{var%20f='http://v.t.sina.com.cn/share/share.php?appkey=1515056452',u=z||d.location,p=['&url=',e(u),'&title=',e(t||d.title),'&source=',e(r),'&sourceUrl=',e(l),'&content=',c||'gb2312','&pic=',e(p||'')].join('');function%20a(){if(!window.open([f,p].join(''),'mb',['toolbar=0,status=0,resizable=1,width=440,height=430,left=',(s.width-440)/2,',top=',(s.height-430)/2].join('')))u.href=[f,p].join('');};if(/Firefox/.test(navigator.userAgent))setTimeout(a,0);else%20a();})(screen,document,encodeURIComponent,'','','http://www.shouhuola.com/static/css/dist/css/images/default.jpg', '推荐 爬虫大王 的文章《快速入门网络爬虫系列 Chapter01 | 初识网络爬虫》','http://www.shouhuola.com/article-1985.html','页面编码gb2312|utf-8默认gb2312'));){kind=link}
一、什么是网络爬虫
网络爬虫英文名叫Web Crawler(又称Web Spiader),是一种自动浏览网页并采集你所需要的信息的程序,被广泛用于互联网搜索引擎(称为通用爬虫)。随着互联网的发展,爬虫技术不再局限于搜索领域,任何人都可以利用爬虫技术从互联网上获取自己想要的信息,如爬取电子书、商品价格等(称为垂直爬虫)。
何谓网络爬虫:
![]()
![]() 1、爬虫产生的背景
1、爬虫产生的背景
![]()
![]() 1.1、万维网的高速发展
1.1、万维网的高速发展
网页数量增加
网页承载的信息量增加
网络的拓扑结构复杂化
![]()
![]() 1.2、搜索引擎的需要
1.2、搜索引擎的需要
提供充分的搜索服务
提供精准的搜索结果
提供丰富的搜索信息
![]()
![]() 1.3、领域研究的需要
1.3、领域研究的需要
研究网络结构的需要网络关系
研究语言的需要语料材料
研究用户行为的需要用户资料
![]()
![]() 2、爬虫的概念
2、爬虫的概念
爬取网页:
按照一定的规则,自动地抓取万维网信息地程序或者脚本
抽取信息
部分或全部抽取抓取到的信息,使数据进一步结构化
存储信息
将获取到的信息保存到文件或数据库中
![]()
![]() 3、网络爬虫的对象
3、网络爬虫的对象
网站website
新闻类网站
社交类网站
购物类网站
所有你想爬的网站
API
天气类API
微博类API
只要你能被认证的API
流量数据
弹幕
只要有弹幕的地方
![]()
![]() 4、网络爬虫的重要性
4、网络爬虫的重要性
从工业角度看
数据驱动大量数据来源于网络爬虫
爬虫的效率决定信息更迭的速度
爬虫的准确性决定了服务的准确度
从研究角度看
研究领域需要干净的数据
研究领域需要不花钱的数据
几乎所有社交网络研究的benchmark数据都来自爬虫
可在工业领域独当一面
有数据的地方都有爬虫
爬虫是一个闭环的独立工程
