一、小小课堂
由于只是属于教学性质,学长本人在此以就以爬取Python相关的图书为例!
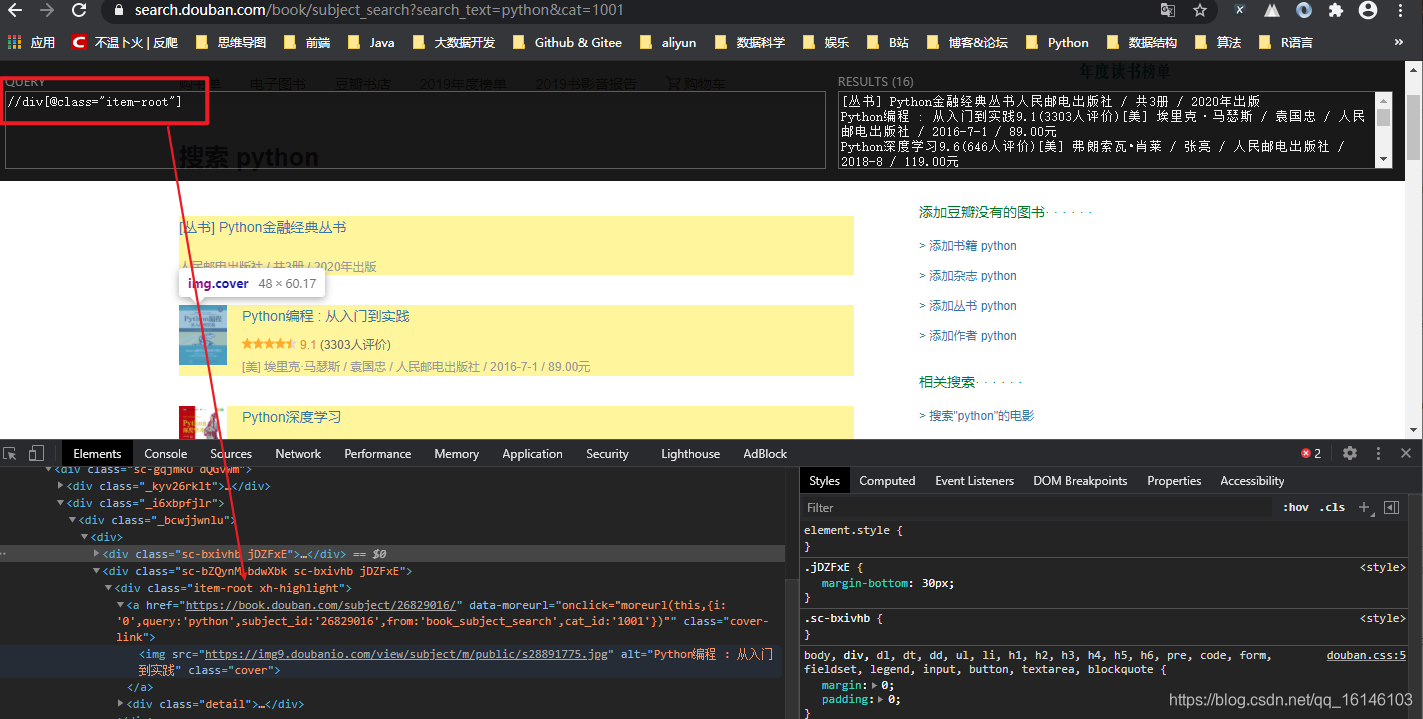
链接:https://search.douban.com/book/subject_search?search_text=python&cat=1001
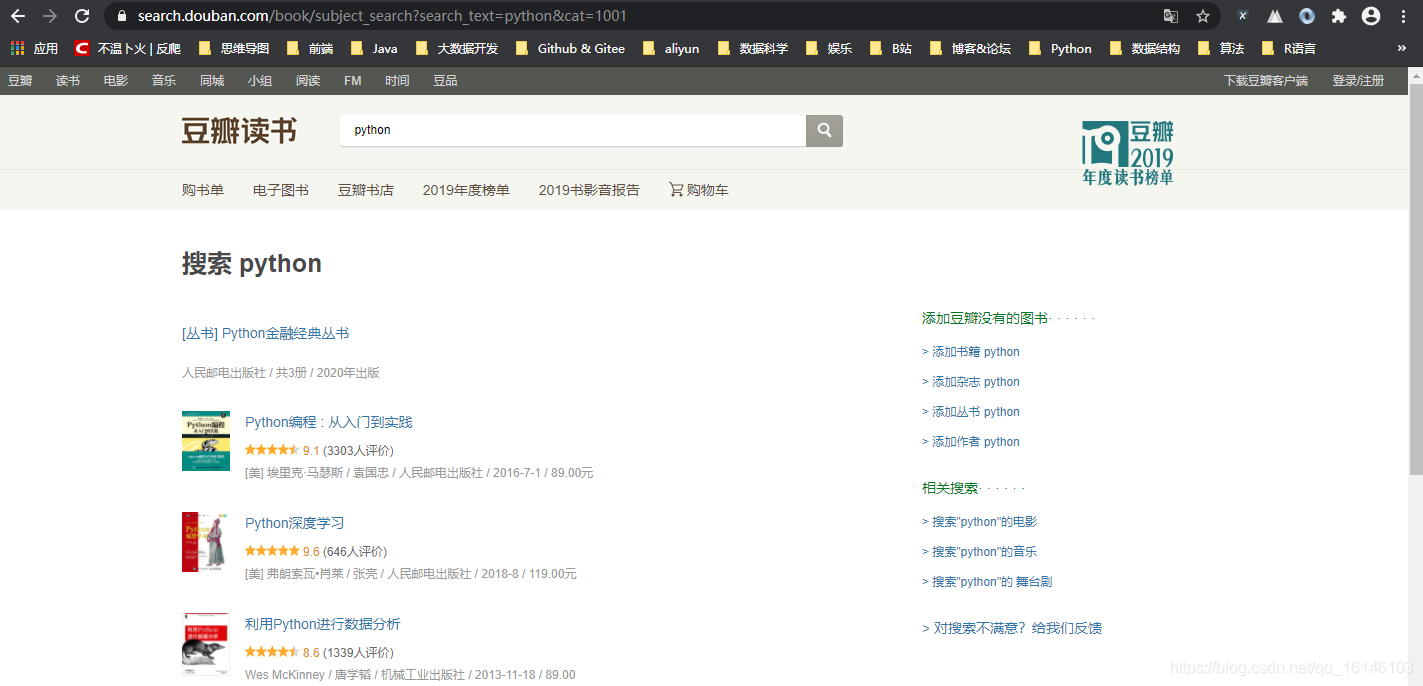
首先我们需要先找下有没有接口
但是通过查看,我们发现是没有接口的。经过分析,这个网站展示的数据,不能通过之前的方式获取,猜想是通过加密解密得到的内容。这个时候有两种方式
a:找到加密解密的接口,使用python模拟(相当复杂,必须有解析js的能力)
b:使用selenium+driver直接获取解析后的页面数据内容(这种相对简单)
当然了,我们只是分析了接口这一部分,其实我们通过查看网页源码,使用xpath进行尝试解析,发现其实是可行的,但是由于本篇博文使用的是自动化工具selenium,所以就不过多解释xpath。
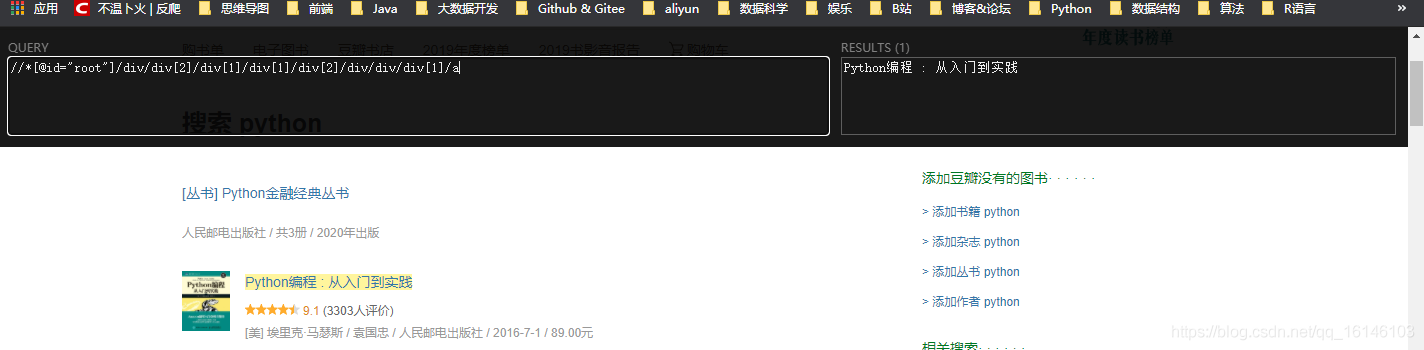
在这里,我们使用selenium+driver能模拟浏览器找到elements里的内容,这样再提取就没问题了。
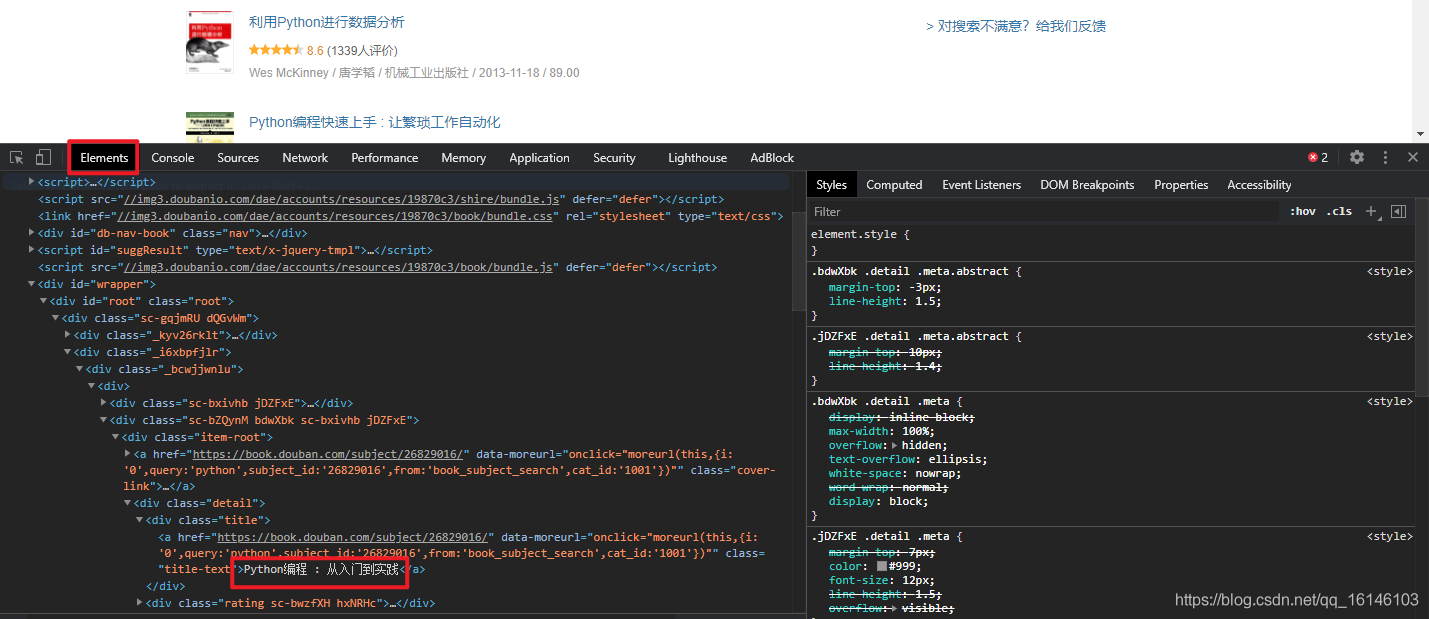
接下来我们需要了解一些概念
1.什么是selenium?
