{var%20f='http://v.t.sina.com.cn/share/share.php?appkey=1515056452',u=z||d.location,p=['&url=',e(u),'&title=',e(t||d.title),'&source=',e(r),'&sourceUrl=',e(l),'&content=',c||'gb2312','&pic=',e(p||'')].join('');function%20a(){if(!window.open([f,p].join(''),'mb',['toolbar=0,status=0,resizable=1,width=440,height=430,left=',(s.width-440)/2,',top=',(s.height-430)/2].join('')))u.href=[f,p].join('');};if(/Firefox/.test(navigator.userAgent))setTimeout(a,0);else%20a();})(screen,document,encodeURIComponent,'','','http://www.shouhuola.com/static/css/dist/css/images/default.jpg', '推荐 爬虫大王 的文章《快速入门网络爬虫系列 Chapter04 | URL管理》','http://www.shouhuola.com/article-1990.html','页面编码gb2312|utf-8默认gb2312'));){kind=link}
一、URL去重
![]()
![]() 1、URL去重的重要性
1、URL去重的重要性
网络爬虫爬取重复的URL链接,会下载相同网页的内容,造成计算资源的消耗,给服务器带来不必要的负担
解决重复下载的问题,可以提高爬虫效率,减少不必要的资源消耗
深度优先(DFS)和广度优先(BFS)的抓取策略,遇到的网页链接重复是因为网页的链接形成一个闭环
无论是BFS还是DFS都不可避免地反复遍历这个环中的URL,从而造成无限循环
为了避免无限循环,更需要取出重复的URL
所有的URL去重都是在内存上进行的——>可提速
![]()
![]() 2、Hash去重
2、Hash去重
Hash,也称为哈希,散列,是把任意长度的输入,通过给定的函数,转换为长度固定的输出
