![]()
![]() 一:Hadoop运行模式
一:Hadoop运行模式
1 )官方网址
( 1 )官方网站:
( 2 )各个版本归档库地址
https://archive.apache.org/dist/hadoop/common/hadoop-2.7.2/
( 3 ) hadoop2.7.2 版本详情介绍
http://hadoop.apache.org/docs/r2.7.2/
2 ) Hadoop 运行模式
( 1)本地模式(默认模式):
不需要启用单独进程,直接可以运行,测试和开发时使用。
(2)伪分布式模式:
等同于完全分布式,只有一个节点,需要启动集群。。
(3)完全分布式模式:基于伪分布式搭建的
多个节点一起运行
![]()
![]() 二:基于hadoop本地模式运行
二:基于hadoop本地模式运行
![]()
![]() 1。基于本地模式运行官方grep案例
1。基于本地模式运行官方grep案例
在前一篇博客的基础上,系统弄装好了hadoop和java.并且可以运行。这里运行的程序都是 hadoop官方自带的已经写好的mapreduce程序,我们直接调用就行了。官方自带了很多MR程序。只是实际开发中,一般都是定制MR程序进行相关的运算。
1 )创建在 hadoop-2.7.2 文件下面创建一个 input 文件夹
[robot @hadoop101 hadoop-2.7.2]$mkdir input
2 )将 hadoop 的 xml 配置文件复制到 input
[robot @hadoop101 hadoop-2.7.2]$cp etc/hadoop/*.xml input
3 )执行 share 目录下的 mapreduce 程序
[ robot @hadoop101 hadoop-2.7.2]$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar grep input output 'dfs[a- z.]+'
4 )查看输出结果
[ robot @hadoop101 hadoop-2.7.2]$ cat output/*
2 本地模式运行官方wordcount案例
1 )创建在 hadoop-2.7.2 文件下面创建一个 wcinput 文件夹
[ robot @hadoop101 hadoop-2.7.2]$mkdir wcinput
2 )在 wcinput 文件下创建一个 wc.input 文件
[ robot @hadoop101 hadoop-2.7.2]$cd wcinput
[ robot @hadoop101 wcinput]$touch wc.input
3 )编辑 wc.input 文件
[robot @hadoop101 wcinput]$vim wc.input 在文件中输入如下内容 hadoop yarn hadoop mapreduce robot robot 保存退出:: wq |
4 )回到 hadoop 目录 /opt/module/hadoop-2.7.2
5 )执行程序:
[ robot @hadoop101 hadoop-2.7.2]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount wcinput wcoutput
6 )查看结果:
[ robot @hadoop101 hadoop-2.7.2]$cat wcoutput/part-r-00000
robot 2
hadoop 2
mapreduce 1
yarn 1
三:搭建伪分布式hadoop集群并且调试运行
伪分布式运行 Hadoop 案例
![]()
![]() 3.1 HDFS上运行MapReduce程序
3.1 HDFS上运行MapReduce程序
1 )分析:
( 1 )准备 1 台客户机
( 2 )安装 jdk
( 3 )配置环境变量
( 4 )安装 hadoop
( 5 )配置环境变量
( 6 )配置集群
( 7 )启动、测试集群增、删、查
( 8 )在 HDFS 上执行 wordcount 案例
2 )执行步骤
需要配置 hadoop 文件如下
( 1 )配置集群
( a )配置: hadoop-env.sh
Linux 系统中获取 jdk 的安装路径:
[root@ hadoop101 ~]# echo $JAVA_HOME
/opt/module/jdk1.7.0_79
修改 JAVA_HOME 路径:
export JAVA_HOME=/opt/module/jdk1.7.0_79 |
( b )配置: core-site.xml
<!-- 指定 HDFS 中 NameNode 的地址 --> <property> <name>fs.defaultFS</name> <value>hdfs:// hadoop101 :9000</value> </property> <!-- 指定 hadoop 运行时产生文件的存储目录 --> <property> <name>hadoop.tmp.dir</name> <value>/opt/module/hadoop-2.7.2/data/tmp</value> </property> |
( c )配置: hdfs-site.xml
<!-- 指定 HDFS 副本的数量,只有一台机器,所以副本数只能设置成1 --> <property> <name>dfs.replication</name> <value>1</value> </property> |
( 2 )启动集群
( a )格式化 namenode (第一次启动时格式化,以后就不要总格式化)
bin/hdfs namenode -format