selenium是网页自动化测试工具,可以自动化的操作浏览器。如果需要操作哪个浏览器需要安装对应的driver,比如你需要通过selenium操作chrome,那必须安装chromedriver,而且版本与chrome保持一致。
2、driver
操作浏览器的驱动,分为有界面和无界面的
有界面:与本地安装好的浏览器一致的driver(用户可以直接观看,交互比如单击、输入)
无界面:phantomjs(看不到,只能通过代码操作,加载速度比有界面的要快)
了解完之后,安装selenium:
pip install selenium -i https://pypi.tuna.tsinghua.edu.cn/simple1
下载driver
下载好之后,放入项目中,方便找到。
![]()
![]() 二、selenium+driver初步尝试控制浏览器
二、selenium+driver初步尝试控制浏览器
说到模拟,那我们就先来模拟如何打开豆瓣图书并打开Python相关的图书
from selenium import webdriverimport timeimport requests
start_url = "https://book.douban.com/subject_search?search_text=python&cat=1001&start=%25s0"# 控制chrome浏览器driver = webdriver.Chrome("./chromedriver/chromedriver.exe")# 输入网址driver.get(start_url)# 停一下,等待数据加载完毕time.sleep(2)# 获取网页内容Elementscontent = driver.page_source# 结束driver.quit()1234567891011121314151617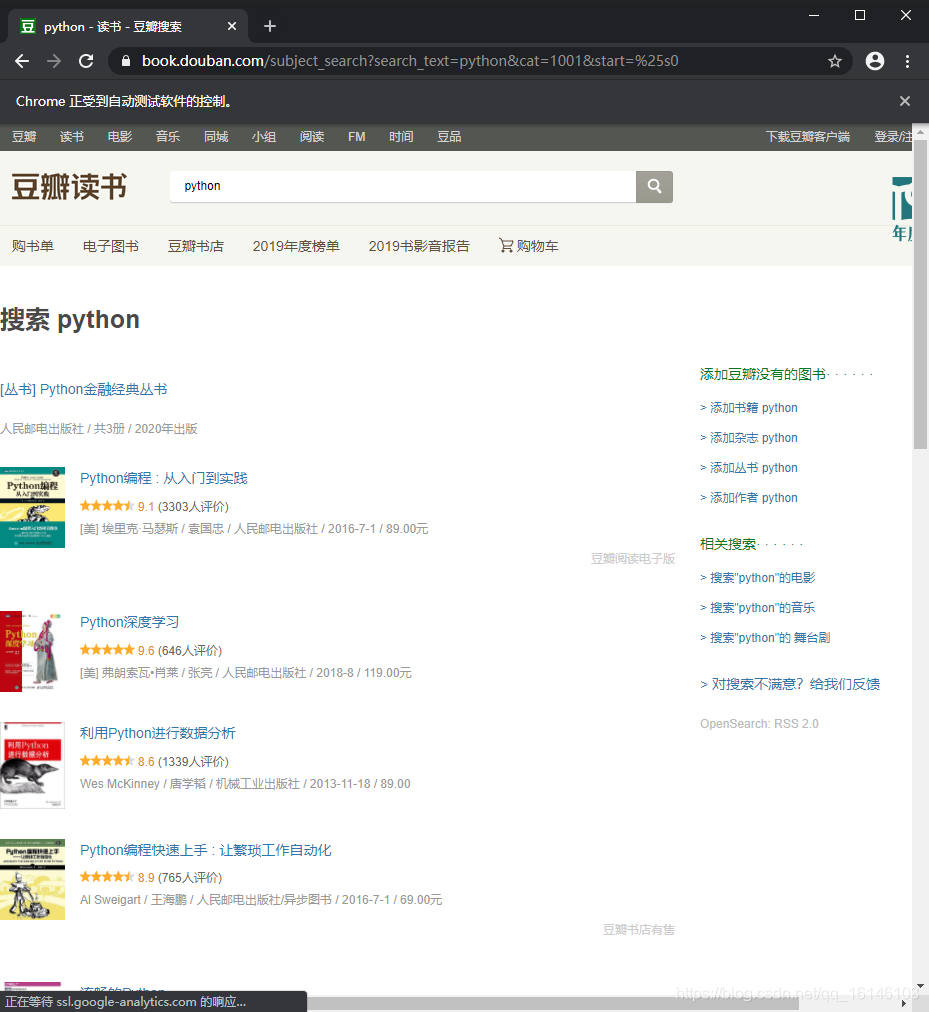
????,说明我们能够控制浏览器进行操作,那么这样我们就可以进行下一步操作了。
我们首先先提取数据
# 获取网页内容Elementscontent = driver.page_source# 提取数据print(content)12345
提取到数据后,我们查到里面是否存在我们所要爬取的图书,在此我们以《Python编程 : 从入门到实践》为切入点
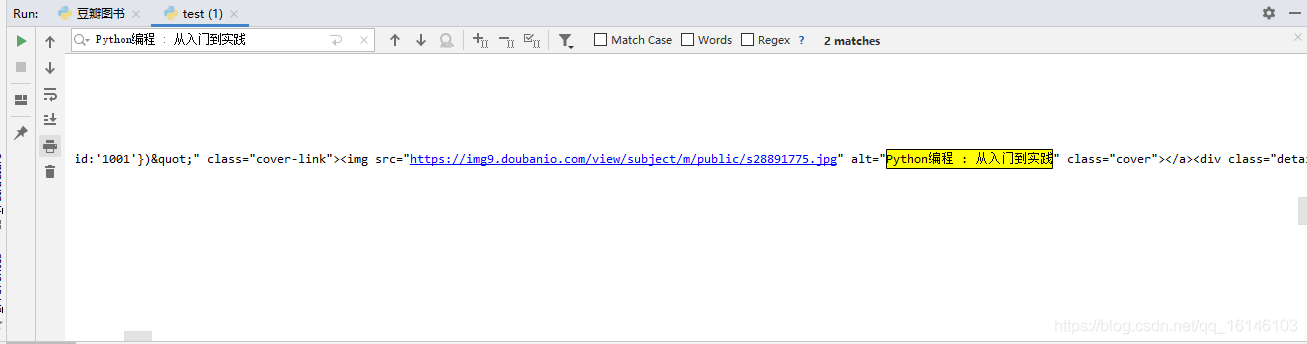
这个时候,我们首先要查看这个页面内是否存在有iframe
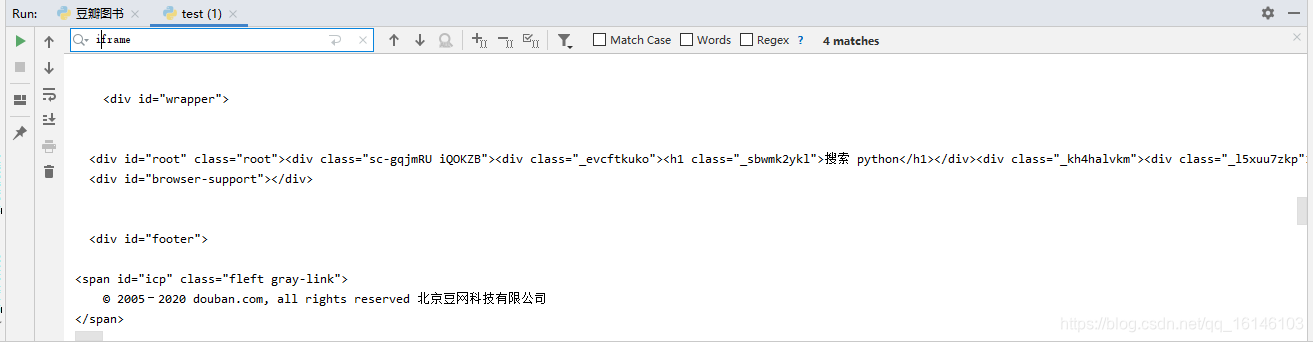
通过查找,我们发现在我们要爬取的部分是没有iframe存在的,因此我们可以直接使用xpath进行解析。
先查看网页源码,然后尝试解析
data_list = etree.HTML(content).xpath('//div[@class="item-root"]')# print(data_list)for data in data_list:
item = {}
