#余弦相似度算法def CosSimilarity(UL,p1,p2):si = GetSameItem(UL,p1,p2)n = len(si)if n == 0: return 0s = sum([UL[p1][item]*UL[p2][item] for item in si])den1 = math.sqrt(sum([pow(UL[p1][item],2) for item in si]))den2 = math.sqrt(sum([pow(UL[p2][itme],2) for item in si]))return s/(den1*den2)
{var%20f='http://v.t.sina.com.cn/share/share.php?appkey=1515056452',u=z||d.location,p=['&url=',e(u),'&title=',e(t||d.title),'&source=',e(r),'&sourceUrl=',e(l),'&content=',c||'gb2312','&pic=',e(p||'')].join('');function%20a(){if(!window.open([f,p].join(''),'mb',['toolbar=0,status=0,resizable=1,width=440,height=430,left=',(s.width-440)/2,',top=',(s.height-430)/2].join('')))u.href=[f,p].join('');};if(/Firefox/.test(navigator.userAgent))setTimeout(a,0);else%20a();})(screen,document,encodeURIComponent,'','','/static/images/logo.png', '推荐 德胜李君 的问题《能说说余弦相似度算法吗?》','http://www.shouhuola.com/q-12478.html','页面编码gb2312|utf-8默认gb2312'));){kind=link}
余弦距离,也称为余弦相似度,是用向量空间中两个向量夹角的余弦值作为衡量两个个体间差异的大小的度量。
余弦值越接近1,就表明夹角越接近0度,也就是两个向量越相似,这就叫"余弦相似性"。
上图两个向量a,b的夹角很小可以说a向量和b向量有很高的的相似性,极端情况下,a和b向量完全重合。如下图:
如上图二:可以认为a和b向量是相等的,也即a,b向量代表的文本是完全相似的,或者说是相等的。如果a和b向量夹角较大,或者反方向。如下图
如上图三: 两个向量a,b的夹角很大可以说a向量和b向量有很低的的相似性,或者说a和b向量代表的文本基本不相似。那么是否可以用两个向量的夹角大小的函数值来计算个体的相似度呢?
向量空间余弦相似度理论就是基于上述来计算个体相似度的一种方法。下面做详细的推理过程分析。
想到余弦公式,最基本计算方法就是初中的最简单的计算公式,计算夹角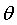
的余弦定值公式为:
但是这个是只适用于直角三角形的,而在非直角三角形中,余弦定理的公式是
三角形中边a和b的夹角 的余弦计算公式为:
公式(2)
在向量表示的三角形中,假设a向量是(x1, y1),b向量是(x2, y2),那么可以将余弦定理改写成下面的形式:
向量a和向量b的夹角 的余弦计算如下
扩展,如果向量a和b不是二维而是n维,上述余弦的计算法仍然正确。假定a和b是两个n维向量,a是 ,b是 ,则a与b的夹角 的余弦等于:
余弦值越接近1,就表明夹角越接近0度,也就是两个向量越相似,夹角等于0,即两个向量相等,这就叫"余弦相似性"。
另外:余弦距离使用两个向量夹角的余弦值作为衡量两个个体间差异的大小。相比欧氏距离,余弦距离更加注重两个向量在方向上的差异。
借助三维坐标系来看下欧氏距离和余弦距离的区别:
从上图可以看出,欧氏距离衡量的是空间各点的绝对距离,跟各个点所在的位置坐标直接相关;而余弦距离衡量的是空间向量的夹角,更加体现在方向上的差异,而不是位置。如果保持A点位置不变,B点朝原方向远离坐标轴原点,那么这个时候余弦距离 是保持不变的(因为夹角没有发生变化),而A、B两点的距离显然在发生改变,这就是欧氏距离和余弦距离之间的不同之处。
是保持不变的(因为夹角没有发生变化),而A、B两点的距离显然在发生改变,这就是欧氏距离和余弦距离之间的不同之处。
欧氏距离和余弦距离各自有不同的计算方式和衡量特征,因此它们适用于不同的数据分析模型:
欧氏距离能够体现个体数值特征的绝对差异,所以更多的用于需要从维度的数值大小中体现差异的分析,如使用用户行为指标分析用户价值的相似度或差异。
余弦距离更多的是从方向上区分差异,而对绝对的数值不敏感,更多的用于使用用户对内容评分来区分兴趣的相似度和差异,同时修正了用户间可能存在的度量标准不统一的问题(因为余弦距离对绝对数值不敏感)。
正因为余弦相似度在数值上的不敏感,会导致这样一种情况存在:
用户对内容评分,按5分制,X和Y两个用户对两个内容的评分分别为(1,2)和(4,5),使用余弦相似度得到的结果是0.98,两者极为相似。但从评分上看X似乎不喜欢2这个 内容,而Y则比较喜欢,余弦相似度对数值的不敏感导致了结果的误差,需要修正这种不合理性就出现了调整余弦相似度,即所有维度上的数值都减去一个均值,比如X和Y的评分均值都是3,那么调整后为(-2,-1)和(1,2),再用余弦相似度计算,得到-0.8,相似度为负值并且差异不小,但显然更加符合现实。
那么是否可以在(用户-商品-行为数值)矩阵的基础上使用调整余弦相似度计算呢?从算法原理分析,复杂度虽然增加了,但是应该比普通余弦夹角算法要强。
【下面举一个例子,来说明余弦计算文本相似度】
举一个例子来说明,用上述理论计算文本的相似性。为了简单起见,先从句子着手。
句子A:这只皮靴号码大了。那只号码合适
句子B:这只皮靴号码不小,那只更合适
怎样计算上面两句话的相似程度?
