2020-11-05 20:43发布
1、hadoop简单介绍 Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。 Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,则MapReduce为海量的数据提供了计算。 2、hadoop版本说明 hadoop现在分两个版本1.0和2.0(17年1月推出了3.0版本 在这先不介绍) 1.0版本,hadoop有两个核心模块:HDFS+MapReduce 2.0版本,hadoop有三个核心模块:HDFS+Yarn+MapReduce yarn 是资源协调管理框架。 1.0时hadoop只有一种计算框架。在2.0之后推出yarn后,既可以运行mr,也可以运行Spark,storm等其他框架。 3、Hadoop安装 模式: 1、单机模式,不能使用HDFS,只能使用MR,一般用于测试MR代码 2、伪分布模式,也就是用一台机器,用多个进程模拟多台机器。HDFS和MR都能使用 3、完全分布模式,用多个机器或多个虚拟机来搭建(之后有一节专门来说) 实现步骤: 1、准备一台虚拟机,要求工作内存最低1G,否则有可能出现错误。 2、关闭防火墙(注意,这只是自己用的时候为了简单,在工作中是不能关闭的 只要打开hadoop所需要的几个端口就可,50070、90000、50020等端口。 3、配置主机名hostsname、配置hosts文件,为了之后使用方便 4、配置免密钥登陆,方便之后的登陆跨服务器传文件登陆用 5、安装配置jdk,因为hadoop就是java开发的需要jdk环境 6、最后安装配置hadoop 安装步骤: 1、关闭防火墙:service iptables off 这个指令关闭防火墙之后,重启后防火墙还会开启,执行chkconfig iptables off这个命令之后重启也不会开启了(这个只是自己的虚拟机下使用,生产线上是不能的,当然这些都不是我这个小兵所关心的)。 2、配置hostsname等: vim /etc/sysconfig/network 配置hosts 内容 vim /etc/hosts 3、配置免密钥登陆: 执行 ssh-keygen 一直回车 ,生成节点的公钥和私钥,生成的文件会放在/root/.ssh的目录下。 然后把公钥发往远程机器,比如发往本机,本机免密钥登陆:ssh-copy-id root@hadoop,此时,hadoop节点就是把收到的hadoop密钥保存在/root/.ssh/authorized_keys这个文件里,这个文件相当于访问的白名单,凡是在此白名单存储的密钥对应的机器,登陆时是免密码登陆的。两个机器分别进行一次则两方登陆时都是免密码的,之后做真分布式hadoop时要进行多个免密钥登陆的。 4、安装配置jdk 在这里就不写了。 5、安装配置hadoop 在这我是用的hadoop安装包进行的安装的。 我的安装包是hadoop-2.7.1的,我会上传的。 执行 tar -zxvf hadoop-2.7.1_64bit.tar.gz,之后解压生成相应的文件。其中由多个目录: bin目录:命令脚本 etc/hadoop:存放hadoop的配置文件(之后修改配置文件,将在这里进行) lib目录:hadoop运行的依赖jar包 sbin目录:启动和关闭hadoop命令都在这里 libexec目录:存放的也是hadoop命令,但是一般不适用。 修改配置文件 切换到 etc/hadoop里面修改。 配置hadoop-env.sh 这个文件里写的是hadoop的环境变量,主要修改hadoop的java_home路径。在这里面主要修改export java_home 写成自己jdk的安装目录,export hadoop_conf_dir 写成hadoop的安装目录 配置core-site.xml 配置如下:
配置hdfs-site.xml 如下:
修改配置mapred-site.xml 这个文件初始时是没有的,有的是模板文件mapred-site.xml.temple 复制这个文件命名为mapred-site.xml 修改就可以了。配置如下: yarn是资源协调工具。 修改yarn-site.xml 配置如下:这里写图片描述" title="" style="box-sizing: border-box; outline: none; border: 0px none; margin: 24px 0px; overflow-wrap: break-word; cursor: zoom-in;"/> 配置slaves文件 (这个文件也是在etc/hadoop里面。 