item["name"] = data.xpath("./div/div[1]/a/text()")
item["score"] = data.xpath("./div/div[2]/span[2]/text()")
item["others"] = data.xpath("./div/div[3]/text()")
print(item)12345678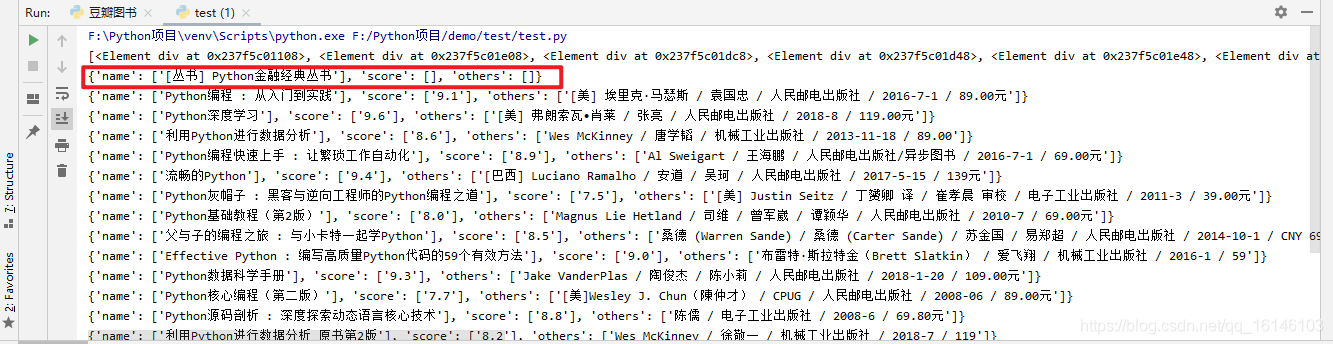
我们可以看到标红处,有的数据是获取不到的,这难道是我们代码有问题吗?其实我们的代码并没有问题。我们看下网页
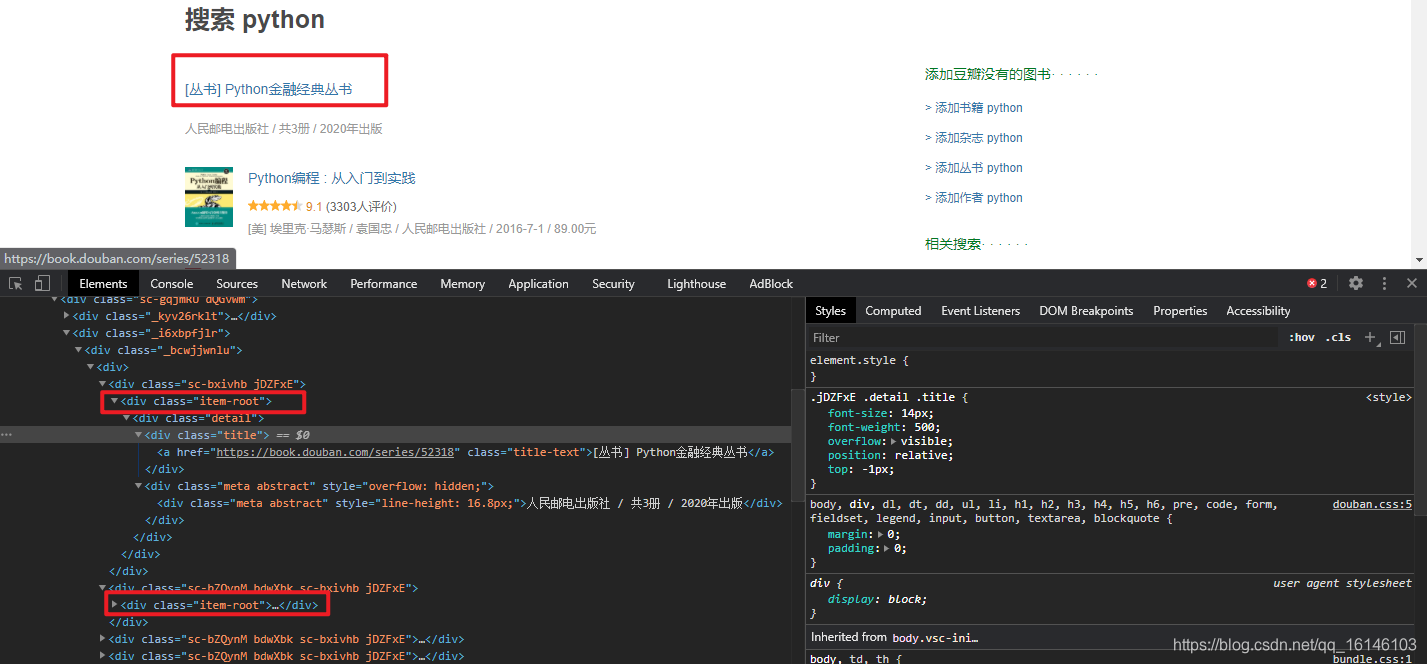
我们可以很清楚的看到,第一个<div class = "item-root"></div>并不是我们所要找的书籍,因此我们可以从第二个进行爬取。
修改后的代码如下
data_list = etree.HTML(content).xpath('//div[@class="item-root"]')[1:]# print(data_list)for data in data_list:
item = {}
item["name"] = data.xpath("./div/div[1]/a/text()")[0]
item["score"] = data.xpath("./div/div[2]/span[2]/text()")[0]
