是概率上是均匀分布的。但是不同并发之间的数据交互存在网络传输开销。
适用于
上下游算子并发度不一致
存在数据倾斜
shuffle
rescale
the output elements are distributed evenly to a subset of instances of the next operation in a round-robin fashion.
The subset of downstream operations to which the upstream operation sends
elements depends on the degree of parallelism of both the upstream and downstream operation.
For example, if the upstream operation has parallelism 2 and the downstream operation has parallelism 4, then one upstream operation would distribute elements to two downstream operations while the other upstream operation would distribute to the other two downstream operations. If, on the other hand, the downstream operation has parallelism 2 while the upstream operation has parallelism 4 then two upstream operations will distribute to one downstream operation while the other two upstream operations will distribute to the other downstream operations.
In cases where the different parallelisms are not multiples of each other one or several downstream operations will have a differing number of inputs from upstream operations.
按照分组round-robin的方式,决定上游算子的某个并发的数据发往下游的哪个并发。比如上游算子2并发度,下游4并发度,则每1个上游算子以round robin的方式发送到下游的2个算子;反过来上游算子4并发度,下游2并发度,则2个上游算子的并发度发送到1个下游段子的并发度。如果上下游算子的并发度不成倍数关系,则有几个下游算子的并发的入度可能与其他的并发不同。相比rebalance的好处是:只有部分并发节点之间存在数据传输的开销;坏处是不能很好地解决数据倾斜的问题。
适用于
上下游算子并发度不一致(最好是整数倍)
rescale
global
the output values all go to the first instance of the next processing operator. Use this setting with care since it might cause a serious performance bottleneck in the application.
所有上游算子往下游算子的第一个并发发送
可能存在严重的性能问题,一般不用
适用于
所有结果汇总
global
broadcast
the output elements are broadcast to every parallel instance of the next operation.
