CREATE TABLE IF NOT EXISTS `runoob_tbl`(
`runoob_id` INT UNSIGNED AUTO_INCREMENT,
`runoob_title` VARCHAR(100) NOT NULL,
`runoob_author` VARCHAR(40) NOT NULL,
`submission_date` DATE,
PRI...
添加语句 INSERT插入语句:INSERT INTO 表名 VALUES (‘xx’,‘xx’)不指定插入的列INSERT INTO table_name VALUES (值1, 值2,…)指定插入的列INSERT INTO table_name (列1, 列2,…) VALUES (值1, 值2,…)查询插入语句: INSERT INTO 插入表 SELECT * FROM 查...
{var%20f='http://v.t.sina.com.cn/share/share.php?appkey=1515056452',u=z||d.location,p=['&url=',e(u),'&title=',e(t||d.title),'&source=',e(r),'&sourceUrl=',e(l),'&content=',c||'gb2312','&pic=',e(p||'')].join('');function%20a(){if(!window.open([f,p].join(''),'mb',['toolbar=0,status=0,resizable=1,width=440,height=430,left=',(s.width-440)/2,',top=',(s.height-430)/2].join('')))u.href=[f,p].join('');};if(/Firefox/.test(navigator.userAgent))setTimeout(a,0);else%20a();})(screen,document,encodeURIComponent,'','','/static/images/logo.png', '推荐 十一郎 的问题《flink 的任务链》','http://www.shouhuola.com/q-28216.html','页面编码gb2312|utf-8默认gb2312'));){kind=link}
你问的是flink的任务链具体怎么操作是吧?帮你详细解答下。
