一、网页介绍
![1]()
HTML的标签数:
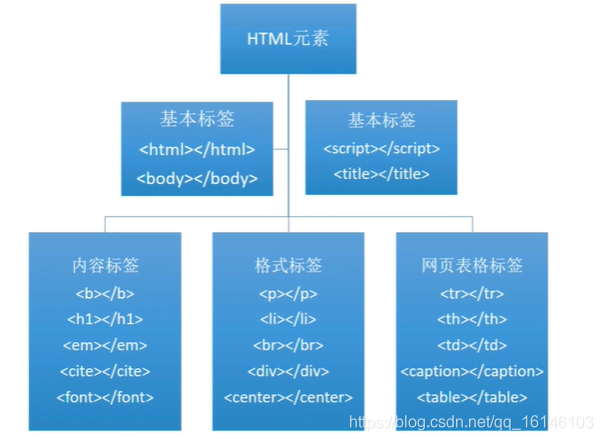
HTML文件的内容均包含在标签中:

嵌入标签的内容作为HTML的头
嵌入标签的内容为文件的内容主题
![]()
![]() 3、从网页中提取数据
3、从网页中提取数据
借助Python网络库,构建的爬虫可以抓取HTML页面的数据
从抓取的页面数据中提取有价值的数据,有以下方式:
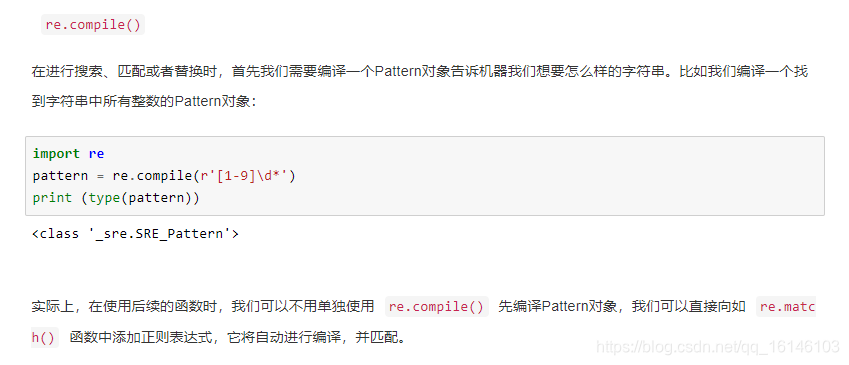
正则表达式
lxml
BeautifulSoup
![]()
![]() 二、正则表达式
二、正则表达式
面对复杂的HTML页面,经常需要从中抽取需要的信息,比如身份证号等
使用简介的字符串表达式,来去匹配这些信息:
匹配居民身份证
(^\d{15}$)|)^\d{17}([0-9]|X)$)
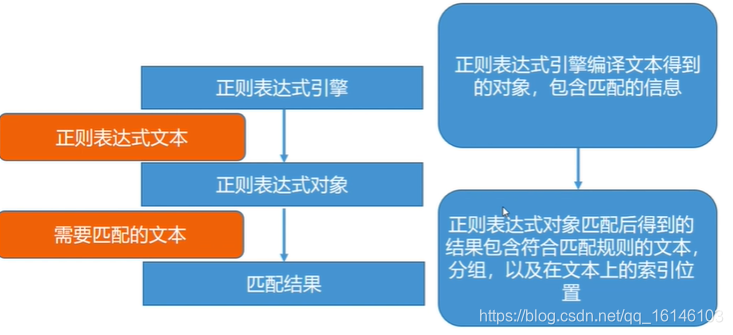
正则表达式有独立的语法以及处理引擎,在支持正则表达式的语言中,正则表达式的语法一致
不同的编程语言实现支持的语法数量不同:
