{var%20f='http://v.t.sina.com.cn/share/share.php?appkey=1515056452',u=z||d.location,p=['&url=',e(u),'&title=',e(t||d.title),'&source=',e(r),'&sourceUrl=',e(l),'&content=',c||'gb2312','&pic=',e(p||'')].join('');function%20a(){if(!window.open([f,p].join(''),'mb',['toolbar=0,status=0,resizable=1,width=440,height=430,left=',(s.width-440)/2,',top=',(s.height-430)/2].join('')))u.href=[f,p].join('');};if(/Firefox/.test(navigator.userAgent))setTimeout(a,0);else%20a();})(screen,document,encodeURIComponent,'','','http://www.shouhuola.com/static/css/dist/css/images/default.jpg', '推荐 爬虫大王 的文章《快速入门网络爬虫系列 Chapter10 | 数据结构化存储》','http://www.shouhuola.com/article-2001.html','页面编码gb2312|utf-8默认gb2312'));){kind=link}
一、结构化过程
![]()
![]() 1、非结构化数据
1、非结构化数据
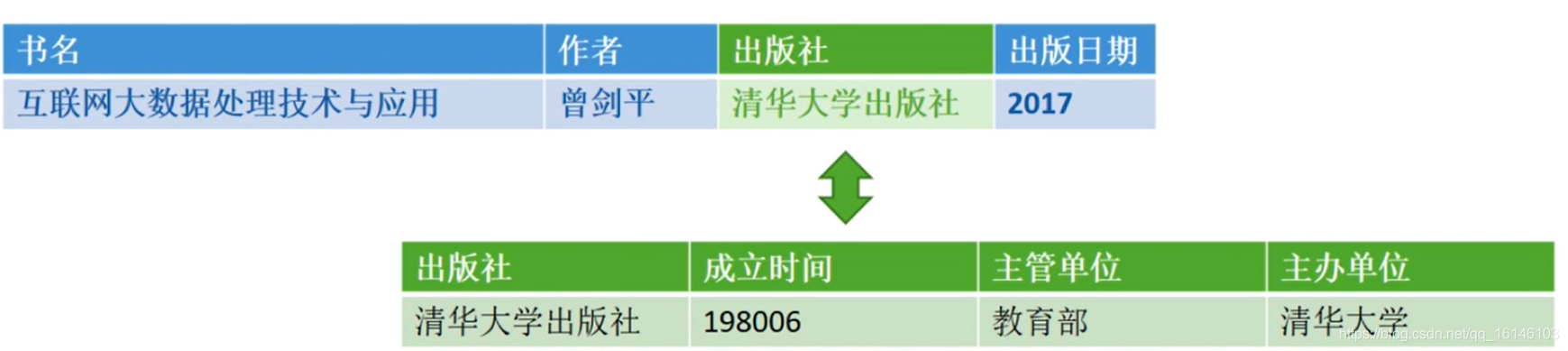
“《互联网大数据处理技术与应用》一书是由曾剑平编著,并由清华大学出版社于2017年出版。”
“ 清华大学出版社成立于1980年6月,是由教育部主管、清华大学主办的综合出版单位。”
![]()
![]() 2、半结构化数据