所有上游算子的并发产生的数据往每个下游算子的并发发送一份,也就是每个下游算子的并发得到的数据都是全量的。一般要结合BroadcastState来使用,常用于控制流的广播
适用于
控制数据流的广播
broadcast
keyby
uses the provided key with explicit type information for partitioning its operator states.
每个上游算子的并发产生的数据中抽取key,对key进行hash后发送给对应的下游算子的并发,可以保证同一个key的数据必然发送到同一个下游算子的并发上。但是同一个下游算子可能用于处理多个不同的key,但是这些处理都是分开的
适用于
需要按照key来处理的数据。需要注意,选取key时,要尽量选取能使得数据分散的字段,比如ip、timestamp等等,不要选取如sex等区分数较少的字段
算子之间传输数据的形式可以是one-to-one (forwarding)的模式也可以是redistributing 的模式,具体是哪一种形式,取决于算子的种类:
①One-to-one:stream维护着分区以及元素的顺序(比如source和map之间)。 这意味着map 算子的子任务看到的元素的个数以及顺序跟source算子的子任务生产的元素的个数、顺序相同。map、fliter、flatMap等算子都是one-to-one的 对应关系。
②Redistributing:stream的分区会发生改变。每一个算子的子任务依据所选择的 transformation发送数据到不同的目标任务。例如keyBy基于hashCode重分区、而 broadcast和rebalance会随机重新分区,这些算子都会引起redistribute过程,而 redistribute 过程就类似于 Spark 中的 shuffle 过程。
算子之间传输数据的形式可以是
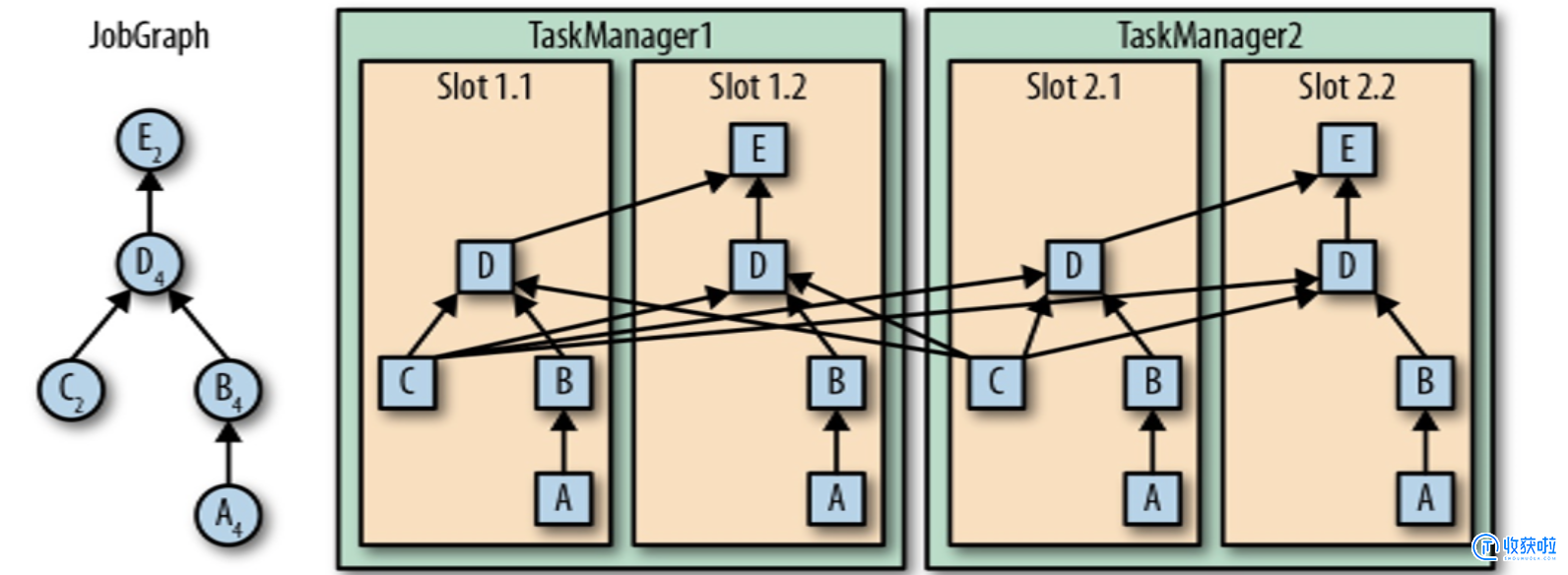
one-to-one (forwarding)的模式也可以是redistributing的模式,具体是哪一种形式,取决于算子的种类。One-to-one:Stream(比如在 source 和 map operator 之间)维护着分区以及元素的顺序。那意味着 map 算子的子任务看到的元素的个数以及顺序跟 source 算子的子任务生产的元素的个数、顺序相同,map、fliter、flatMap 等算子都是 one-to-one 的对应关系(类似于 spark 中的窄依赖)。Redistributing:Stream(map()跟 keyBy/window 之间或者 keyBy/window 跟 sink 之间)的分区会发生改变。每一个算子的子任务依据所选择的 transformation 发送数据到不同的目标任务。例如,keyBy() 基于 hashCode 重分区、broadcast 和 rebalance 会随机重新分区,这些算子都会引起 redistribute 过程,而 redistribute 过程就类似于Spark 中的 shuffle 过程(类似于Spark 中的宽依赖)。相同并行度的 one to one 操作, Flink 这样相连的算子链接在一起形成一个 task,原来的算子成为里面的一部分。将算子链接成 task 是非常有效的优化:它能减少线程之间的切换和基于缓存区的数据交换,在减少时延的同时提升吞吐量。
相关问题推荐
大数据(big data)一词越来越多地被提及,人们用它来描述和定义信息爆炸时代产生的海量数据,而这个海量数据的时代则被称为大数据时代。随着云时代的来临,大数据(Big data)也吸引了越来越多的关注。大数据(Big data)通常用来形容一个公司创造的大量非结...
Java和大数据的关系:Java是计算机的一门编程语言;可以用来做很多工作,大数据开发属于其中一种;大数据属于互联网方向,就像现在建立在大数据基础上的AI方向一样,他两不是一个同类,但是属于包含和被包含的关系;Java可以用来做大数据工作,大数据开发或者...