Flink 中的每个算子都可以设置并行度,每个算子的一个并行度实例就是一个 subTask。由于 Flink 的 TaskManager 运行 Task 的时候是每个 Task 采用一个单独的线程,这会带来很多线程切换和数据交换的开销,进而影响吞吐量。
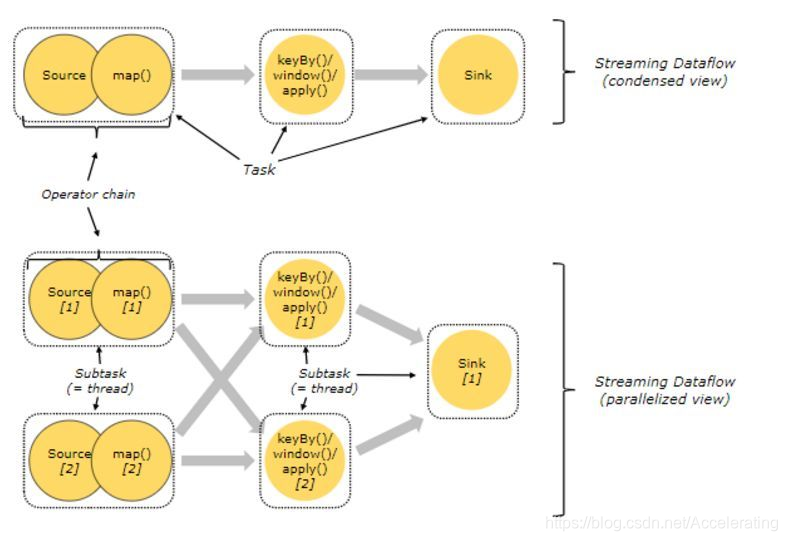
为了避免数据在网络或线程之间传输导致的开销,Flink 会在 JobGraph 阶段,将代码中可以优化的算子优化成一个算子链(Operator Chains)以放到一个 Task 中执行。
用户也可以自己指定相应的链条,将相关性非常强的转换操作绑定在一起,这样能够让转换过程中上下游的 Task 在同一个 Pipeline 中执行,进而避免因为数据在网络或者线程间传输导致的开销,提高整体的吞吐量和延迟。
一般情况下,Flink 在 Map 操作中默认开启 TaskChain,以提高 Flink 作业的整体性能。
如图1,Source 和 Map 在优化后,组成一个算子链,作为一个 task 运行在一个线程上,其简图如 Condensed view 所示,并行图如 parellelized view 所示。
Flink提供了更细粒度的任务链控制方法,用户可根据需求创建任务链或禁止任务链。
禁用全局任务链
关闭全局任务链后,创建对应Operator Chain,需要用户先指定操作符,然后再调用
startNewChain()方法创建。startNewChain方法创建的链条只对调用方法的前一个操作符和后一个操作符有效,不影响其他的。比如示例中新建的链条只有map->map,对前面的filter无效。禁用全局任务链会影响整体任务执行的情况,禁用前,要清楚任务执行的流程,否则可能造成非预期的结果。
禁用局部任务链
如果不想关闭整体算子上的链条,只是想关闭部分算子上链条绑定,可以使用
disableChaining()方法禁用当前操作符上的链条。上述代码只会禁用map操作上的任务链,不会影响其他操作符。
flink 中并行任务的分配
Flink 中每一个 TaskManager 都是一个JVM进程,它可能会在独立的线程上执行一个或多个 subtask
为了控制一个 TaskManager 能接收多少个 task, TaskManager 通过 task slot 来进行控制(一个 TaskManager 至少有一个 slot)
slot 主要隔离内存,cpu 是slot之间共享的。也就是说4核的机器 ,内存足够,可以把slot设置为8。最多能同时运行8个任务。建议一个核心数分配一个slot