基本思路是:如果这两句话的用词越相似,它们的内容就应该越相似。因此,可以从词频入手,计算它们的相似程度。
第一步,分词。
句子A:这只/皮靴/号码/大了。那只/号码/合适。
句子B:这只/皮靴/号码/不/小,那只/更/合适。
第二步,列出所有的词。
这只,皮靴,号码,大了。那只,合适,不,小,很
第三步,计算词频。
句子A:这只1,皮靴1,号码2,大了1。那只1,合适1,不0,小0,更0
句子B:这只1,皮靴1,号码1,大了0。那只1,合适1,不1,小1,更1
第四步,写出词频向量。
句子A:(1,1,2,1,1,1,0,0,0)
句子B:(1,1,1,0,1,1,1,1,1)
到这里,问题就变成了如何计算这两个向量的相似程度。我们可以把它们想象成空间中的两条线段,都是从原点([0, 0, ...])出发,指向不同的方向。两条线段之间形成一个夹角,如果夹角为0度,意味着方向相同、线段重合,这是表示两个向量代表的文本完全相等;如果夹角为90度,意味着形成直角,方向完全不相似;如果夹角为180度,意味着方向正好相反。因此,我们可以通过夹角的大小,来判断向量的相似程度。夹角越小,就代表越相似。
使用上面的公式(4)
计算两个句子向量
句子A:(1,1,2,1,1,1,0,0,0)
和句子B:(1,1,1,0,1,1,1,1,1)的向量余弦值来确定两个句子的相似度。
计算过程如下:
计算结果中夹角的余弦值为0.81非常接近于1,所以,上面的句子A和句子B是基本相似的
由此,我们就得到了文本相似度计算的处理流程是:
(1)找出两篇文章的关键词;
(2)每篇文章各取出若干个关键词,合并成一个集合,计算每篇文章对于这个集合中的词的词频
(3)生成两篇文章各自的词频向量;
(4)计算两个向量的余弦相似度,值越大就表示越相似。
代码实现如下:
相关问题推荐
在互联网逐渐步入大数据时代后,不可避免的为企业及消费者行为带来一系列改变与重塑。其中最大的变化莫过于,消费者的一切行为在企业面前似乎都将是可视化的。随着大数据技术的深入研究与应用,企业的专注点日益聚焦于怎样利用大数据来为精准营销服务,进而深...
这跟年限关系并不代表,主要看技术能力,工作10年技术不行,薪资一样相对较低,毕业一年技术很牛,工资也没有上限,技术可以的话,一线城市薪资能达到5位数
在线上的hadoop集群运维过程中,hadoop 的balance工具通常用于平衡hadoop集群中各datanode中的文件块分布,以避免出现部分datanode磁盘占用率高的问题(这问题也很有可能导致该节点CPU使用率较其他服务器高)。可能的原因:突然磁盘使用率变高而文件块数并没...
其实属于一个领域,先用大数据技术将数据进行采集、存储、计算,然后根据结果利用机器学习搞一些模型、算法进行预测,人工智能建立在这之上
PageRank,即网页排名,又称网页级别、Google左側排名或佩奇排名。 是Google创始人拉里·佩奇和谢尔盖·布林于1997年构建早期的搜索系统原型时提出的链接分析算法,自从Google在商业上获得空前的成功后,该算法也成为其他搜索引擎和学术界十...
是一种空间效率很高的随机数据结构,它利用位数组很简洁地表示一个集合,并能判断一个元素是否属于这个集合
监督学习(supervised learning)从给定的训练数据集中学习出一个函数(模型参数),当新的数据到来时,可以根据这个函数预测结果。监督学习的训练集要求包括输入输出,也可以说是特征和目标。训练集中的目标是由人标注的。监督学习就是最常见的分类(注意和...
分类:是已知类别时,对数据进行按标签进行划分到不同类别中,属于有监督的学习。聚类:是在没有标签的情况下,将相似的数据划分到一个类中,属于无监督的学习。
使用已经建立好的数学模型,进行数据的挖掘机器学习是利用已知的算法来进行模型的训练
很成熟的一个推荐算法使用在推荐些用户喜欢的产品,视屏等方便
机器学习——实现人工智能的一种方式深度学习——一种实现机器学习的技术
机器学习中的神经网络分支包括深度学习。深度学习相对于普通的神经网络的优势在于,可以自动提取特征。将人从以前的手动提取特征的繁琐中解放出来,只需要会一套流程,就可以达到很好的效果。...
机器学习可能会广泛应用到日常生活,但是普及开来学习还有一定的时间,课程难度会有一方面,学习成本也比较大,所以短时间内很普及可能性还是不太大的。
其实这个是两个词的组合,可以拆分为TF和IDF。TF(Term Frequency,缩写为TF)也就是词频啦,即一个词在文中出现的次数,统计出来就是词频TF,显而易见,一个词在文章中出现很多次,那么这个词肯定有着很大的作用,但是我们自己实践的话,肯定会看到你统计出...