配置hadoop的环境变量 vim /etc/profile 主要是环境变量如图: JAVA_HOME=/home/software/jdk1.8 HADOOP_HOME=/home/software/hadoop-2.7.1 CLASSPATH=.:JAVA_HOME/lib/tools.jar PATH=HADOOP_HOME/bin:PATH export JAVA_HOME PATH CLASSPATH HADOOP_HOME 完成这些配置之后要格式化namenode 出现 代表格式化成功之后启动就可以了 启动hadoop 直接 输入start-all.sh就可以启动所有的服务,也可以单个的启动相应的服务。 启动完后 数据jps检查启动情况 这样是都启动起来了,也可以在浏览器上输入:http://192.168.80.21:50070 出现相应的页面。
Hadoop常用指令: 1.执行:hadoop fs -mkdir /test 在hdfs的根目录下,创建park目录 2.执行:hadoop fs -ls / 查看hdfs根目录下有哪些目录 3.hadoop fs -put /home/1.txt /test 将linux系统home 目录下的1.txt文档放到hdfs的test目录下 4.hadoop fs -get /test/1.txt /home 把hdfs文件系统下test目录的文档下载到/home目录下 5.hadoop fs -rm /test/文件名 删除test目录下的指定文件 6.hadoop fs -rmdir /test 删除test目录,但是前提目录是没有文件的 7.hadoop fs -rmr /test 删除test目录,无论有无文件都删除 8.hadoop fs -cat /test/1.txt 查看test目录下1.txt文件 9.hadoop fs -tail /test/1.txt 查看test目录下1.txt文件末尾的数据 10.hadoop jar xxx.jar 执行jar包 11.hadoop fs -mv /test /test1 将hdfs上的test目录重名为test1 12.hadoop fs -mv /test/1.txt /test1 将1.txt转移到test1目录下 13.hadoop fs -touch /test/2.txt 创建一个2.txt空文件 14.hadoop fs -getmerge /test /root 将test目录下的所有文件合并成一个文件,并下载到linux 的/root目录下 15.hadoop dfsadmin -safemode leave 离开安全模式 16.hadoop dfsadmin -safemode enter 进入安全模式 17.hadoop dfsadmin -rollEdits 手动执行fsimage 文件和Edis文件合并元数据 18.hadoop dfsadmin -report 查看存活的datanode节点 19.hadoop fsck /test 汇报/test目录健康状况 20.hadoop fsck /test/1.txt -files -blocks -locations -racks 查看1.txt这个文件block信息以及机架信息,元数据信息,包括:文件名,文件大小,文件块数量,文件块编号,文件存储的Datanode信息。 21.hadoop fs -du /test/1.txt 查看hdfs上某个文件的大小,也可以查看制定目录 22.hadoop fs -copyFormLocal /test/1.txt /home 将文件拷贝到本地文件系统 23.hadoop fs -lsr / 递归查看指定目录下的所有文件
Hadoop的运行模式有以下三种:
单机模式
伪分布模式
完全分布模式
Hadoop的安装步骤大致分为8步:
安装运行环境
修改主机名和用户名
配置静态IP
配置SSH无密码连接
安装JDK
配置Hadoop
格式和HDFS
启动Hadoop并验证安装
双路四核 2.6GHz CPU*1
DDR3内存 24G
双千兆以太网网卡
SAS驱动器控制器
SATA II驱动器的JBOD配置*2