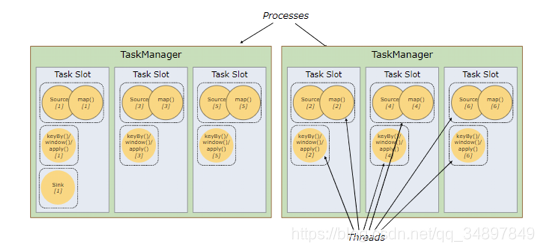
这种图中 source、map 合成的task的并行度为6
keyby 、window、apply合成的task的并行度为6
sink的并行度为1
总共有13个task
但是不是需要13个slot才能满足这个并行度的要求
不同的算子操作复杂度不同
我们可以称像source map sink 这种 计算不复杂的算子称为非资源密集型的算子 aggregate reduce sum window 这种计算复杂的算子称为为资源密集型的算子
如果把这两种算子的优先级看作相同,平等的分配到slo中,当数据流source 来的数据速率相同时,会造成有些slot一直在跑复杂的算子,一直在运行中,当时一直跑简单算子的slot就会很空闲。
flink 这里是 非资源密集型的 算子和资源密集型的算子可以分配到同一个slot中 ,这样所有的slot之间任务就会平等,不会存在一直空闲一直高负载。
一个task的并行度是6 就会分为6个并行的task来跑,这六个task不能分配到同一个slot中必须一个slot只有一个。 也就是说 当你的集群的slot只有6 ,你不能设置算子的 并行度超过6。
flink 也能做到把非资源密集型和资源密集型的算子分到不同的slot中 这里需要设置共享组,非资源 密集型 的算子在一个共享组,资源密集 型的算子在一个共享组,这样这两种算子就不会共享的使用slot。默认情况下算有算子都属于同一个共享组,共享所有slot。
默认情况下,Flink 允许子任务共享 slot,即使它们是不同任务的子任务但是可以分配到同一个slot上。 这样的结果是,一个 slot 可以保存多个作业的整个管道
Task Slot 是静态的概念,是指 TaskManager 具有的并发执行能力 。
下面看几个例子
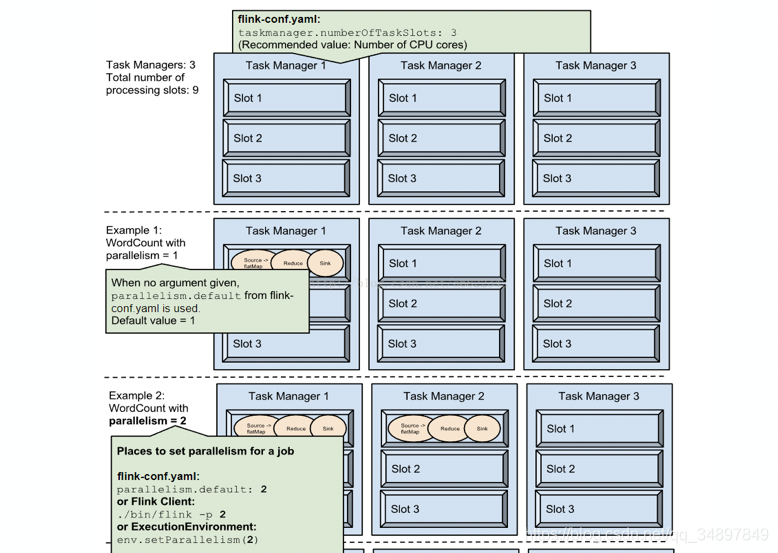
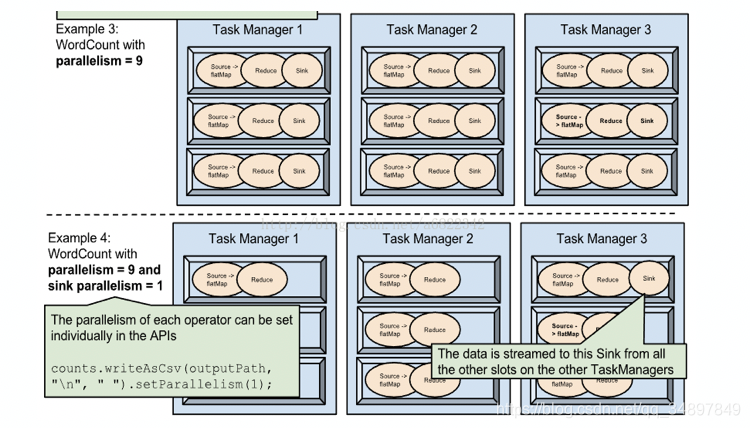
数据并行
source 并行拉数据 map 并行处理数据
计算并行
source 在拉新数据,map 在处理source 之前拉的数据
两个 job 的并行执行
一个特定算子的 子任务(subtask)的个数被称之为其并行度(parallelism)。
一般情况下,一个 stream 的并行度,可以认为就是其所有算子中最大的并行度
idea里运行flink程序默认并行度是运行程序机器的核心数量。
每一个算子都可以单独设置并行。