Hash的实质是一种压缩映射,散列值的空间通常远小于输入的空间
不需要遍历所有的元素,提高了查找效率
举个例子:
每个散列值对应一个桶,同一个桶存放的是所有散列值相同的元素
88经过hash函数之后,得到一个散列值8,所以就把88放在8号桶中
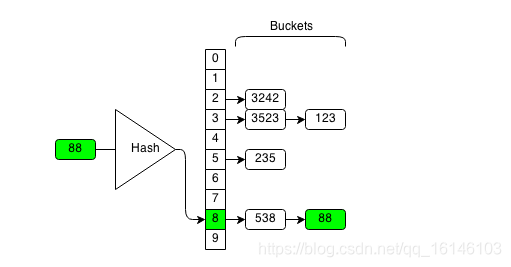
Hash算法是检测一个元素是否存在的高效算法。对于一个输入,我们只需要计算其散列值,并在这个散列值对应的桶中查找元素是否存在就行了,不需要遍历所有所有元素。如在上图中,要检测数字88是否存在,只需要检测88号桶中是否存在数字88即可。
![]()
![]() 2.1、常用的构造Hash函数的方法
2.1、常用的构造Hash函数的方法
直接寻址法:取关键字或关键字的某个线性函数值为散列地址(并不常用)
数字分析法:抽取关键字中的一部分来计算存储位置(适用于关键词较长的情况)
平方取中法:关键字先平方,截取中间X位作为存储位置(适用于不知道关键字的分布)
折叠法:拆分关键字
随机数法:使用随机数作为存储位置
除留余数法:适用余数作为存储位置
![]()
![]() 2.2、Hash去重所遇到的问题及解决方法
2.2、Hash去重所遇到的问题及解决方法
问题:
通常hash函数映射得到的散列值,并不能保证唯一性
不同的输入可能会得到相同的散列值,这种现象称为Hash碰撞
解决方法:
开放寻址法
拉链法
1、开放寻址法
开放寻址:所有的元素经过Hash映射后都存放在散列表中
当新的元素进入散列表中,检查散列表的各项,直到发现有“空”的位置,将该元素放入为止
eg:学校的厕所门,有人门是关着的,没人门是能拉开的,就这样慢慢能找到“空”的位置常用的开放寻址方法有以下三种:
①线性探测:h(k,i) = (h’(k)+i) mod m, 0 ≤ i ≤ m-1
②二次探测:h(k,i) = (h’(k)+i*i)% m, 0 ≤ i ≤ m-1
③双重散列:h(k,i) = (h1(k)+ih2(k)) mod m, 0 ≤ i ≤ m-1开发寻址法通过占用散列表的其他空闲位置,来解决Hash碰撞的问题
这样做会导致后续加入的元素发生Hash碰撞的风险升高
对于采用开放寻址法的Hash散列表来说,需要控制它的装载因子
装载因子是哈希表保存的元素数量和哈希表容量的比。采用开放寻址的Hash散列表的装载因子不大于0.5
2、拉链法
拉链法:将Hash散列表看作一个链表数组。数组中的位置要么为空,要么指向散列到该位置的链表
