{var%20f='http://v.t.sina.com.cn/share/share.php?appkey=1515056452',u=z||d.location,p=['&url=',e(u),'&title=',e(t||d.title),'&source=',e(r),'&sourceUrl=',e(l),'&content=',c||'gb2312','&pic=',e(p||'')].join('');function%20a(){if(!window.open([f,p].join(''),'mb',['toolbar=0,status=0,resizable=1,width=440,height=430,left=',(s.width-440)/2,',top=',(s.height-430)/2].join('')))u.href=[f,p].join('');};if(/Firefox/.test(navigator.userAgent))setTimeout(a,0);else%20a();})(screen,document,encodeURIComponent,'','','http://www.shouhuola.com/static/css/dist/css/images/default.jpg', '推荐 爬虫大王 的文章《【Hadoop技术】——离线分析系统结构概述》','http://www.shouhuola.com/article-1942.html','页面编码gb2312|utf-8默认gb2312'));){kind=link}
一、 需求分析
![]()
![]() 案例名称
案例名称
XX 网/XX app 点击流日志数据挖掘系统
网站分析的主要手段是分析网站的点击流数据。
XX 网/XX app 点击流日志数据挖掘系统
网站分析的主要手段是分析网站的点击流数据。
(1)点击流的概念
点击流( Click Stream)是指用户在网站上持续访问的轨迹。 这个概念更注重用户浏览网站的整个流程。 用户对网站的每次访问包含了一系列的点击动作行为,这些点击行为数据就构成了点击流数据( Click Stream Data),它代表了用户浏览网站的整个流程。
总结:点击流其实就是用户日常浏览网站时产生的日志信息。
(2)日志规模分析
一般中型的网站(10W 以上的 PV,即页面浏览量),每天会产生 1G 以上 Web 日志文件。大型或超大型的网站,可能每小时就会产生 10G 的数据量。 具体来说,比如某电子商务网站,在线团购业务。每日 PV 数 100w,独立 IP 数 5w。用户通常在工作日上午 10:00-12:00 和下午 15:00-18:00 访问量最大。日间主要是通 过 PC 端浏览器访问,休息日及夜间通过移动设备访问较多。网站搜索浏量占整个网站的 80%,PC 用户不足 1% 的用户会消费,移动用户有 5% 会消费。
对于日志的这种规模的数据,用 Hadoop 进行日志分析,是最适合不过的了。
![]()
![]() 案例需求描述
案例需求描述
“Web 点击流日志” 包含着网站运营很重要的信息,通过日志分析,我们可以知道网站的访问量,哪个网页访问人数最多,哪个网页最有价值,广告转化率,访客来源信息,访客终端信息等。
网站分析基础指标:
(1)浏览量(PV)
定义:Page View,即页面浏览量或点击量,用户每打开一个页面就被记录1次。
(2)访问次数
定义:访问次数即 Visit,访客在网站上的会话(Session)次数,一次会话过程中可能浏览多个页面。
(3)访客数(UV)
定义:Unique Visitor,即唯一访客数,一天之内网站的独立访客数(以 Cookie 为依据 ),一天内同一访客多次访问网站只计算 1 个访客。
(4)独立 IP 数
