一、URL分析
在此,博主爬取的是网易云网页版,因为一般网页版都是最好爬取的,不要问我为什么,问就是不会!

网易云网页版链接:https://music.163.com/
歌手信息链接:https://music.163.com//discover/artist
但是由上图我们可以看出,虽然直接给出了网页链接,但是我们通过查看网页源代码,发现我们想要爬取的信息并没有在这个网页中。
这个时候,我们就需要通过Sreach查找歌手信息,从而得到我们所需要的各种信息。
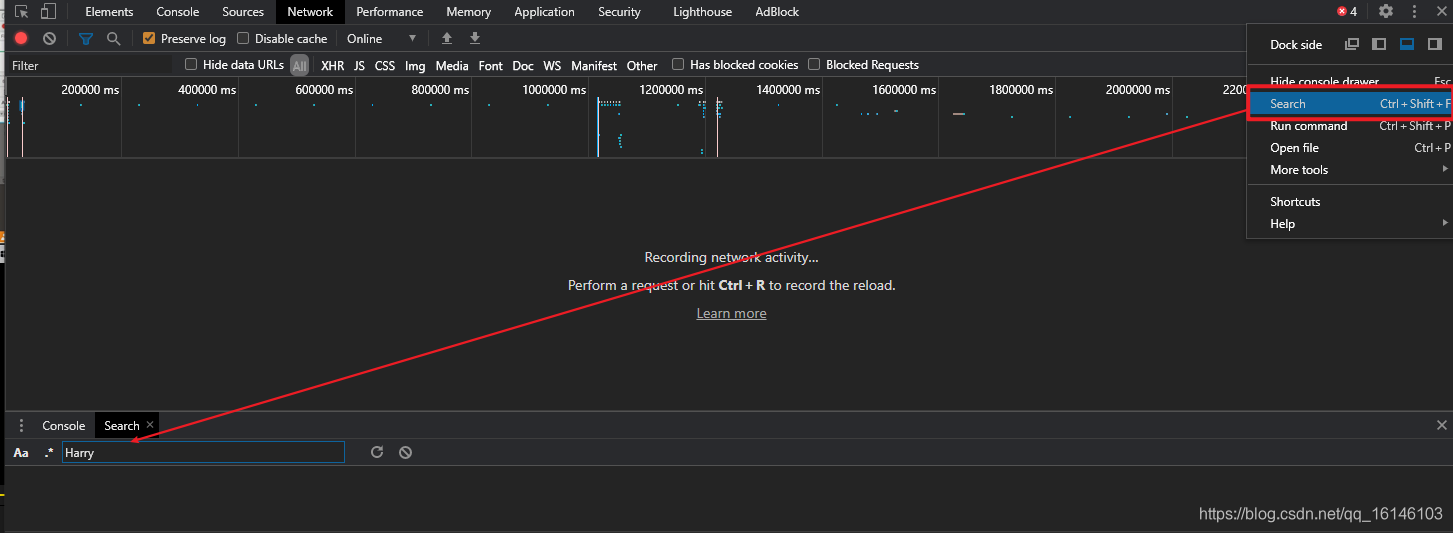
我们首先就以薛之谦为例
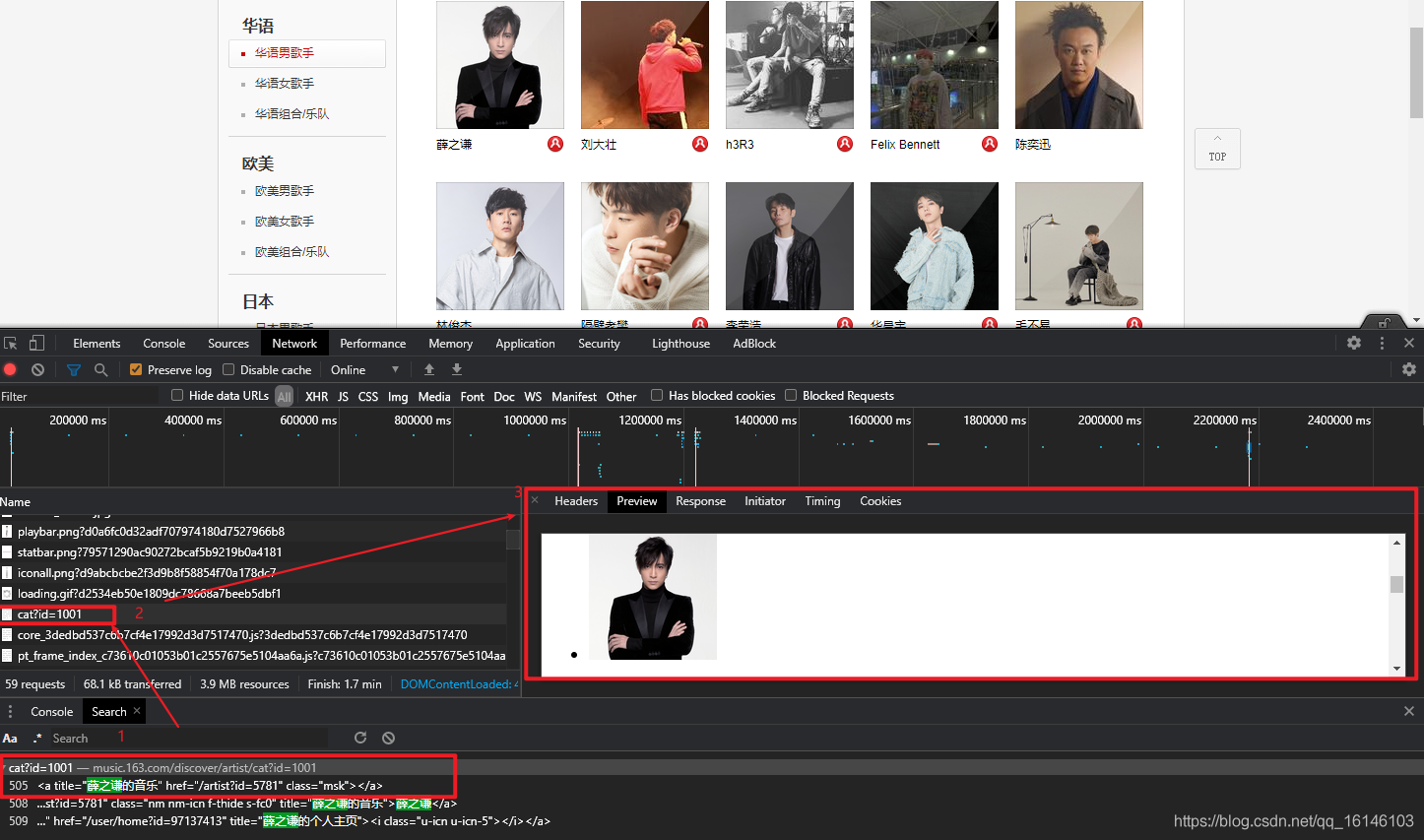
通过上图,我们可以知道我们所需要的爬取内容的网址:

我们可以多尝试几次,然后就会发现每个分类代表其中一个id
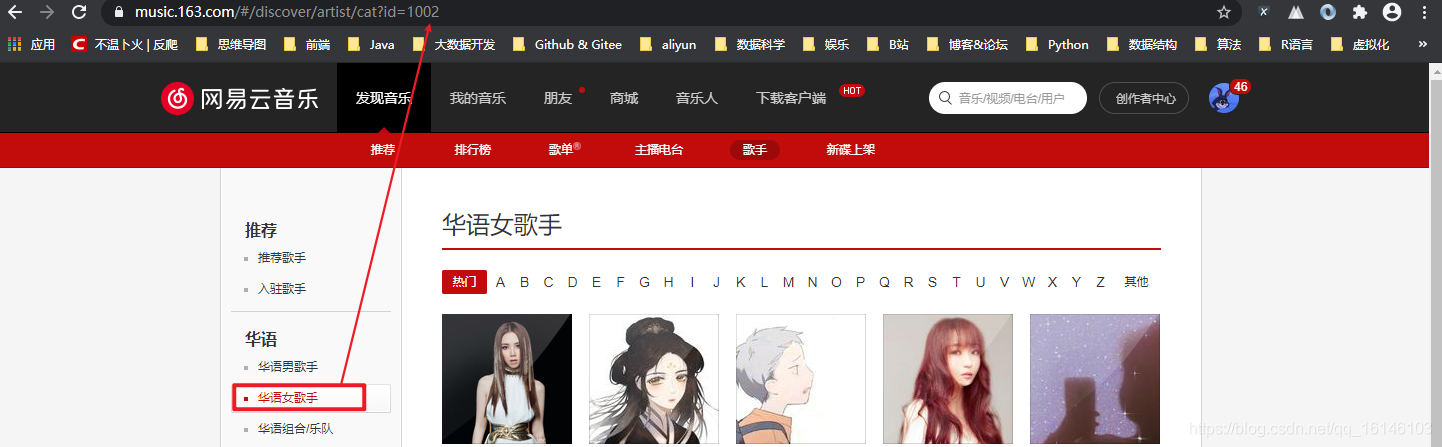
规律来了,那么我们是不是就可以使用xpath进行解析提取了呢? 我们可以先试验一下:
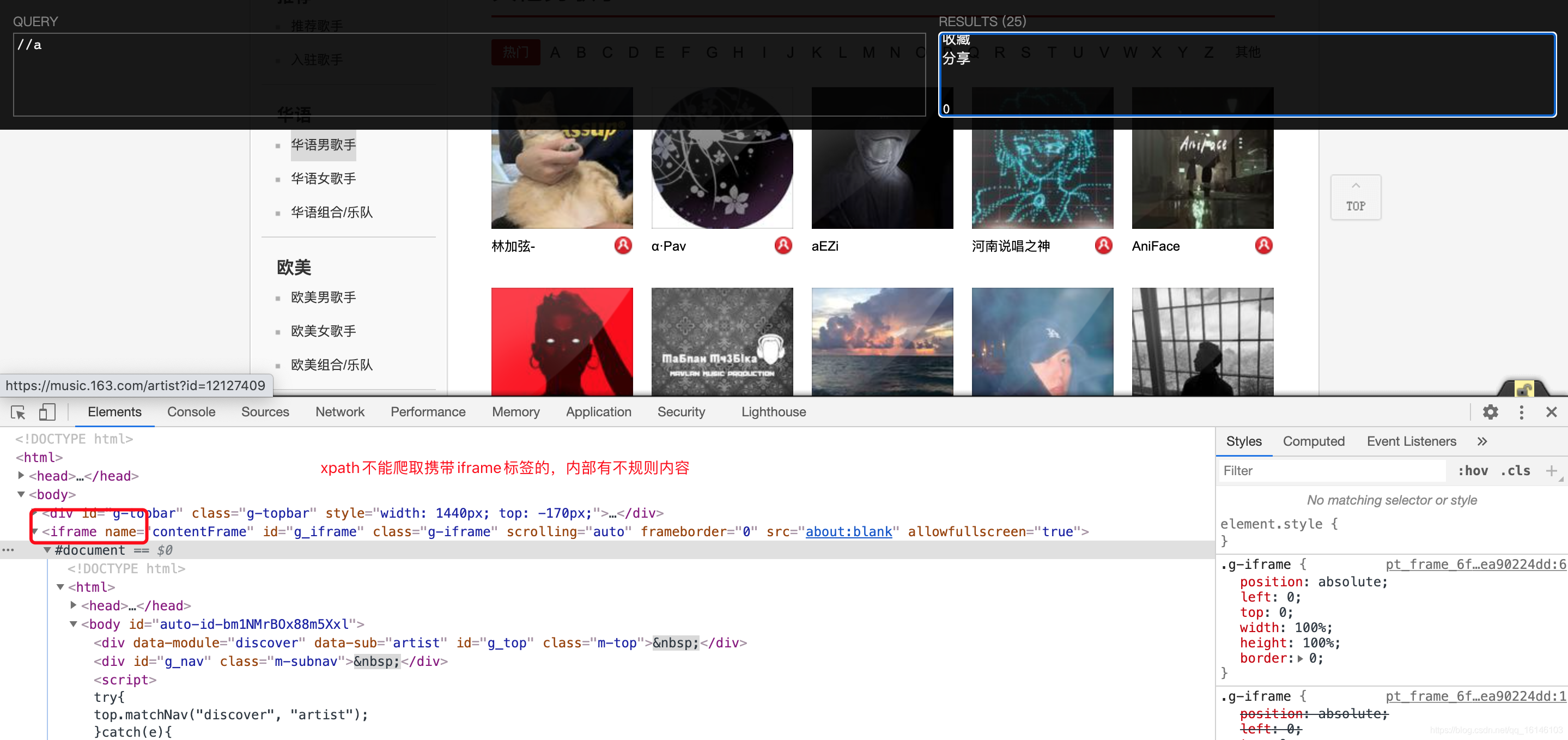
我们发现这个页面是不能直接使用xpath进行解析得,xpath只能解析html标签。因为该网页携带有iframe标签,内容有不规则内容。

既然出现问题了,那么我们首先要想的就是要解决xpath不能进行解析这一问题。
通过验证我们发现,虽然在页面插件中不能访问,但是我们发现向另一个url发送请求依然可以获取数据,且里面没有iframe,可以直接使用xpath。
测试代码如下:
import requestsfrom lxml import etree
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36',}base_url = "https://music.163.com/discover/artist/cat?id=1001"response = requests.get(url=base_url, headers=headers)html = response.content.decode("utf-8")print(html)1234567891011我们通过查找iframe,发现里面没有包含iframe,这里就可以直接使用xpath进行解析了