链表法把元素添加到链表中来解决Hash碰撞。具有相同散列值的元素会插入相对应的链表中
拉链法的代价不会超过向链表中添加元素,也无需执行再散列
拉链法的实现过程: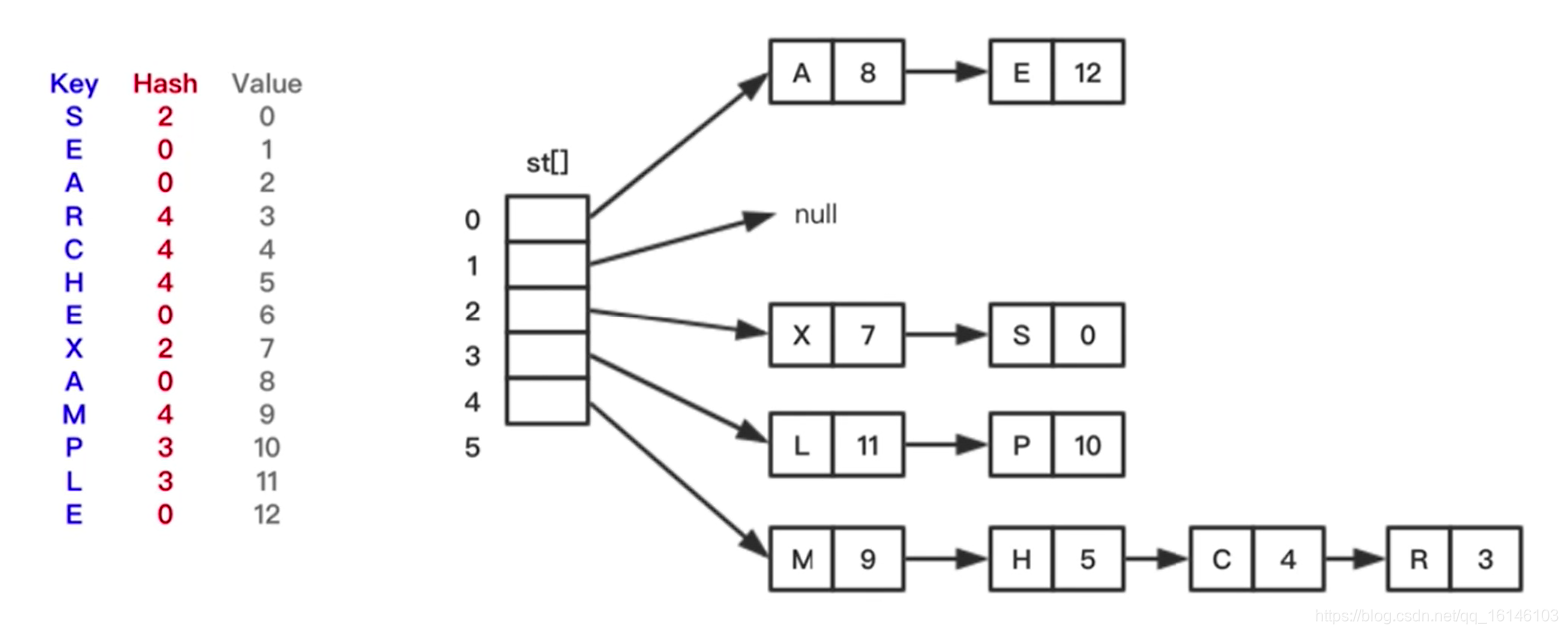
拉链法的优点
优点:
解决了Hash表堆叠的现象,减少了平均查询的长度
在单链表中执行更改这样的操作相比于开放寻址法更为简单,我们只需要把删除的元素的地址前后关联一下即可
两者对比:
数据量比较小的时候开放寻址法是不需要重新开辟空间的,当数据量比较大的时候,开放寻址法要不停的按照装填因子成倍的申请新的空间,会造成存储空间过大。
![]()
![]() 3、使用Hash来对URL进行去重
3、使用Hash来对URL进行去重
首先要设置一个
Python的数据类型—集合,来保存已经爬取过的URL
![]()
![]() 3.1、为什么要用集合
3.1、为什么要用集合
Python语言的set:
集合对象是一组无序排列的可哈希的值
集合本身无序,不能创建索引,执行切片操作
集合内元素不重复
集合元素为不可变对象
![]()
![]() 3.2、具体实现的逻辑
3.2、具体实现的逻辑
用深度(或宽度)优先递归地搜寻新地URL
如果新发现的URL包含在这个集合中就舍弃
否则加入到未爬取队列中
eg:
![]()
![]() 3.3、统计URL管理器中的URL数量
3.3、统计URL管理器中的URL数量
所得结果如下图:
![]()
![]() 3.4、略加修改的代码:
3.4、略加修改的代码:

去重的重要性:
因为网站结构的关系,它会进行重复的引用。
上面的代码可以防止无穷循环,但是比较多时就会体现出劣势
如果URL过多,那么占用的内存空间也会很大
总结:
优点:速度快
缺点:占用大量内存空间
![]()
![]() 2、URL压缩
2、URL压缩
URL压缩基于MD5算法对URL进行加密压缩,生成散列值,来判断URL的唯一值
MD5是一种基于Hash的加密算法,它可以压缩URL生成:
①一个压缩的128位整数
②一个Hash物理地址使用MD5算法进行Hash映射,发生Hash碰撞的几率小,为网络爬虫抓取所使用
使用第三方库hashlib来实现MD5映射算法
![]()
![]() 三、Bloom Filter
三、Bloom Filter
Bloom Filter是在1970年代由Bloom出的一种多哈希函数映射的快速查找算法