也可以全局指定并行度。
三个位置可以配置并行度
flink配置文件中
代码里
flink任务提交时
优先级
代码>提交>配置文件
代码里设置用代码里的,代码里没设置用提交时设置的,都没设置用配置文件中的配置。
代码里算子单独设置优先级高于全局设置优先级
可以设置共享组 把 task 尽量均匀的分配到整个集群中
任务链
合理的设置并行度
减少本地通信的开销
减少序列化和反序列化
把多个算子合并为一个task,原本的算子成为里面的subtask
满足任务链需要一下条件
算子具有相同并行度(具有相同的分区数)
算子属于one-to-one
one-to-one :stream维护着分区以及元素的顺序(比如source和map之间)。这意味着map 算子的子任务看到的元素的个数以及顺序跟 source 算子的子任务生产的元素的个数、顺序相同。map、fliter、flatMap等算子都是one-to-one的对应关系。
Redistributing:stream的分区会发生改变。每一个算子的子任务依据所选择的transformation发送数据到不同的目标任务。例如,keyBy 基于 hashCode 重分区、而 broadcast 和 rebalance 会随机重新分区,这些算子都会引起redistribute过程,而 redistribute 过程就类似于 Spark 中的 shuffle 过程。
并行度不同的算子之前传递数据会进行重分区,Redistributing类型的算子也会进行重分区。
例子

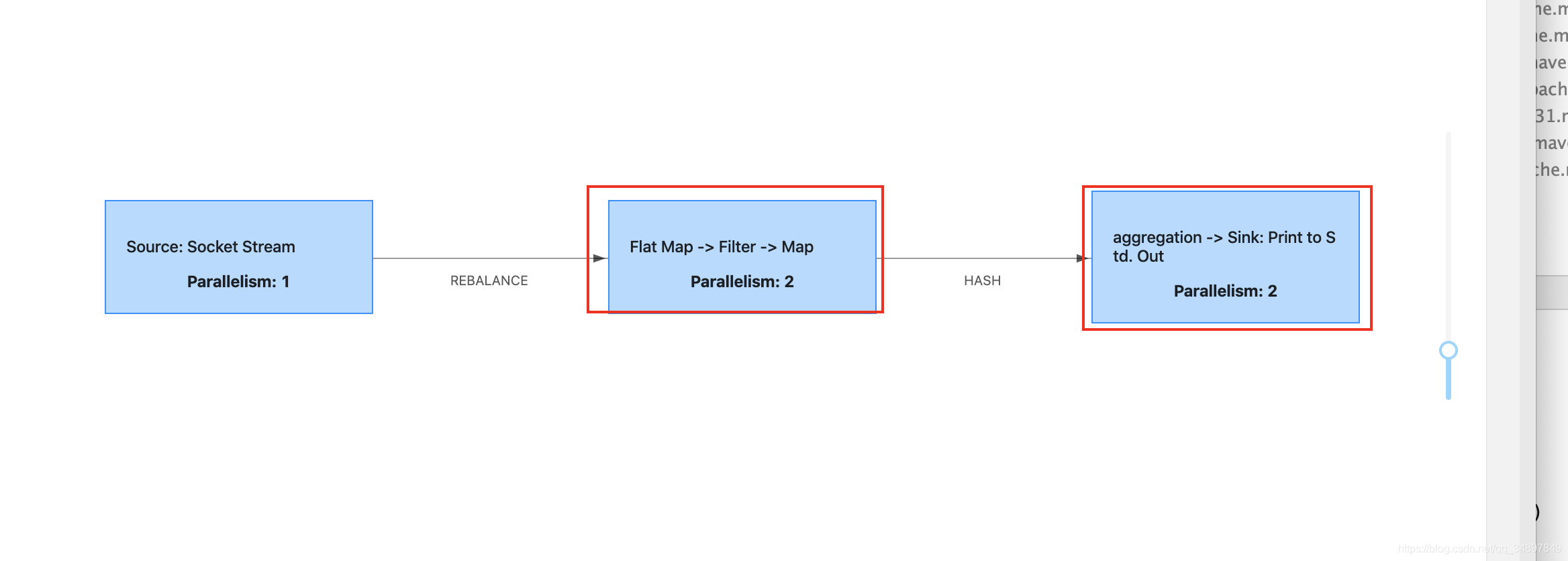
配置文件中默认并行度设置为2 ,提交代码是并行度设置为2
socket source 并行度只能是1
flatmap fliter map 并行度都是2 且属于one-to-one 合成任务链
keyby 属于redistrubuting hash 重分区
sum print 并行度为2 属于one-to-one
执行图如下

当然还可以禁止掉合成任务链
单个算子不参与合成任务链
.flatMap(_.split(" ")).disableChaining()1从单个算子开启一个新的任务链
全局不合成任务链
下面是一个全局不合成任务链的job执行图,只是在上一个例子的基础上添加了全局不合成任务链。

source 文件保证数顺序需要并行度为 1
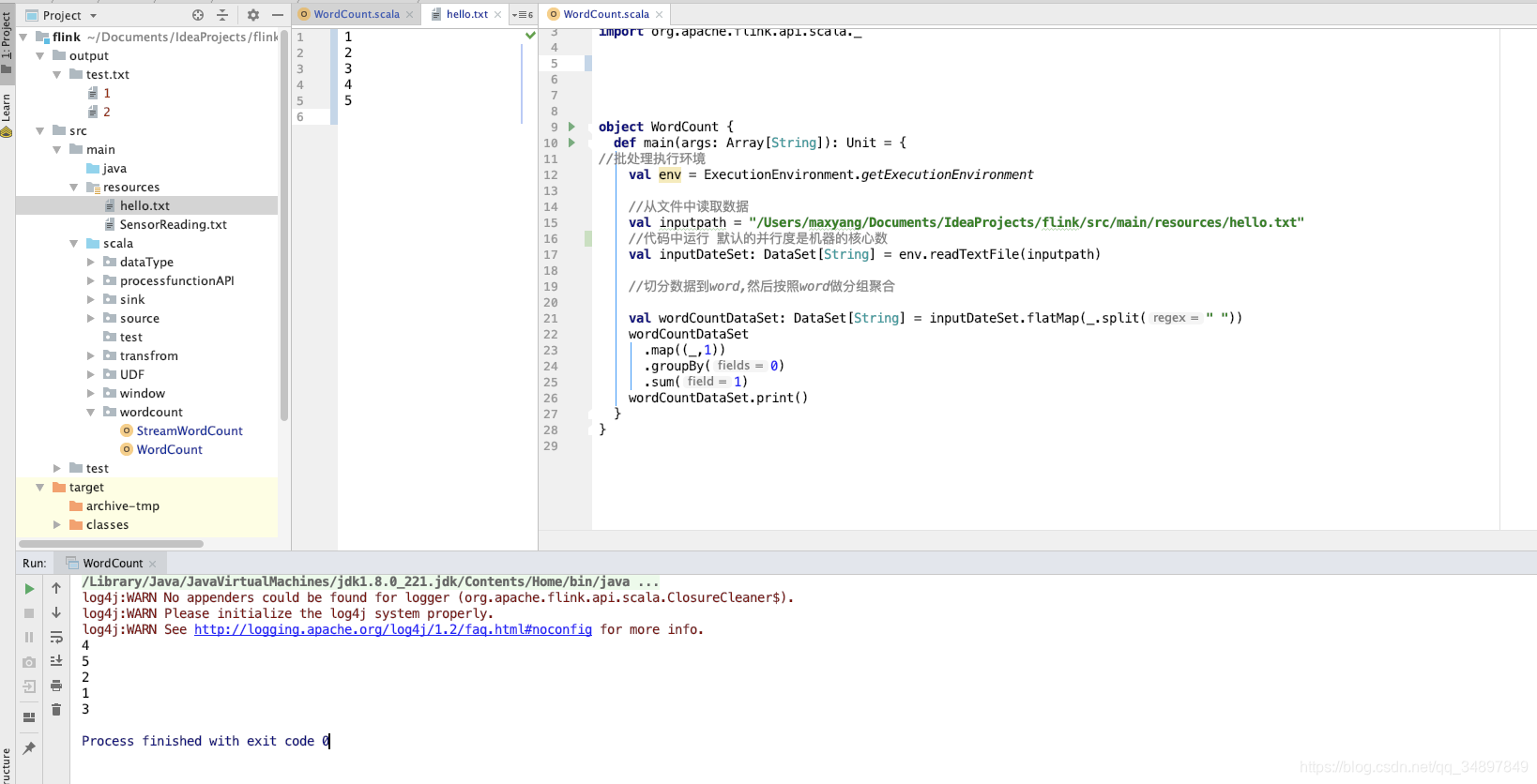