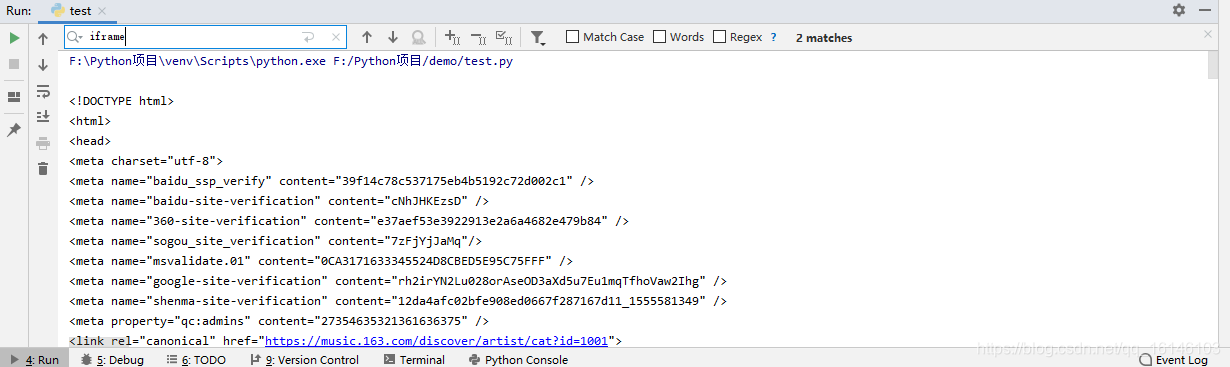
查找华语男歌手
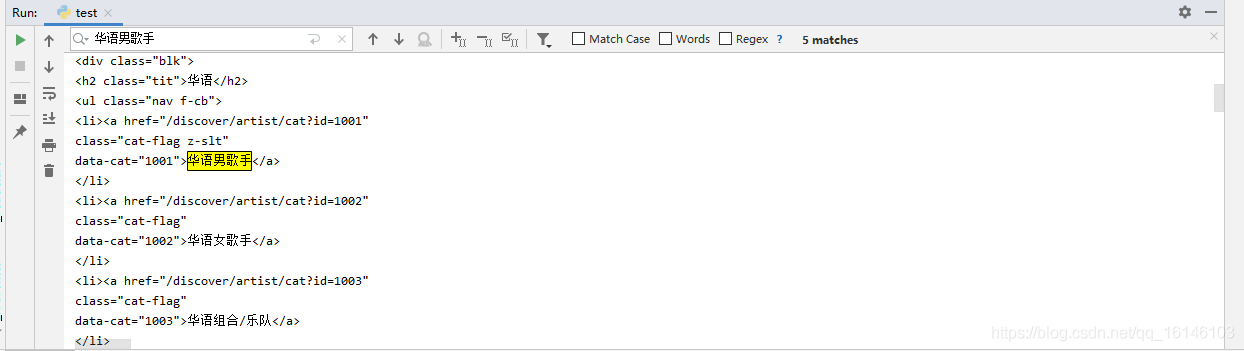
先把华语男歌手这一部分复制出来
<li><a href="/discover/artist/cat?id=1001"class="cat-flag z-slt"data-cat="1001">华语男歌手</a></li>1234
我们先来尝试使用xpath进行解析
# 只有华语男歌手ret = etree_obj.xpath('//a[@class="cat-flag z-slt"]/text()')print(ret)123
????,我们发现,可以获取到华语男歌手,那么我们尝试获取所有歌手的分类
# 所有歌手ret = etree_obj.xpath('//a[@class="cat-flag"]/text()')print(ret)123
获取了分类之后,我们就可以获取到每个类所对应的链接
# 链接ret = etree_obj.xpath('//a[@class="cat-flag"]/@href')print(ret)123
下面就开始看看拼接的URL能否正常打开
"""
华语男歌手: https://music.163.com/discover/artist/cat?id=1001
华语女歌手: https://music.163.com/discover/artist/cat?id=1002
"""1234
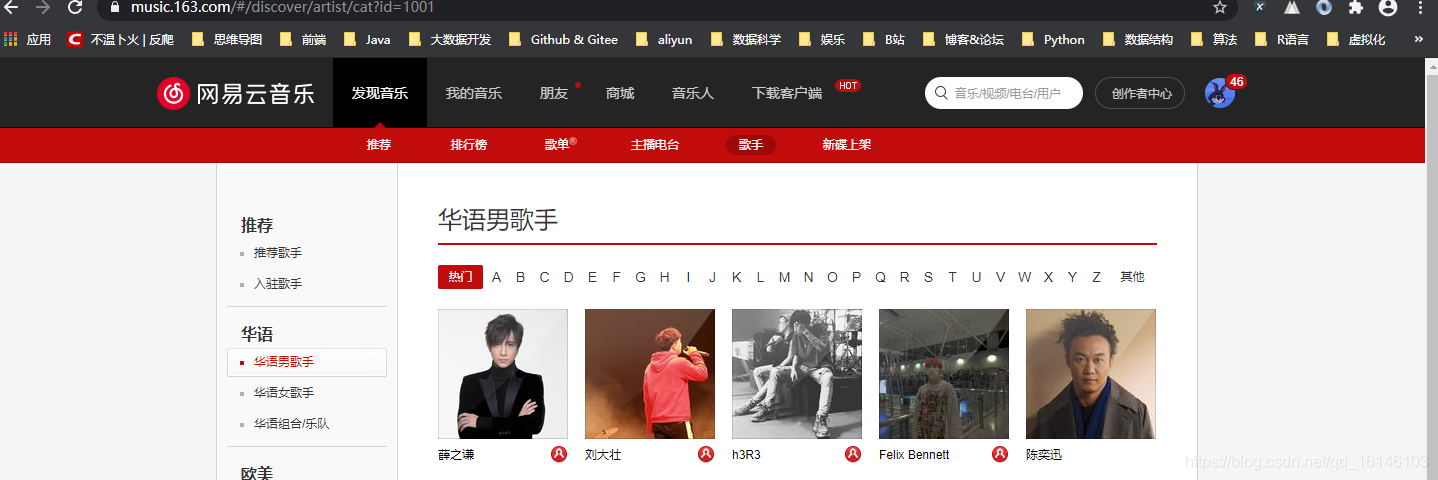
????,我们发现正是我们想要爬取内容的URL,至于前两个推荐歌手以及入住歌手为什么不爬取,是因为推荐的这些歌手都在我们要爬取的分类之中,如果全部爬取,会出现重复现象。

![]()
![]() 二、局部代码实现
二、局部代码实现
![]()
![]() 2.1 获取所有的歌手类型
2.1 获取所有的歌手类型
def get_type_url():
"""获取所有的歌手类型"""
types = []
html = parse_url(start_url)
etree_obj =parse_html(html)