( b )启动 namenode
sbin/hadoop-daemon.sh start namenode
( c )启动 datanode
sbin/hadoop-daemon.sh start datanode
( 3 )查看集群
( a )查看是否启动成功
[root@hadoop101 ~]# jps
13586 NameNode
13668 DataNode
13786 Jps
( b )查看产生的 log 日志
当前目录: /opt/module/hadoop-2.7.2/logs
[root@hadoop101 logs]# ls
hadoop-root-datanode-hadoop. robot .com.log
hadoop-root-datanode-hadoop. robot .com.out
hadoop-root-namenode-hadoop. robot .com.log
hadoop-root-namenode-hadoop. robot .com.out
SecurityAuth-root.audit
[root@hadoop101 logs]# cat hadoop-root-datanode-hadoop. robot .com.log
( c ) web 端查看 HDFS 文件系统
http://192.168.1.101:50070/dfshealth.html#tab-overview
注意:如果不能查看,看如下帖子处理
http://www.cnblogs.com/zlslch/p/6604189.html
( 4 )操作集群
( a )在 hdfs 文件系统上 创建 一个 input 文件夹
[ robot @hadoop101 hadoop-2.7.2]$ bin/hdfs dfs -mkdir -p /user/ robot /mapreduce/wordcount/input
( b )将测试文件内容 上传 到文件系统上
bin/hdfs dfs -put wcinput/wc.input /user/ robot /mapreduce/wordcount/input/
( c ) 查看 上传的文件是否正确
bin/hdfs dfs -ls /user/ robot /mapreduce/wordcount/input/
bin/hdfs dfs -cat /user/ robot /mapreduce/wordcount/input/wc.input
( d )在 Hdfs 上运行 mapreduce 程序
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount /user/robot /mapreduce/wordcount/input/ /user/robot /mapreduce/wordcount/output
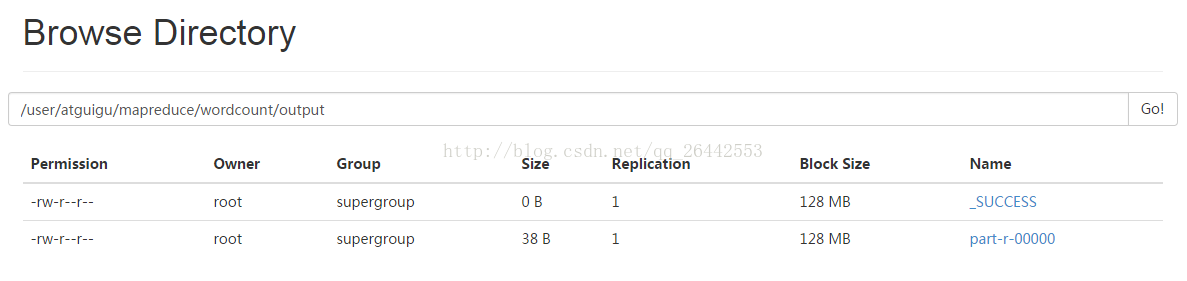
( e )查看输出结果
命令行查看:
bin/hdfs dfs -cat /user/ robot /mapreduce/wordcount/output/*
浏览器查看
{var%20f='http://v.t.sina.com.cn/share/share.php?appkey=1515056452',u=z||d.location,p=['&url=',e(u),'&title=',e(t||d.title),'&source=',e(r),'&sourceUrl=',e(l),'&content=',c||'gb2312','&pic=',e(p||'')].join('');function%20a(){if(!window.open([f,p].join(''),'mb',['toolbar=0,status=0,resizable=1,width=440,height=430,left=',(s.width-440)/2,',top=',(s.height-430)/2].join('')))u.href=[f,p].join('');};if(/Firefox/.test(navigator.userAgent))setTimeout(a,0);else%20a();})(screen,document,encodeURIComponent,'','','http://www.shouhuola.com/static/css/dist/css/images/default.jpg', '推荐 上瘾入骨i 的文章《hadoop完全分布式集群搭建全部流程之二:伪分布式搭建》','http://www.shouhuola.com/article-1761.html','页面编码gb2312|utf-8默认gb2312'));){kind=link}
( f )将测试文件内容 下载 到本地
hadoop fs -get /user/ robot /mapreduce/wordcount/output/part-r-00000 ./wcoutput/
( g ) 删除 输出结果
hdfs dfs -rmr /user/ robot /mapreduce/wordcount/output
总的来说伪分布只是为了测试使用,熟悉一下hadoop。实际开发测试中还是完全分布式的使用,下面继续完全分布式的搭建。
作者:
链接:https://blog.csdn.net/qq_26442553/article/details/78695175
来源:CSDN
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。