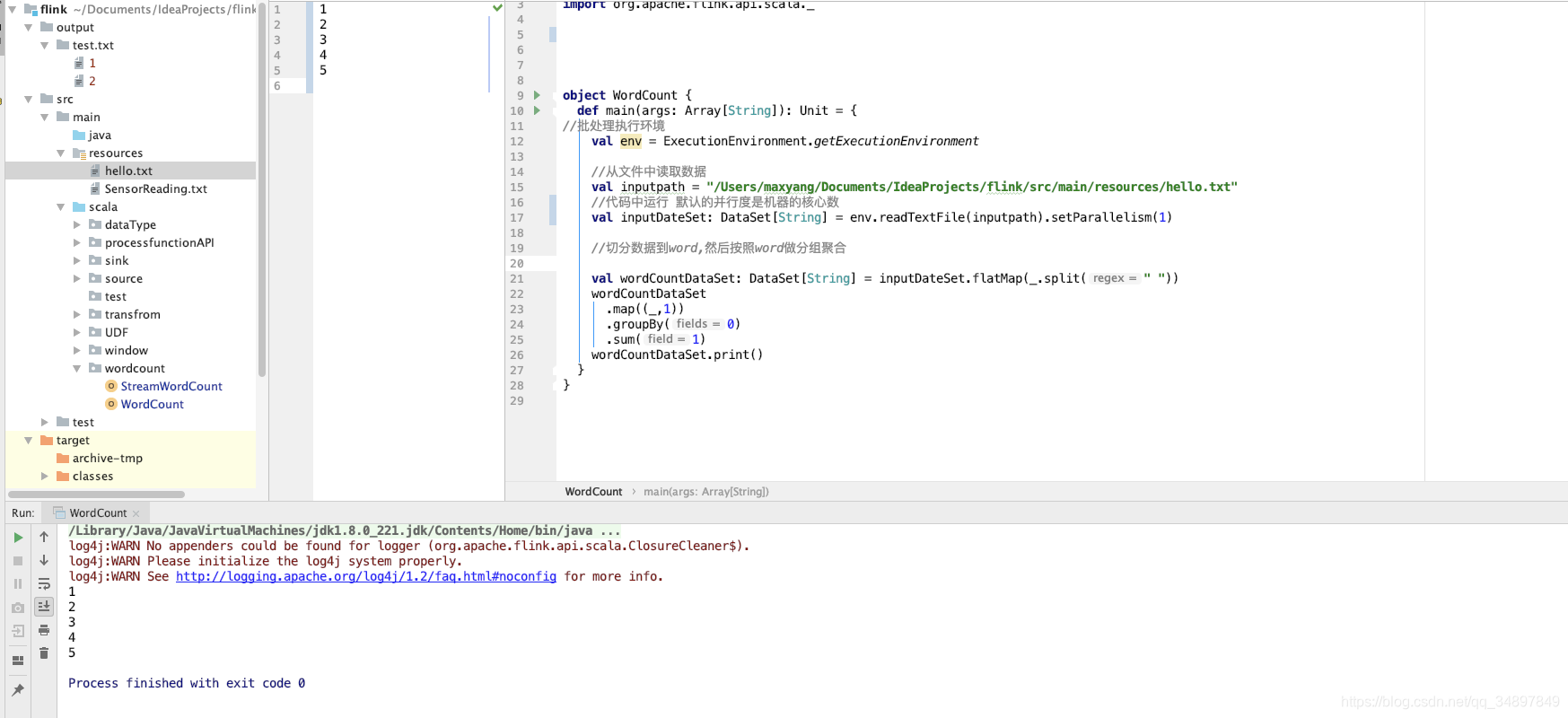
sink 只输出到一个文件需要并行度为 1
socketsource 并行度只能为1
Operator Chains(操作链)
Flink出于分布式执行的目的,将operator的subtask链接在一起形成task(类似spark中的管道)。
每个task在一个线程中执行。
将operators链接成task是非常有效的优化:它可以减少线程与线程间的切换和数据缓冲的开销,并在降低延迟的同时提高整体吞吐量。
链接的行为可以在编程API中进行指定,详情请见代码OperatorChainTest。
开启操作链 和 禁用操作链的对比图(默认开启):
Flink默认会将多个operator进行串联,形成任务链(task chain)
注意: task chain 可以理解为就是 operator chain 只是不同场景下,称呼不同。
我们也可以禁用任务链,让每个operator形成一个task。
StreamExecutionEnvironment.disableOperatorChaining() 这个方法会禁用整条工作链
操作链其实就是类似spark的pipeline管道模式,一个task可以执行同一个窄依赖中的算子操作。
我们也可以细粒度的控制工作链的形成,比如调用dataStreamSource.map(...).startNewChain(),但不能使用dataStreamSource.startNewChain()
dataStreamSource.filter(...).map(...).startNewChain().map(...),需要注意的是,当这样写时相当于source和filter组成一条链,两个map组成一条链。
即在filter和map之间断开,各自形成单独的链。
代码:
package com.ronnie.flink.stream.test;import org.apache.flink.api.common.functions.MapFunction;import org.apache.flink.api.java.tuple.Tuple2;import org.apache.flink.streaming.api.datastream.DataStreamSource;import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;/** * 开启与禁用工作链时,输出的结果不一样。 * 当开启工作链时(默认启动),operator map1与map2 组成一个task. * 此时task运行时,对于hello,flink 这两条数据是: * 先打印 hello ---- 1 , hello->1 ---- 2 * 后打印 flink ---- 1 , flink->1 ---- 2 * 当禁用工作链时,operator map1与map2 分别在两个task中执行 * 此时task运行时,对于hello,flink 这两条数据是: * 先打印 hello ---- 1 , flink ---- 1 * 后打印 hello->1 ---- 2 , flink->1 ---- 2 * * 注:操作链类似spark的管道,一个task执行多个的算子. */public class OperatorChainTest { public static final String[] WORDS = new String[] { "hello", "flink", "spark", "hbase" }; public static void main(String[] args) { // 设置执行环境, 类似spark中初始化sparkContext一样 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1); // 关闭操作链.. env.disableOperatorChaining(); DataStreamSource dataStreamSource = env.fromElements(WORDS);
SingleOutputStreamOperator pairStream = dataStreamSource.map(new MapFunction() { @Override
public String map(String value) throws Exception {
System.err.println(value + " ---- 1"); return value + "->1";
}
}).map(new MapFunction() { @Override
public String map(String value) throws Exception {
System.err.println(value + " ---- 2"); return value + "->2";
}
}); // 还可以控制更细粒度的任务链,比如指明从哪个operator开始形成一条新的链