type_name_list = etree_obj.xpath('//a[@class="cat-flag"]/text()')
# print(type_name_list)
type_url_list = etree_obj.xpath('//a[@class="cat-flag"]/@href')
data_zip = zip(type_name_list[1:],type_url_list[1:])
for data in data_zip:
type = {}
type["name"] = data[0]
type["url"] = data[1]
types.append(type)
return types123456789101112131415161718
![]()
![]() 2.2 爬歌手数据
2.2 爬歌手数据
1. 分析
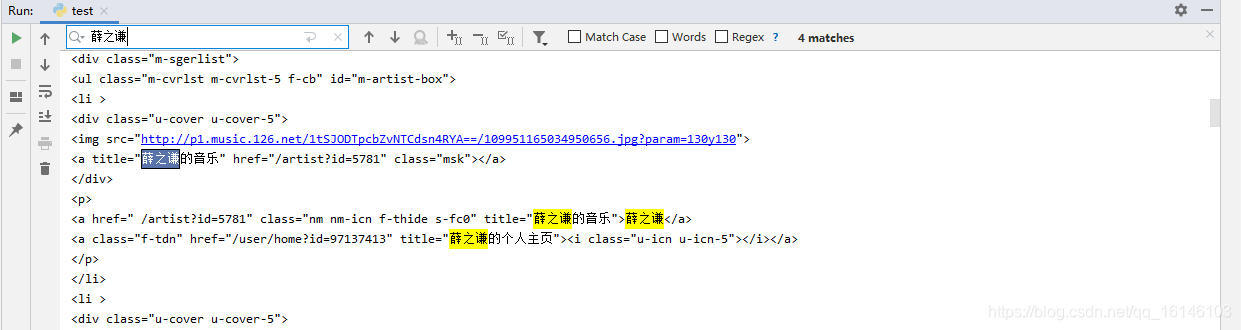
把此部分的源码拿出来
<a href=" /artist?id=5781" class="nm nm-icn f-thide s-fc0" title="薛之谦的音乐">薛之谦</a><a class="f-tdn" href="/user/home?id=97137413" title="薛之谦的个人主页"><i class="u-icn u-icn-5"></i></a>12
def get_data(url, type_name):
"""爬歌手数据"""
item = {
"type": type_name,
"name": "",
"url": ""
}
html = parse_url(url)
etree_obj = parse_html(html)
artist_name_list = etree_obj.xpath('//a[@class="nm nm-icn f-thide s-fc0"]/text()')
artist_url_list = etree_obj.xpath('//a[@class="nm nm-icn f-thide s-fc0"]/@href')
data_zip = zip(artist_name_list, artist_url_list)
for data in data_zip:
item["name"] = data[0]
item["url"] = base_url + data[1][1:]
items.append(item)123456789101112131415161718
我们通过观察,发现歌手正好是100个,说明我们已经成功拿到数据了。

![]()
![]() 2.3 发现问题
2.3 发现问题
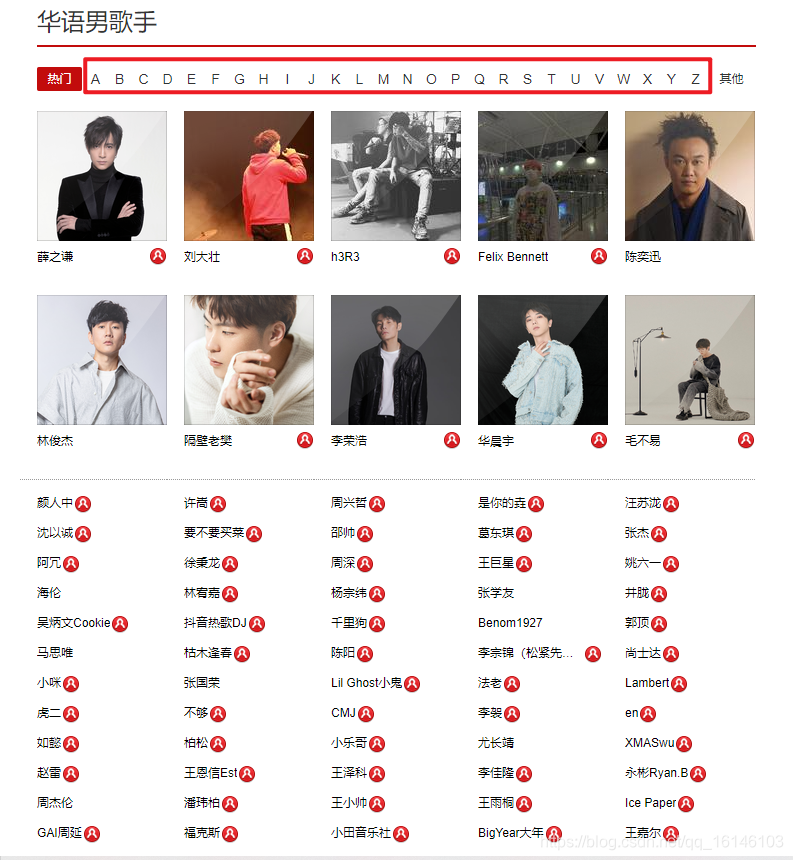
经过上述过程,我们已经把数据拿全了。但是我们经过查看,发现我们拿的数据并不准确,我们发现我们拿的数据应该是从A到Z才对。
并且通过点击,我们也是发现有规律的,规律如下
https://music.163.com/#/discover/artist/cat?id=1001&initial=65https://music.163.com/#/discover/artist/cat?id=1001&initial=66https://music.163.com/#/discover/artist/cat?id=1001&initial=90123
通过上述的规律,我们发现还要在我们已经获取的URL的基础上再加上&initial=(65,90)才行
def start():
"""开始爬虫"""
types = get_type_url()
# print(types)
for type in types:
# url = base_url+type["url"]
# url还不够完整
# print(url)
for i in range(65,91):
url = "{}{}&initial={}".format(base_url,type["url"],i)
print(url)
get_data(url, type["name"])123456789101112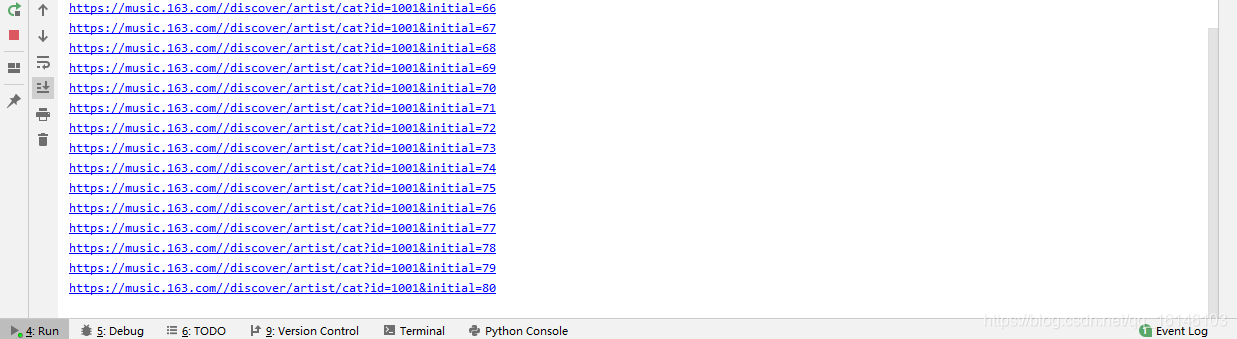

![]()
![]() 三、完整代码
三、完整代码
# encoding: utf-8'''
@author 李华鑫
@create 2020-10-08 8:27
Mycsdn:https://buwenbuhuo.blog.csdn.net/
@contact: 459804692@qq.com