提高我们的客户开始使用Hadoop时的第一个问题是关于选择合适的硬件,为他们的Hadoop集群。这个博客帖子描述Hadoop的管理员考虑到各种因素。我们鼓励其他人也附和他们的经验生产Hadoop集群配置。虽然Hadoop是设计行业标准的硬件上运行,建议一个理想的集群配置是不一样只是提供了硬件规格列表容易。选择硬件提供了一个给定的工作负载的性能和经济的最佳平衡,需要测试和验证。例如,用户IO密集型工作负载将投资在些每核心主轴。在这个博客后,我们将讨论的工作量评价和它在硬件的选择起着至关重要的作用。存储和计算的融合 在过去十年中,IT组织有标准化的刀片服务器和SAN(存储区域网络),以满足他们的网格和处理密集型工作负载。虽然这种模式使一些标准的应用,如Web服务器,应用服务器,规模较小的结构化数据库和简单的ETL(提取,转换,装载)基础设施的要求有很大的意义已经发生变化的数据量和数量用户已经成长。 Web服务器现在前端使用缓存层,数据库使用大规模并行与本地磁盘,ETL作业正在推动更多的数据比他们可以在本地处理。硬件厂商建立创新体系,以满足这些要求包括存储刀片,SAS(串行连接SCSI)开关,外部SATA阵列和更大容量的机架单元。Hadoop的目的是基于一种新的方法来存储和处理复杂的数据。海量存储和可靠性进行处理然后移动到刀片的集合,而不是依靠在SAN上,Hadoop的处理大数据量和可靠性,在软件层。 Hadoop的数据分布到集群上,处理平衡,并使用复制,以确保数据的可靠性和容错。因为数据的分布式计算能力的机器上,处理可以直接发送到存储数据的机器。由于每个机器在一个Hadoop集群的存储和处理数据,他们需要进行配置,以满足数据存储和处理要求。任务压力问题 MapReduce作业,在几乎所有情况下,将遇到一个瓶颈,从磁盘或从网络(作为IO时限的工作“),或在处理数据读取的数据(CPU绑定)。 IO绑定工作的一个例子是排序,这就需要非常小的加工(简单的比较)和大量的读取和写入磁盘。一个CPU密集型的工作的一个例子是分类,其中一些输入数据处理非常复杂的方式来确定一个本体。这里有几个例子IO绑定的工作量:1.索引2.搜索3.分组4.解码/解压缩5.数据导入和导出这里有几个CPU密集型工作负载的例子:1.机器学习2.复杂的文本挖掘3.自然语言处理4.特征提取 由于我们的客户需要了解他们的工作量,为了充分优化他们的Hadoop的硬件,在开始的时候,我们经常用一个典型的鸡和蛋的问题。最多的团队寻求建立一个Hadoop集群还不知道他们的工作量,往往是组织运行Hadoop的第一份任务的,远超过他们的想像。此外,有些工作负载可能会在无法预料的方式约束。例如,有时理论IO绑定的工作量实际上可能是因为用户的选择压缩的CPU绑定。有时可能会改变一个算法的不同实现MapReduce作业的限制。由于这些原因,是有道理的投资时,团队是不熟悉的工作,他们将运行在一个平衡的Hadoop集群,团队能够基准的MapReduce工作,一旦他们的平衡群集上运行,了解他们的必然。 它是直接测量现场工作量,并确定将在地方上的Hadoop集群的全面监测的瓶颈。我们建议安装Ganglia的所有Hadoop的机器提供实时统计,有关CPU,磁盘和网络负载。与Ganglia的安装了Hadoop的管理员可以运行自己的MapReduce工作,并检查Ganglia的仪表盘怎么看每一台机器正在执行。了解整个集群节点的更多信息。 除了建立集群适当的工作量,我们鼓励我们的客户能够与硬件厂商和了解电力和冷却的经济。由于Hadoop的运行几十,几百或上千个节点,一个运营团队,可以节省相当数量的钱,在低功耗的硬件投资。每个硬件厂商将能够提供如何监控电源和冷却的工具和建议。如何挑选适合你的Hadoop集群的硬件 在选择机器配置的第一步是要了解你的运营团队已经管理的硬件类型。运营团队往往有关于购买新机器的意见,,他们已经熟悉的硬件工作。 Hadoop是不是唯一的系统,从规模效益的好处。记得使用一个初始的群集到Hadoop时,如果你还不知道你的工作量均衡的硬件规划。一个基本的Hadoop集群中的节点有四种类型。我们这里指的是为执行特定任务的机器上的一个节点。大部分的机器将作为双方的Datanode的TaskTracker。正如我们所描述的,这些节点存储数据和执行处理功能。我们建议Datanode的/在一个平衡的Hadoop集群的TaskTracker以下规格:在JBOD(简单磁盘捆绑)配置41TB硬盘2四核CPU,运行至少2-2.5GHz的1624GBs的内存(如果你考虑HBase的24-32GBs)千兆以太网 namenode负责协调数据存储集群,jobtracker协调数据处理任务。最后的节点类型是secondarynamenode的,它可以为小群的namenode机器上同一位置,将较大的群集namenode节点相同的硬件上运行。我们建议我们的客户购买Power的服务器,为运行的namenodes和jobtrackers的冗余电源和搜查的企业级磁盘。 namenodes也需要更多的RAM,相对集群中的数据块数量。一个好的经验法则是假设的名称节点的分布式文件系统中存储的每个一百万块内存1GB。与100的Datanode在集群名称节点上的RAM32GBs提供充足的成长空间。我们也建议有一个备用机,以取代的情况下,当其中之一失败突然namenode或jobtracker。 