学完大数据可以从事很多工作,比如说:hadoop 研发工程师、大数据研发工程师、大数据分析工程师、数据库工程师、hadoop运维工程师、大数据运维工程师、java大数据工程师、spark工程师等等都是我们可以从事的工作岗位!不同的岗位,所具备的技术知识也是不一样...
简言之,大数据是指大数据集,这些数据集经过计算分析可以用于揭示某个方面相关的模式和趋势。大数据技术的战略意义不在于掌握庞大的数据信息,而在于对这些含有意义的数据进行专业化处理。大数据的特点:数据量大、数据种类多、 要求实时性强、数据所蕴藏的...
tail -f的时候,发现一个奇怪的现象,首先 我在一个窗口中 tail -f test.txt 然后在另一个窗口中用vim编辑这个文件,增加了几行字符,并保存,这个时候发现第一个窗口中并没有变化,没有将最新的内容显示出来。tail -F,重复上面的实验过程, 发现这次有变化了...
您好针对您的问题,做出以下回答,希望有所帮助!1、大数据行业还是有非常大的人才需求的,对于就业也有不同的岗位可选,比如大数据工程师,大数据运维,大数据架构师,大数据分析师等等,就业难就难在能否找到适合的工作,能否与你的能力和就业预期匹配。2、...
最小的基本单位是Byte应该没多少人不知道吧,下面先按顺序给出所有单位:Byte、KB、MB、GB、TB、PB、EB、ZB、YB、DB、NB,按照进率1024(2的十次方)计算:1Byte = 8 Bit1 KB = 1,024 Bytes 1 MB = 1,024 KB = 1,048,576 Bytes 1 GB = 1,024 MB = 1,048,576...
大数据的定义。大数据,又称巨量资料,指的是所涉及的数据资料量规模巨大到无法通过人脑甚至主流软件工具,在合理时间内达到撷取、管理、处理、并整理成为帮助企业经营决策更积极目的的资讯。大数据是对大量、动态、能持续的数据,通过运用新系统、新工具、新...
MySQL是一种关系型数据库管理系统,关系数据库将数据保存在不同的表中,而不是将所有数据放在一个大仓库内,这样就增加了速度并提高了灵活性。MySQL的版本:针对不同的用户,MySQL分为两种不同的版本:MySQL Community Server社区版本,免费,但是Mysql不提供...
mysql安装需要先使用yum安装mysql数据库的软件包 ;然后启动数据库服务并运行mysql_secure_installation去除安全隐患,最后登录数据库,便可完成安装
1.查看所有数据库showdatabases;2.查看当前使用的数据库selectdatabase();3.查看数据库使用端口showvariableslike'port';4.查看数据库编码showvariableslike‘%char%’;character_set_client 为客户端编码方式; character_set_connection 为建立连接...
CREATE TABLE IF NOT EXISTS `runoob_tbl`( `runoob_id` INT UNSIGNED AUTO_INCREMENT, `runoob_title` VARCHAR(100) NOT NULL, `runoob_author` VARCHAR(40) NOT NULL, `submission_date` DATE, PRI...
学习多久,我觉得看你基础情况。1、如果原来什么语言也没有学过,也没有基础,那我觉得最基础的要先选择一种语言来学习,是VB,C..,pascal,看个人的喜好,一般情况下,选择C语言来学习。2、如果是有过语言的学习,我看应该一个星期差不多,因为语言的理念互通...
添加语句 INSERT插入语句:INSERT INTO 表名 VALUES (‘xx’,‘xx’)不指定插入的列INSERT INTO table_name VALUES (值1, 值2,…)指定插入的列INSERT INTO table_name (列1, 列2,…) VALUES (值1, 值2,…)查询插入语句: INSERT INTO 插入表 SELECT * FROM 查...
看你什么岗位吧。如果是后端,只会CRUD。应该是可以找到实习的,不过公司应该不会太好。如果是数据库开发岗位,那这应该是不会找到的。
查找数据列 SELECT column1, column2, … FROM table_name; SELECT column_name(s) FROM table_name