@software: Pycharm
@file: 作业:网易云音乐.py
@Version:1.0
'''"""
华语男歌手: https://music.163.com/discover/artist/cat?id=1001
华语女歌手: https://music.163.com/discover/artist/cat?id=1002
"""import requestsimport randomimport csvimport timefrom lxml import etree# num = [1001,1002,1003,2001,2002,2003,6001,6002,6003,7001,7002,7003,4001,4002,4003]base_url = "https://music.163.com/"# start_url = "https://music.163.com/discover/artist/cat?id=1001"start_url = "https://music.163.com/discover/artist/"headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36',}items = []def parse_url(url):
"""解析url,得到响应内容"""
time.sleep(random.random())
response = requests.get(url=url,headers=headers)
return response.content.decode("utf-8")def parse_html(html):
"""使用xpath解析html,返回xpath对象"""
etree_obj = etree.HTML(html)
return etree_objdef get_type_url():
"""获取所有的歌手类型"""
types = []
html = parse_url(start_url)
etree_obj =parse_html(html)
type_name_list = etree_obj.xpath('//a[@class="cat-flag"]/text()')
# print(type_name_list)
type_url_list = etree_obj.xpath('//a[@class="cat-flag"]/@href')
data_zip = zip(type_name_list[1:],type_url_list[1:])
for data in data_zip:
type = {}
type["name"] = data[0]
type["url"] = data[1]
types.append(type)
return typesdef get_data(url, type_name):
"""爬歌手数据"""
item = {
"type": type_name,
"name": "",
"url": ""
}
html = parse_url(url)
etree_obj = parse_html(html)
artist_name_list = etree_obj.xpath('//a[@class="nm nm-icn f-thide s-fc0"]/text()')
artist_url_list = etree_obj.xpath('//a[@class="nm nm-icn f-thide s-fc0"]/@href')
data_zip = zip(artist_name_list, artist_url_list)
for data in data_zip:
item["name"] = data[0]
item["url"] = base_url + data[1][1:]
items.append(item)def save():
"""将数据保存到csv中"""
with open("./wangyinyun.csv", "a", encoding="utf-8") as file:
writer = csv.writer(file)
for item in items:
writer.writerow(item.values())def start():
"""开始爬虫"""
types = get_type_url()
# print(types)
for type in types:
# url = base_url+type["url"]
# url还不够完整
# print(url)
for i in range(65,91):