所有的数据分析都是由爬虫开始
可自己做研究
自己收集数据
自己清理数据
自己运算算法
自己搞研究。
![]()
![]() 二、爬虫的使用范围
二、爬虫的使用范围

是数据产生二次价值的第一步
数据分析师的必备技能
网站测试者的好伙伴
我们在使用网络爬虫时,需要遵守Robots协议。
![]()
![]() 三、爬虫的分类
三、爬虫的分类
![]()
![]() 1、深度优先爬虫和广度优先爬虫
1、深度优先爬虫和广度优先爬虫
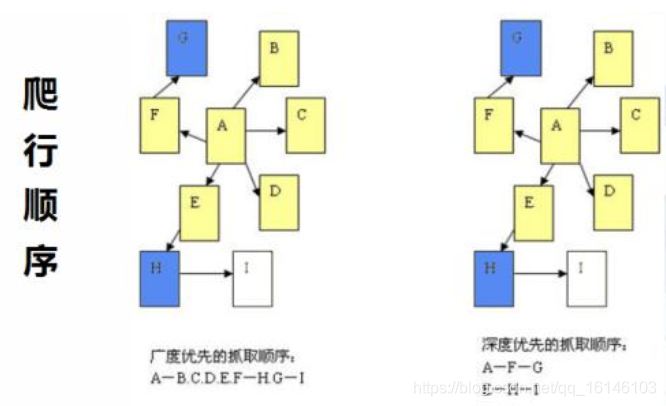
①深度优先爬虫
深度优先是指网络爬虫会从起始页开始,一个链接一个链接跟踪下去,处理完这条线路之后再转入下一个起始页,继续追踪链接。在一个HTML文件中,当一个超链被选择后,被链接的HTML文件将执行深度优先搜索,即在搜索其余的超链结果之前必须先完整地搜索单独地一条链。
②广度优先爬虫
广度优先,有人也叫宽度优先,是指将新下载网页发现地链接直接插入到待抓取URL队列的末尾,也就是指网络爬虫会先抓取起始页中的所有网页,然后在选择其中的一个连接网页,继续徐抓取在此网页中链接的所有网页。
![]()
![]() 2、静态网页爬虫和动态网页爬虫
2、静态网页爬虫和动态网页爬虫
①静态网页爬虫
面向网页读取过程中就完成加载的网页,此类网页的主要信息会在网页加载过程中直接显示在页面上,比如一些新闻网站和比较老的网站。面向静态网页的爬虫页面逻辑比较简单,几行代码就可以完成爬取。
②动态网页爬虫
网页读取过程中需要依赖额外的加载过程,比如JavaScript或者jQuery,使用静态网页的爬取方法可能获取不到数据,需要模拟动态加载过程。
网页登录过程分页,需要模拟下拉、点击等操作才能加载剩余数据
需要登录
![]()
![]() 3、泛用和主题爬虫
3、泛用和主题爬虫
①泛用爬虫
普通的没有策略和着重爬取的爬虫,由于可能会爬取一些无用的数据,效率比较低
②主题爬虫
指选择性地爬取那些于预先定义好地主题相关页面地网络爬虫。和通用网络爬虫相比,聚焦爬虫只需要爬行与主题相关地页面,极大地节省了硬件和网络资源,保存地页面也由于数量少而更新块,还可以很好地满足一些特定人群对特定领域信息的需求。
![]()
![]() 四、爬虫的基本架构
四、爬虫的基本架构
网络爬虫的基本架构
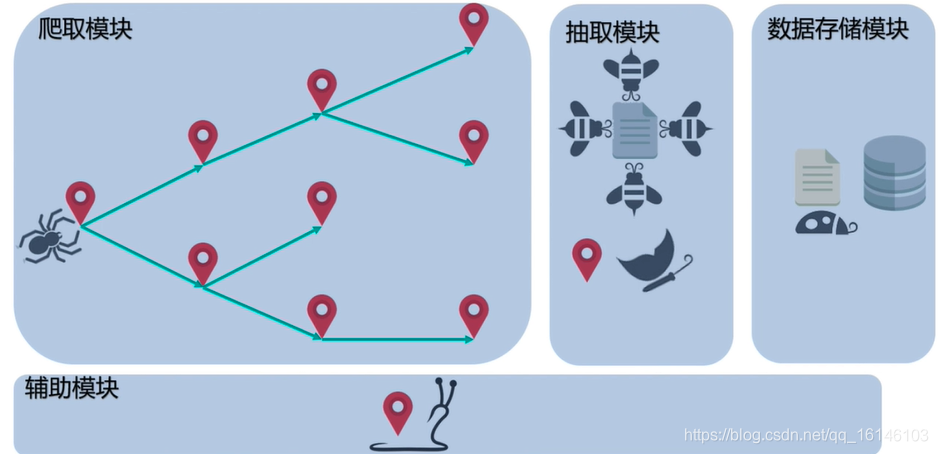
需要和实现有一部分我们需要用到辅助模块。
爬虫的爬取过程:
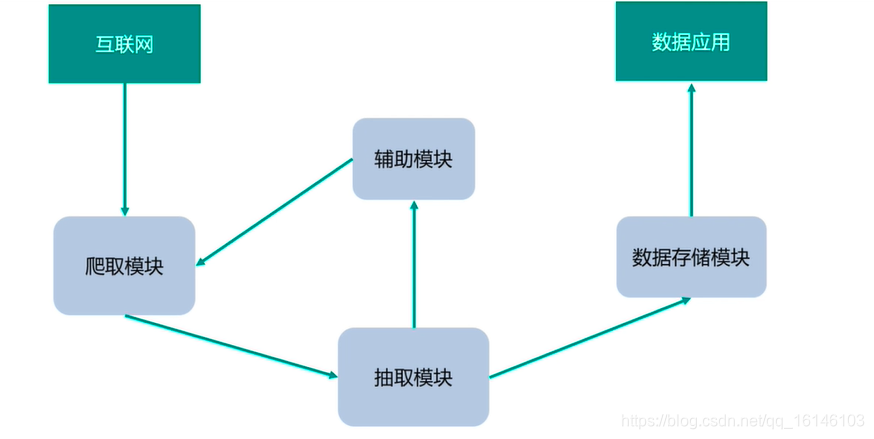
爬虫的爬取过程解析:
①爬取模块——从万维网上获取数据
从一个URL开始批量的获取数据
将数据从互联网的海量信息中拉取到爬虫系统中进行处理
②抽取模块——处理获取的数据抽取指定的信息
抽取URL加入队列,使程序持久化
将原本被HTML、XML、JSON结构化的数据进一步结构化,方便数据库存储
③数据存储模块——将抽取的信息存入指定格式的载体
将抽取的信息存入txt、csv、数据库等常见的数据存储中
为爬虫提供数据索引,使得爬虫队列可以通过读取数据存储的方式控制爬虫运转
④辅助模块——持久化、队列与多线程
持久化
使爬虫可以尽可能长时间稳定运转
控制爬取速度,合理规避简单反爬规则队列
控制爬虫爬取的顺序,实现深度或广度优先策略
承载URL,提供去冲、排序等操作多线程
提高爬虫效率
转载自:CSDN 作者:不温卜火
原文链接:https://buwenbuhuo.blog.csdn.net/article/details/105164216