2、半结构化数据
(书名:互联网大数据处理技术与应用;作者:曾剑平;出版社:清华大学出版社;出版日期:2017)
(出版社:清华大学出版社;成立时间:198006;主管单位:教育部;主办单位:清华大学)
![]()
![]() 3、结构化数据
3、结构化数据
![]()
![]() 二、怎样数据结构化
二、怎样数据结构化
![]()
![]() 1、明确数据需求
1、明确数据需求
需要抽取什么数据
存放成什么格式
怎么存
![]()
![]() 2、选择数据结构
2、选择数据结构
半结构化:XML、JSON
结构化:数据库
![]()
![]() 3、怎么存
3、怎么存
文件:单独还是一起存放,如何发展数据关系
数据库:数据库设计
![]()
![]() 三、半数据化结构
三、半数据化结构
![]()
![]() 3.1、JSON
3.1、JSON
API常用格式
数据结构简单
有Python Json库支持
可以和Python字典结构相互转化
![]()
![]() 3.2、XML(可广泛应用)
3.2、XML(可广泛应用)
可扩展标记语言,标记通用标记语言的子集,是一种用于标记电子文件使其具有结构化的标记语言
![]()
![]() 1、XML的特性
1、XML的特性
可扩展标记语言可以对文档和数据进行结构化处理,从而能够在部门、客户和供应商之间进行交换,实现动态内容生成,企业集成和应用开发
准确的搜索
方便的传送软件组件
更好的描述一些事物
设计宗旨是传输数据,而不是显示数据
标签没有背被预定义,需要自行定义标签
具有自我描述性
1、一个简单的XML例子
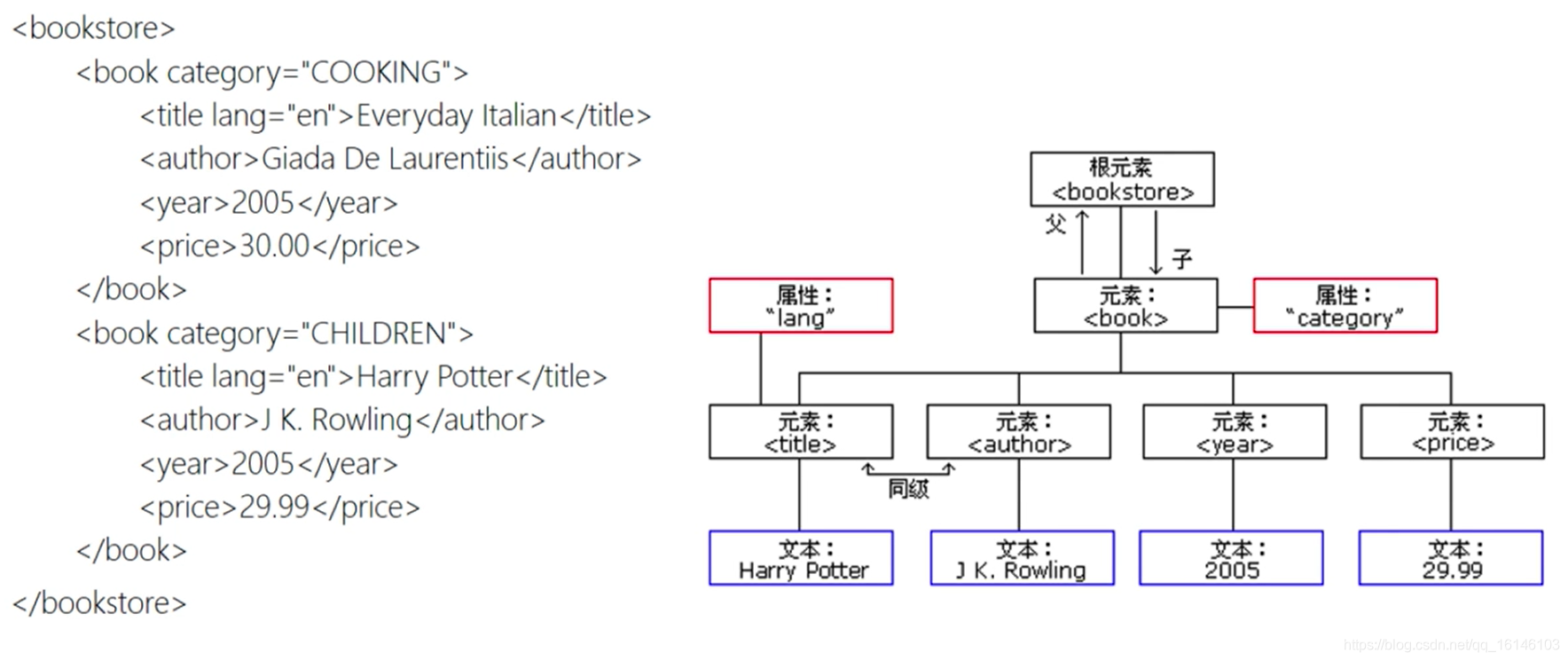
2、使用xml.etree生成xml
在这里主要使用xml.etree这个子包

爬虫场景中可以使用
json+xml迭代完成xml与json的相互转化
使用xmltodict包
转载自:CSDN 作者:不温卜火
原文链接:https://blog.csdn.net/qq_16146103/article/details/105264905