item["others"] = data.xpath("./div/div[3]/text()")[0]
print(item)12345678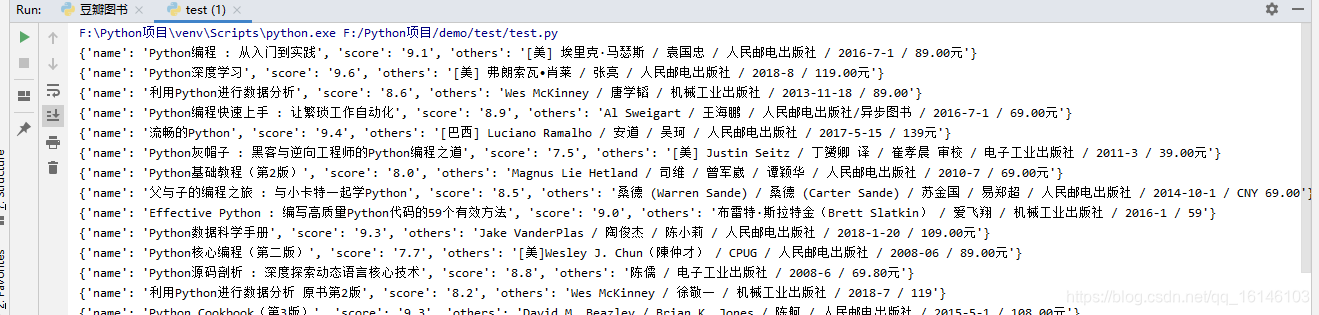
这个时候,就是我们需要的内容了。内容的问题解决了,下面就需要考虑自动翻页了。
我们通过查看网页的翻页过程,如下:
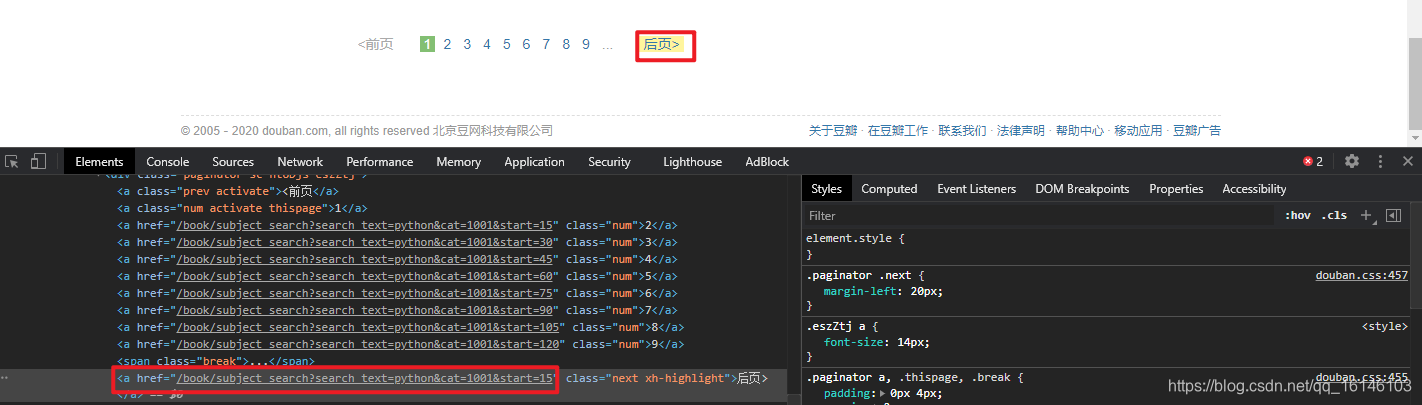
通过观察翻页部分的网页就够,我们可以以后页为关键词选取其中的href自动翻转到下一页。顺便再加上一个判定如果没有就自动停止。
我们下用xpath进行分析
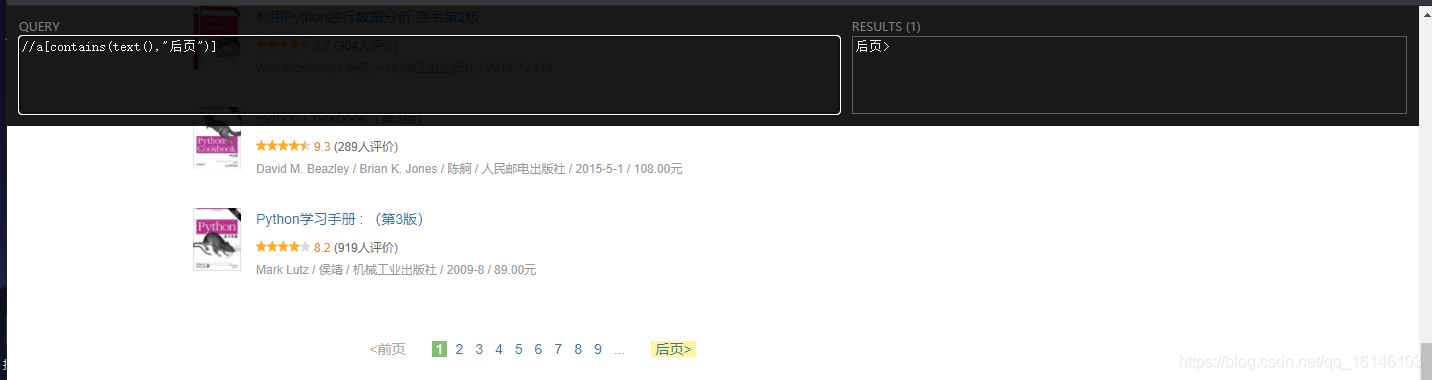
代码如下
# 找到后页
next = driver.find_element_by_xpath('//a[contains(text(),"后页")]')
# 判断
if next.get_attribute("href"):
# 单击
next.click()
else:
# 跳出循环
break123456789![]()
![]() 三、完整代码
三、完整代码
# encoding: utf-8'''
@author 李华鑫
@create 2020-10-09 11:34
Mycsdn:https://buwenbuhuo.blog.csdn.net/
@contact: 459804692@qq.com
@software: Pycharm
@file: 豆瓣图书.py