![5]()
![]()
![]() 2、正则表达式的语言
2、正则表达式的语言
{var%20f='http://v.t.sina.com.cn/share/share.php?appkey=1515056452',u=z||d.location,p=['&url=',e(u),'&title=',e(t||d.title),'&source=',e(r),'&sourceUrl=',e(l),'&content=',c||'gb2312','&pic=',e(p||'')].join('');function%20a(){if(!window.open([f,p].join(''),'mb',['toolbar=0,status=0,resizable=1,width=440,height=430,left=',(s.width-440)/2,',top=',(s.height-430)/2].join('')))u.href=[f,p].join('');};if(/Firefox/.test(navigator.userAgent))setTimeout(a,0);else%20a();})(screen,document,encodeURIComponent,'','','http://www.shouhuola.com/static/css/dist/css/images/default.jpg', '推荐 爬虫大王 的文章《快速入门网络爬虫系列 Chapter07 | 正则表达式》','http://www.shouhuola.com/article-1995.html','页面编码gb2312|utf-8默认gb2312'));){kind=link}
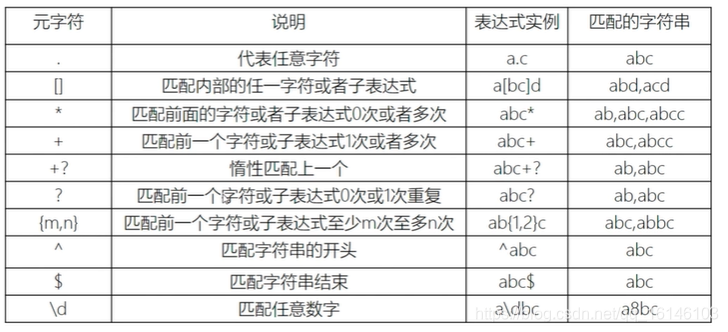
正则表达式语言由两种基本字符类型组成
原生(正常)文本字符
元字符
![]()
![]() 3、正则表达式的分组
3、正则表达式的分组
使用正则表达式匹配重复字符串,只需在字符后面加上相应的元字符
如果要匹配重复的字符串,使用小括号()把目标字符串包裹起来
(abc)?可以匹配0个或者多个字符串abc
分组可以分为两种形式:
捕获组和非捕获组
![]()
![]() 4、正则表达式的捕获