// someStream.map(...).startNewChain(),但不能使用someStream.startNewChain()。
try {
env.execute();
} catch (Exception e) {
e.printStackTrace();
}
}
} Task slots(任务槽)
TaskManager 是一个 JVM 进程,并会以独立的线程来执行一个task或多个subtask。
为了控制一个 TaskManager 能接受多少个 task,Flink 提出了 Task Slot 的概念。
Flink 中的计算资源通过 Task Slot 来定义。每个 task slot 代表了 TaskManager 的一个固定大小的资源子集。
例如,一个拥有3个slot的 TaskManager,会将其管理的内存平均分成三分分给各个 slot。
将资源 slot 化意味着来自不同job的task不会为了内存而竞争,而是每个task都拥有一定数量的内存储备。
需要注意的是,这里不会涉及到CPU的隔离,slot目前仅仅用来隔离task的内存。
通过调整 task slot 的数量,用户可以定义task之间是如何相互隔离的。
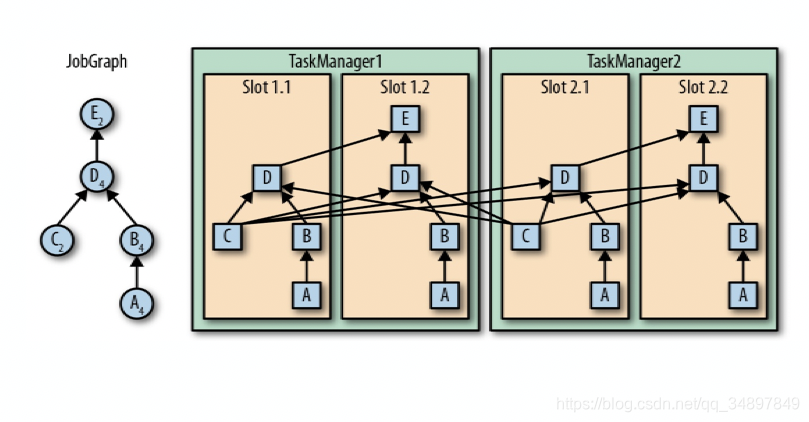
每个 TaskManager 有一个slot,也就意味着每个task运行在独立的 JVM 中。
每个 TaskManager 有多个slot的话,也就是说多个task运行在同一个JVM中。
而在同一个JVM进程中的task,可以共享TCP连接(基于多路复用)和心跳消息,可以减少数据的网络传输。
也能共享一些数据结构,一定程度上减少了每个task的消耗。
如图中所示,5个Task可能会在TaskManager的slots中分布,图中共2个TaskManager,每个有3个slot。
相关问题推荐
大数据(big data)一词越来越多地被提及,人们用它来描述和定义信息爆炸时代产生的海量数据,而这个海量数据的时代则被称为大数据时代。随着云时代的来临,大数据(Big data)也吸引了越来越多的关注。大数据(Big data)通常用来形容一个公司创造的大量非结...
Java和大数据的关系:Java是计算机的一门编程语言;可以用来做很多工作,大数据开发属于其中一种;大数据属于互联网方向,就像现在建立在大数据基础上的AI方向一样,他两不是一个同类,但是属于包含和被包含的关系;Java可以用来做大数据工作,大数据开发或者...