定义:Internet Protocol,指独立 IP 数。一天之内,访问网站的不同独立 IP 个数加和。其中同一 IP 无论访问了几个页面,独立 IP 数均为 1。
![]()
![]() 数据来源
数据来源
本案例的数据主要由用户的点击行为记录。
获取方式:在页面预埋一段 js 程序,为页面上想要监听的标签绑定事件,只要用户点击或移动到标签,即可触发 AJAX 请求到后台 servlet 程序,用 log4j 记录下事件信息,从而在 Web 服务器(nginx、Tomcat 等)上形成不断增长的日志文件。
形如:
字段解析:
(1)访客 IP 地址:58.215.204.118
(2)访客用户信息: - -
(3)请求时间:[18/Sep/2019:06:51:35 +0000]
(4)请求方式:GET
(5)请求的 URL:/wp-includes/js/jquery/jquery.js?ver=1.10.2
(6)请求所用协议:HTTP/1.1
(7)响应码:304
(8)返回的数据流量:0
(9)访客的来源 URL:http://blog.fens.me/nodejs-socketio-chat/
(10)访客所用浏览器:Mozilla/5.0 (Windows NT 5.1; rv:23.0) Gecko/20100101 Firefox/23.0
![]()
![]() 二、 数据处理流程
二、 数据处理流程
![]()
![]() 流程图解析
流程图解析
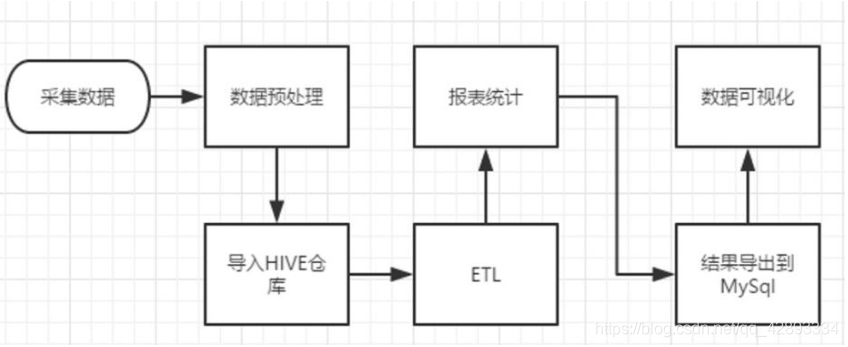
该项目是一个纯粹的数据分析项目,其整体流程基本上就是依据数据的处理流程进行,依此有以下几个大的步骤:
(1)数据采集:定制开发采集程序,或使用开源框架 Flume。将各服务器上生成的点击流日志通过实时或批量的方式汇聚到 HDFS 文件系统中。
(2)数据预处理:定制开发 MapReduce 程序运行于 Hadoop 集群。通过 MapReduce 程序对采集到的点击流数据进行预处理,比如清洗、格式整理、滤除脏数据等。
(3)数据仓库技术:基于 Hadoop 之上的 Hive。将预处理之后的数据导入到 Hive 仓库中相应的库和表中,根据需求开发 ETL 分析语句,得出各种统计结果。
(4)数据导出:基于 Hadoop 的 Sqoop 数据导入导出工具 ,将 Hive 中的数据导出到 MySQL 等关系型数据库中。
(5)数据可视化:定制开发 Web 程序或使用 Echarts、Highcharts 等产品 。数据展现的目的是将分析所得的数据进行可视化,以便运营决策人员能更方便地获取数据,更快更简单地理解数据。
(6)整个过程的流程调度: Hadoop 生态圈中 Oozie/Azkaban 工具或其他类似开源产品
![]()
![]() 项目整体技术架构图
项目整体技术架构图
由于本项目是一个纯粹数据分析项目,其整体结构亦跟分析流程匹配,并没有特别复杂的结构。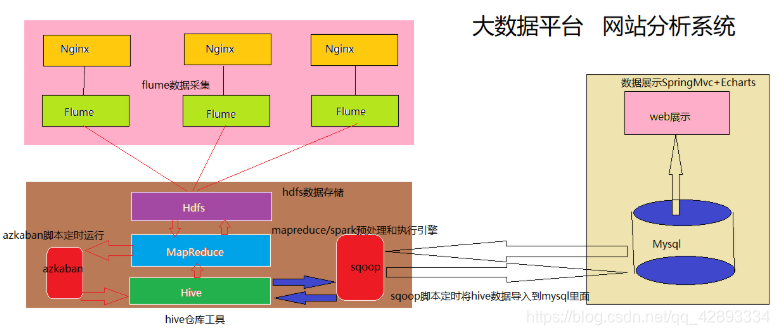
其中,需要强调的是:系统的数据分析不是一次性的,而是按照一定的时间频率反复计算,因而整个处理链条中的各个环节需要按照一定的先后依赖关系紧密衔接,即涉及到大量任务单元的管理调度,所以,项目中需要添加一个任务调度模块。
![]()
![]() 三、 项目最终效果
三、 项目最终效果
经过复杂的数据处理流程后,会周期性输出各类统计指标的报表。在生产实践中,最终需要将这些报表数据以可视化的形式展现出来,市面上有许多开源的数据可视化工具,比如:Echarts。
转载自:CSDN 作者:LinGavinQ
原文链接:https://blog.csdn.net/qq_42893334/article/details/106601098