url = "{}{}&initial={}".format(base_url,type["url"],i)
print(url)
get_data(url, type["name"])
save()
# exit()if __name__ == '__main__':
start()"""测试代码"""# start_url = "https://music.163.com/discover/artist/cat?id=1001&initial=65" a _ z# response = requests.get(url=base_url,headers=headers)# # print(response.content.decode("utf-8"))# html = response.content.decode("utf-8")# print(html)# etree_obj = etree.HTML(html)# # 只有华语男歌手# # ret = etree_obj.xpath('//a[@class="cat-flag z-slt"]/text()')# # 所有歌手# ret = etree_obj.xpath('//a[@class="cat-flag"]/text()')# print(ret)# print(len(ret))## # 链接# ret = etree_obj.xpath('//a[@class="cat-flag"]/@href')# print(ret)"""
<li><a href="/discover/artist/cat?id=1001"
class="cat-flag z-slt"
data-cat="1001">华语男歌手</a>
</li>
https://music.163.com/discover/artist/cat?id=1001&initial=65
"""123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869707172737475767778798081828384858687888990919293949596979899100101102103104105106107108109110111112113114115116117118119120121122123124125126127128129130131132133134135
![]()
![]() 四、运行结果
四、运行结果
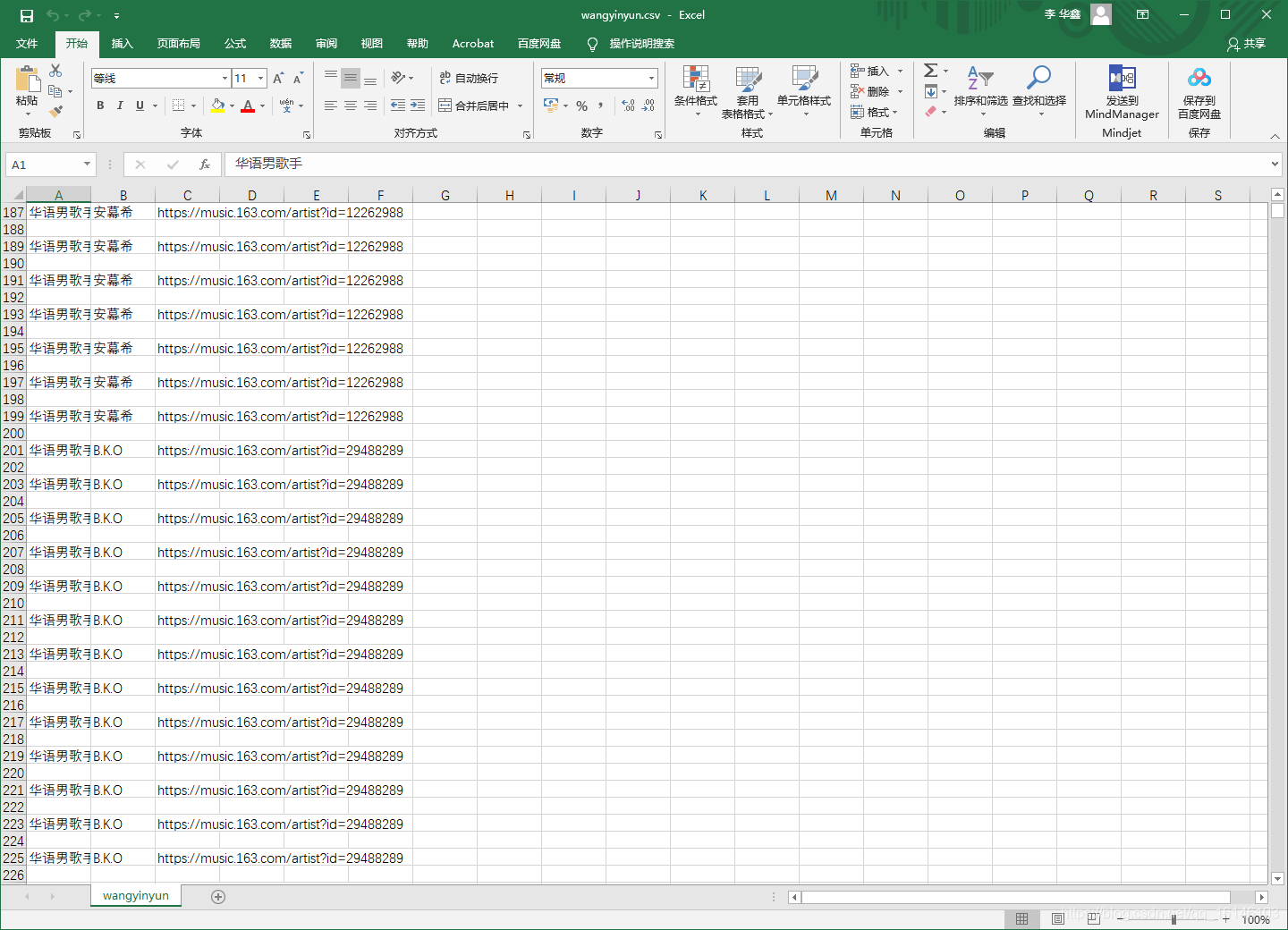

美好的日子总是短暂的,虽然还想继续与大家畅谈,但是本篇博文到此已经结束了,如果还嫌不够过瘾,不用担心,我们下篇见!
转载自:CSDN 作者:不温卜火
原文链接:https://buwenbuhuo.blog.csdn.net/article/details/109283572
{var%20f='http://v.t.sina.com.cn/share/share.php?appkey=1515056452',u=z||d.location,p=['&url=',e(u),'&title=',e(t||d.title),'&source=',e(r),'&sourceUrl=',e(l),'&content=',c||'gb2312','&pic=',e(p||'')].join('');function%20a(){if(!window.open([f,p].join(''),'mb',['toolbar=0,status=0,resizable=1,width=440,height=430,left=',(s.width-440)/2,',top=',(s.height-430)/2].join('')))u.href=[f,p].join('');};if(/Firefox/.test(navigator.userAgent))setTimeout(a,0);else%20a();})(screen,document,encodeURIComponent,'','','http://www.shouhuola.com/static/css/dist/css/images/default.jpg', '推荐 爬虫大王 的文章《爬虫入门经典(十) | 一文带你快速爬取网易云音乐》','http://www.shouhuola.com/article-1966.html','页面编码gb2312|utf-8默认gb2312'));){kind=link}