@Version:1.0
'''from selenium import webdriverfrom lxml import etreeimport osimport timeimport requestsimport reimport csv
start_url = "https://book.douban.com/subject_search?search_text=python&cat=1001&start=%25s0"# 控制chrome浏览器driver = webdriver.Chrome("./chromedriver/chromedriver.exe")# 输入网址driver.get(start_url)while True:
# 停一下,等待加载完毕
time.sleep(2)
# 获取网页内容Elements
content = driver.page_source # 提取数据
data_list = etree.HTML(content).xpath('//div[@class="item-root"]')[1:]
for data in data_list:
item = {}
item["name"] = data.xpath("./div/div[1]/a/text()")[0]
item["score"] = data.xpath("./div/div[2]/span[2]/text()")[0]
with open("./豆瓣图书.csv", "a", encoding="utf-8") as file:
writer = csv.writer(file)
writer.writerow(item.values())
print(item)
# 找到后页
next = driver.find_element_by_xpath('//a[contains(text(),"后页")]')
# 判断
if next.get_attribute("href"):
# 单击
next.click()
else:
# 跳出循环
break# 结束driver.quit()123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051![]()
![]() 四、运行结果
四、运行结果
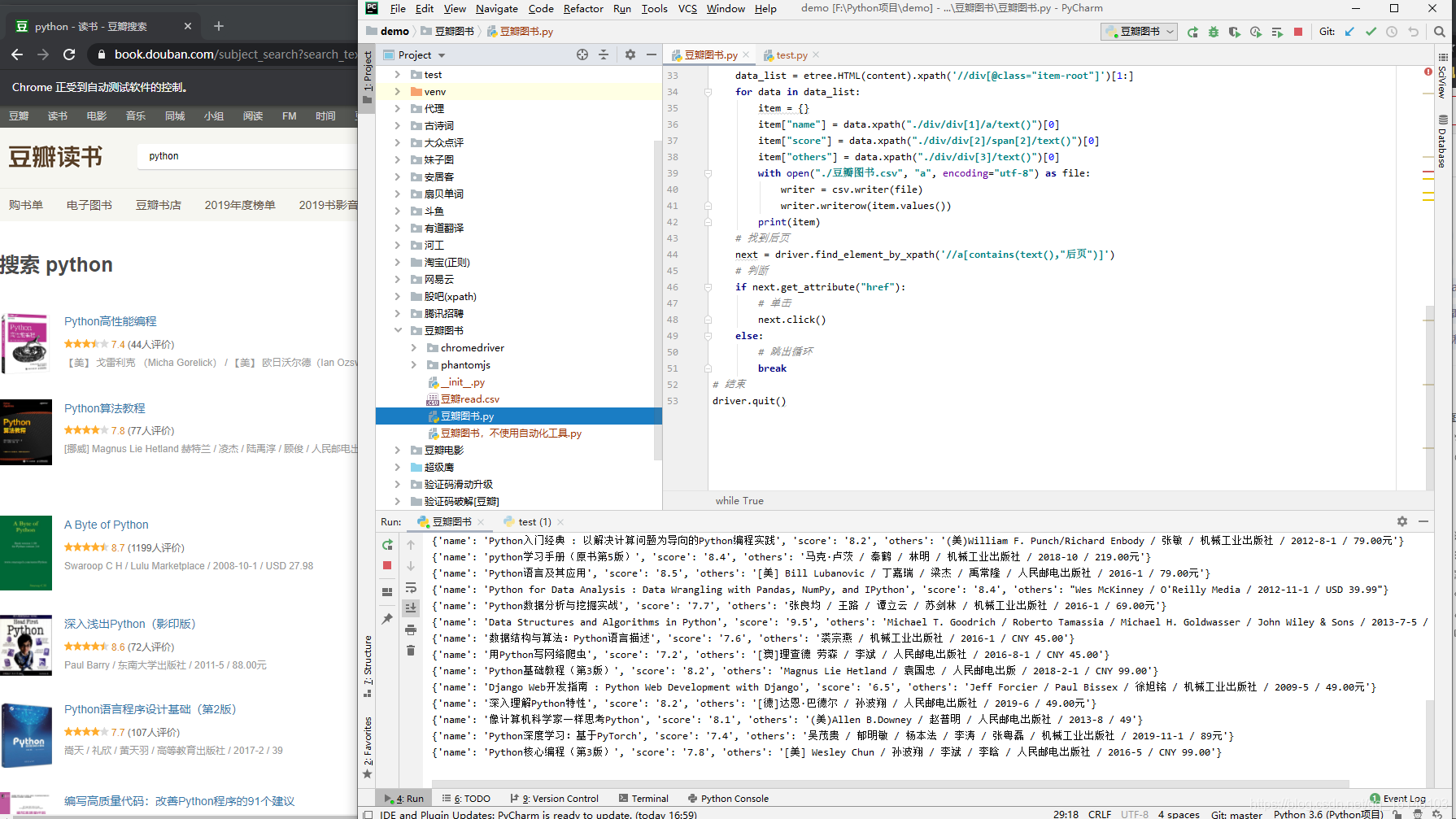
 美好的日子总是短暂的,虽然还想继续与大家畅谈,但是本篇博文到此已经结束了,如果还嫌不够过瘾,不用担心,我们下篇见!
美好的日子总是短暂的,虽然还想继续与大家畅谈,但是本篇博文到此已经结束了,如果还嫌不够过瘾,不用担心,我们下篇见!
转载自:CSDN 作者:不温卜火
原文链接:https://buwenbuhuo.blog.csdn.net/article/details/109380308
{var%20f='http://v.t.sina.com.cn/share/share.php?appkey=1515056452',u=z||d.location,p=['&url=',e(u),'&title=',e(t||d.title),'&source=',e(r),'&sourceUrl=',e(l),'&content=',c||'gb2312','&pic=',e(p||'')].join('');function%20a(){if(!window.open([f,p].join(''),'mb',['toolbar=0,status=0,resizable=1,width=440,height=430,left=',(s.width-440)/2,',top=',(s.height-430)/2].join('')))u.href=[f,p].join('');};if(/Firefox/.test(navigator.userAgent))setTimeout(a,0);else%20a();})(screen,document,encodeURIComponent,'','','http://www.shouhuola.com/static/css/dist/css/images/default.jpg', '推荐 爬虫大王 的文章《爬虫入门经典(十四) | 使用selenium尝试爬取豆瓣图书》','http://www.shouhuola.com/article-1981.html','页面编码gb2312|utf-8默认gb2312'));){kind=link}