学完大数据可以从事很多工作,比如说:hadoop 研发工程师、大数据研发工程师、大数据分析工程师、数据库工程师、hadoop运维工程师、大数据运维工程师、java大数据工程师、spark工程师等等都是我们可以从事的工作岗位!不同的岗位,所具备的技术知识也是不一样...
简言之,大数据是指大数据集,这些数据集经过计算分析可以用于揭示某个方面相关的模式和趋势。大数据技术的战略意义不在于掌握庞大的数据信息,而在于对这些含有意义的数据进行专业化处理。大数据的特点:数据量大、数据种类多、 要求实时性强、数据所蕴藏的...
tail -f的时候,发现一个奇怪的现象,首先 我在一个窗口中 tail -f test.txt 然后在另一个窗口中用vim编辑这个文件,增加了几行字符,并保存,这个时候发现第一个窗口中并没有变化,没有将最新的内容显示出来。tail -F,重复上面的实验过程, 发现这次有变化了...
您好针对您的问题,做出以下回答,希望有所帮助!1、大数据行业还是有非常大的人才需求的,对于就业也有不同的岗位可选,比如大数据工程师,大数据运维,大数据架构师,大数据分析师等等,就业难就难在能否找到适合的工作,能否与你的能力和就业预期匹配。2、...
最小的基本单位是Byte应该没多少人不知道吧,下面先按顺序给出所有单位:Byte、KB、MB、GB、TB、PB、EB、ZB、YB、DB、NB,按照进率1024(2的十次方)计算:1Byte = 8 Bit1 KB = 1,024 Bytes 1 MB = 1,024 KB = 1,048,576 Bytes 1 GB = 1,024 MB = 1,048,576...
大数据的定义。大数据,又称巨量资料,指的是所涉及的数据资料量规模巨大到无法通过人脑甚至主流软件工具,在合理时间内达到撷取、管理、处理、并整理成为帮助企业经营决策更积极目的的资讯。大数据是对大量、动态、能持续的数据,通过运用新系统、新工具、新...
MySQL是一种关系型数据库管理系统,关系数据库将数据保存在不同的表中,而不是将所有数据放在一个大仓库内,这样就增加了速度并提高了灵活性。MySQL的版本:针对不同的用户,MySQL分为两种不同的版本:MySQL Community Server社区版本,免费,但是Mysql不提供...
mysql安装需要先使用yum安装mysql数据库的软件包 ;然后启动数据库服务并运行mysql_secure_installation去除安全隐患,最后登录数据库,便可完成安装
1.查看所有数据库showdatabases;2.查看当前使用的数据库selectdatabase();3.查看数据库使用端口showvariableslike'port';4.查看数据库编码showvariableslike‘%char%’;character_set_client 为客户端编码方式; character_set_connection 为建立连接...
CREATE TABLE IF NOT EXISTS `runoob_tbl`( `runoob_id` INT UNSIGNED AUTO_INCREMENT, `runoob_title` VARCHAR(100) NOT NULL, `runoob_author` VARCHAR(40) NOT NULL, `submission_date` DATE, PRI...
学习多久,我觉得看你基础情况。1、如果原来什么语言也没有学过,也没有基础,那我觉得最基础的要先选择一种语言来学习,是VB,C..,pascal,看个人的喜好,一般情况下,选择C语言来学习。2、如果是有过语言的学习,我看应该一个星期差不多,因为语言的理念互通...
添加语句 INSERT插入语句:INSERT INTO 表名 VALUES (‘xx’,‘xx’)不指定插入的列INSERT INTO table_name VALUES (值1, 值2,…)指定插入的列INSERT INTO table_name (列1, 列2,…) VALUES (值1, 值2,…)查询插入语句: INSERT INTO 插入表 SELECT * FROM 查...
看你什么岗位吧。如果是后端,只会CRUD。应该是可以找到实习的,不过公司应该不会太好。如果是数据库开发岗位,那这应该是不会找到的。
查找数据列 SELECT column1, column2, … FROM table_name; SELECT column_name(s) FROM table_name