4、正则表达式的捕获
小括号包裹起来的表达式去匹配字符串,匹配的结果可以在后续的匹配过程中使用
把表达式中的括号进行编号,从左到右,以左括号出现的前后顺序为准,第一个出现的分组,组号即为1.
组号0代表正则表达式整体


下面依次进行说明
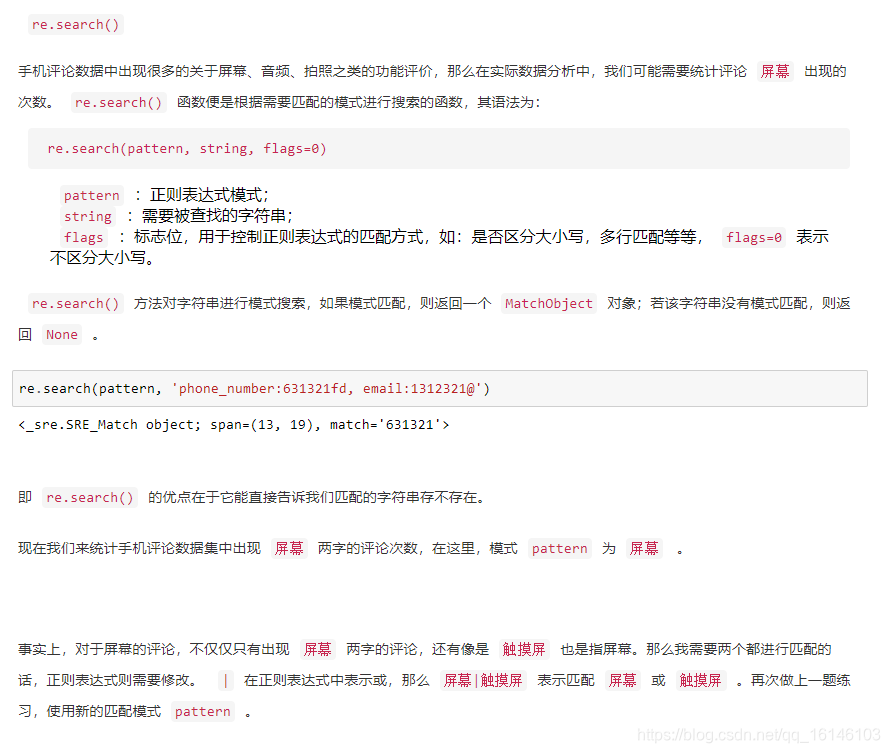
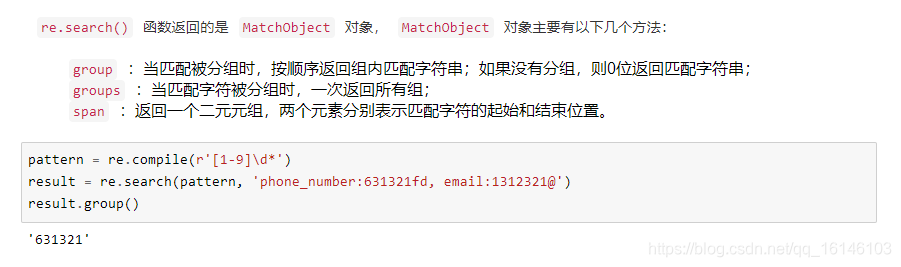
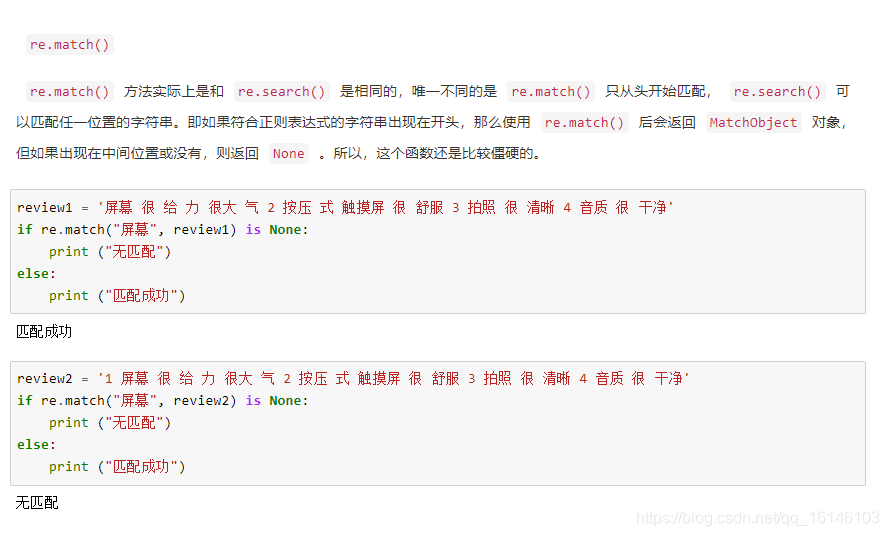
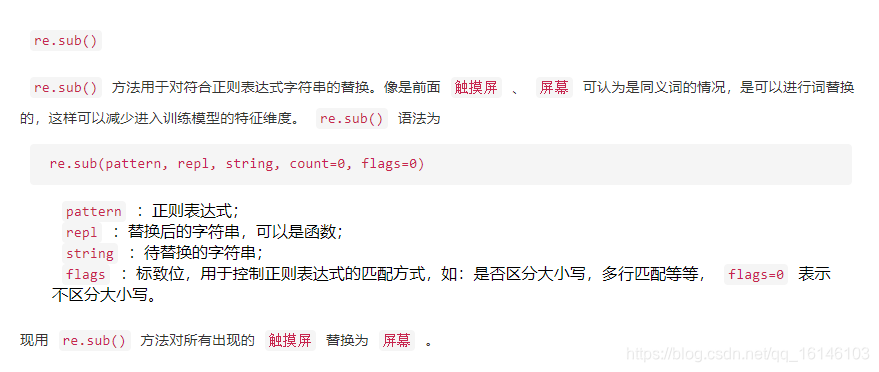
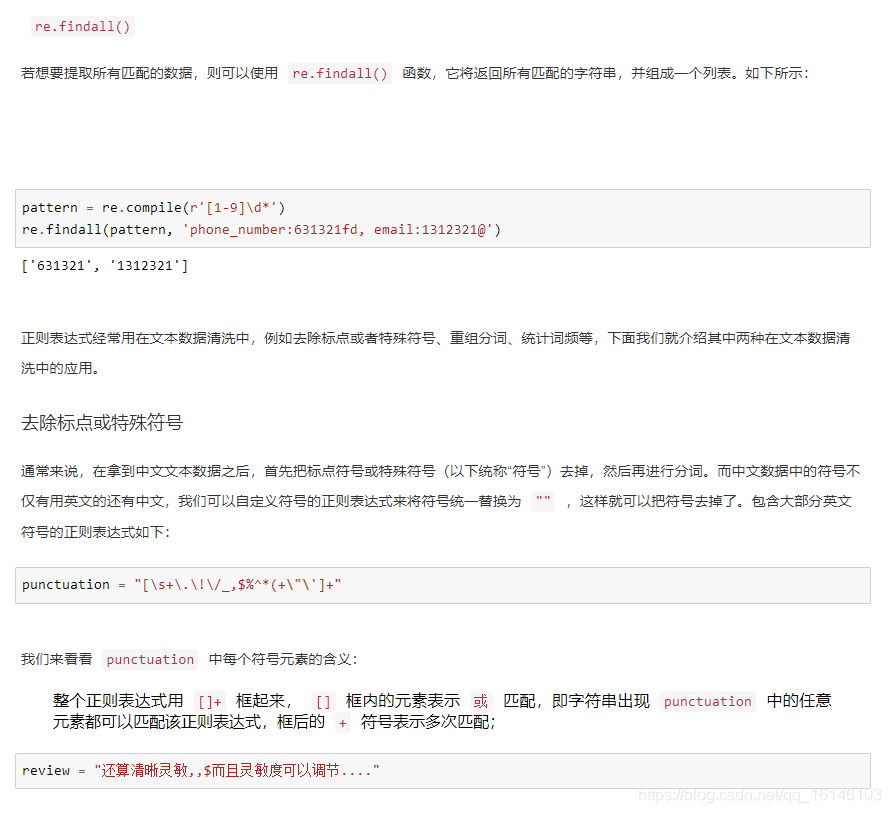
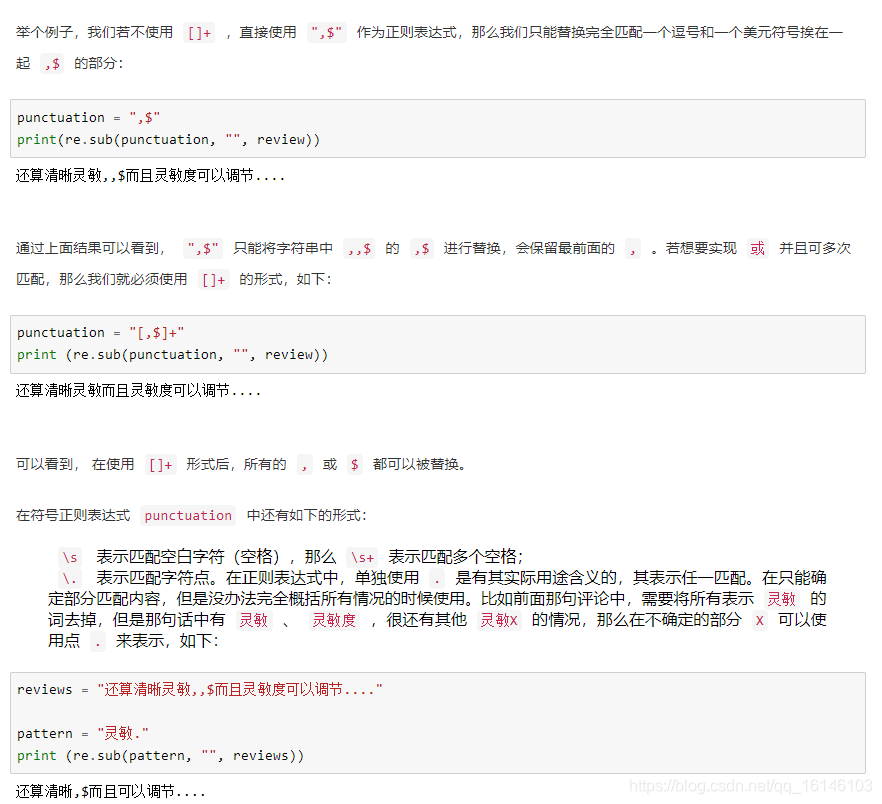
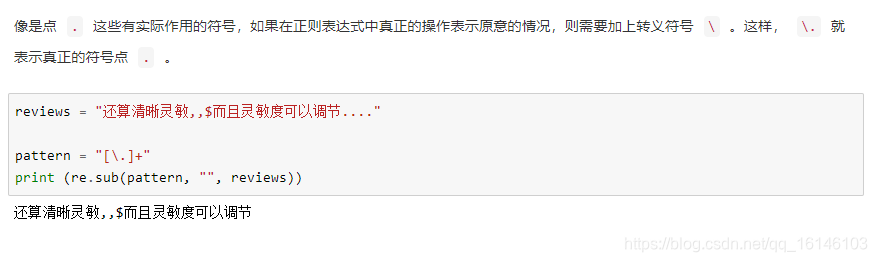
下面依次进行说明
转载自:CSDN 作者:不温卜火
原文链接:https://blog.csdn.net/qq_16146103/article/details/105229330