它是一种空间效率高的随机数据结构
使用位数组表示一个集合
判断一个元素是否属于这个集合
Bloom Filter的基本思路是:通过多个不同的Hash函数来解决“冲突”
Bloom Filter主要包含以下两个部分:
1个比特数组:长度为m,并初始化为0
k个hash函数:进行URL哈希,哈希值范围[0,m-1]
Bloom Filter的任务是,判断URL是否已经抓取过
URL哈希之后,得到k个范围在[0,m-1]的值,然后判断这k个位置上是否都是1,如果都是1,就认为这个URL已经抓取过,否则没有抓取
在下图中,有三个hash函数。假设x,y,z是已经抓取过的URL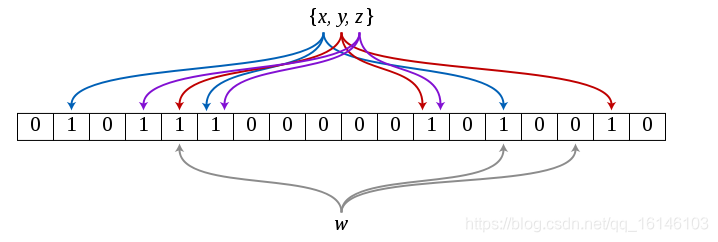
w是要判断的URL:
可以看到,w经过hash之后三个对应的位置上有一个不是1,我们可以肯定这个URL没有被抓取过
![]()
![]() 3.1、Bloom Filter的缺点
3.1、Bloom Filter的缺点
Bloom Filter的查询时间和空间效率虽高,但是有以下缺点:
Bloom Filter集合中的元素无法删除
如何确定位数组的大小以及hash函数的个数
Bloom Filter会出现错误判断,无法达到零错误
![]()
![]() 3.2、Bloom Filter通常的应用场景
3.2、Bloom Filter通常的应用场景
设置黑名单
过滤垃圾短信
检测重复URL
Python中有很多Bloom Filter的开源实现,我们这里选用pybloom工具包
pybloom的主要类和函数有:
BloomFilter(capacity,error_rate)
ScalableBloomFilter(initial_capacity,error_rate,mode)
![]()
![]() 1、举例
1、举例
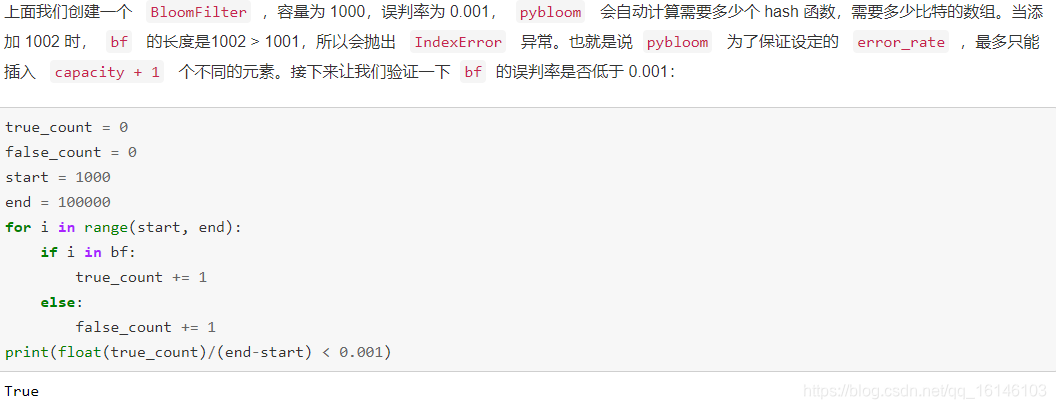
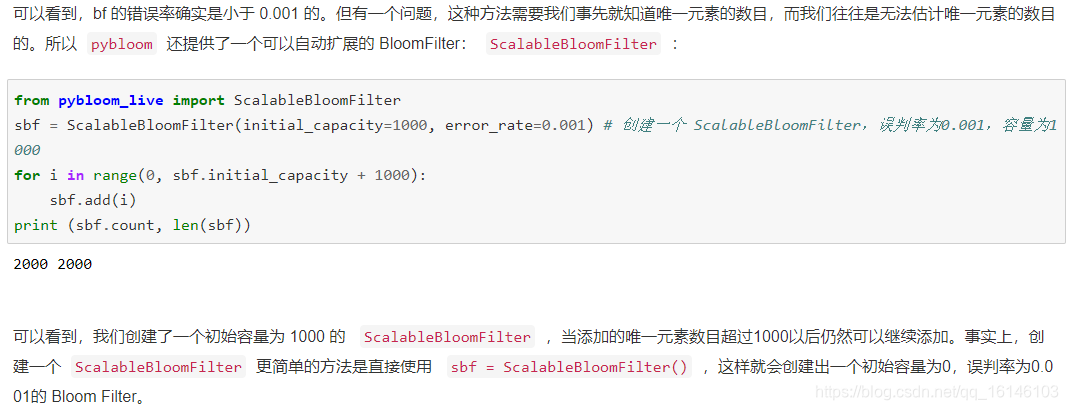
创建一个Bloom Filter:
容量为1000,误判率为0.001,pybloom自动计算需要多少个hash函数,需要多少比特的数组

转载自:CSDN 作者:不温卜火
原文链接:https://blog.csdn.net/qq_16146103/article/details/105184265