当您希望您的Hadoop集群增长超过20台机器,我们建议初始群集配置,因为它是跨越两个机架,每个机架有机架千兆交换机顶部,这些交换机连接10千兆以太网的互连或核心切换。有两个逻辑机架,运营团队的内部机架的网络要求更好地理解和跨机架的沟通。 与Hadoop集群可以开始确定工作量和准备这些工作负载基准,以确定CPU和IO瓶颈。经过一段时间的基准和监测,该小组将有一个很好的了解,更多的机器应该如何进行配置。这是常见的有Hadoop集群,特别是因为它们的规模增长。一套机器不适合你的工作量时,将不会是一种浪费。下面是各种硬件配置不同的工作负载,包括我们原来的“基点”的建议名单: 轻型处理配置(1U/machine)的:两个四核CPU,8GB内存,4个磁盘驱动器(1TB或2TB)。注意CPU密集型的工作,如自然语言处理涉及加载到RAM的大型模型在数据处理之前,应配置2GB内存每核心,而不是1GB内存每核心。 平衡计算配置(1U/machine)的两个四核CPU,16到24GB内存,4个磁盘驱动器直接连接使用的主板控制器(1TB或2TB)。这些往往是因为有两个主板和8个驱动器在一个单一的2U机柜的。 重配置存储(2U/machine):两个四核CPU,16到24GB的内存,和12个磁盘驱动器(1TB或2TB)。这种类型的机器的功耗开始〜200W左右,处于闲置状态,可以去〜350W高活动时。 计算密集配置(2U/machine):两个四核CPU,48-72GB的内存,8个磁盘驱动器(1TB或2TB)。这些都需要一个大的内存模型和沉重的参考数据缓存的组合时经常使用。其他硬件方面的考虑 当我们遇到的应用程序产生大量的中间数据,我们建议一个以太网卡或双通道,太网卡提供2 Gbps的每台机器上的两个端口。另外,对于那些已经转移到10千兆以太网或Infiniband的客户,这些解决方案可以用来解决网络绑定的工作量。可以肯定,你的操作系统和BIOS是兼容的,如果你正在考虑切换到10千兆以太网。 当计算内存需求,Java使用管理虚拟机到10%的因素。我们建议配置Hadoop的使用严格的堆大小的限制,以避免内存交换到磁盘。交换大大影响MapReduce作业性能,可避免更多的RAM配置的机器。 同样重要的是优化RAM的内存通道宽度。例如,当使用双通道内存每台机器应该对DIMM配置。随着三通道内存,每台机器应该有三胞胎的DIMM。这意味着一台机器可能18GBs(9x2GB)内存,而不是16GBs(4x4GB)结束。结论 Hadoop集群购买相应的硬件要求基准和精心策划,充分理解的工作量。然而,Hadoop集群是常用异构,我们建议与平衡的规格部署开始时的初始硬件。
提高我们的客户开始使用Hadoop时的第一个问题是关于选择合适的硬件,为他们的Hadoop集群。这个博客帖子描述Hadoop的管理员考虑到各种因素。我们鼓励其他人也附和他们的经验生产Hadoop集群配置。虽然Hadoop是设计行业标准的硬件上运行,建议一个理想的集群配置是不一样只是提供了硬件规格列表容易。选择硬件提供了一个给定的工作负载的性能和经济的最佳平衡,需要测试和验证。例如,用户IO密集型工作负载将投资在些每核心主轴。在这个博客后,我们将讨论的工作量评价和它在硬件的选择起着至关重要的作用。
/data/hadoop-2.7.0/logsgedit hadoop-neworigin-datanode-s100.log查看clusterID发现datanode和namenode之间的ID不一致进入hdfs-site.xml 配置文件查看:[hdfs-site.xml]dfs.namenode.name.dir/home/neworigin/hadoop/hdfs/namedfs.data......
Kafka是一个高吞吐量分布式消息系统。linkedin开源的kafka。 Kafka就跟这个名字一样,设计非常独特。首先,kafka的开发者们认为不需要在内存里缓存什么数据,操作系统的文件缓存已经足够完善和强大,只要你不搞随机写,顺序读写的性能是非常高效的。kafka的数...
将 hadoop执行job命令写到shell脚本中。类似 hadoop jar x.jar ×××.MainClassName inputPath outputPath这种命令。hadoop客户机在本地,使用 Process执行shell脚本,java执行本地shell脚本的代码 1234Process process =null;String command1 ...
1
public static void test1(String user, String keytab, String dir) throws Exception { Configuration conf = new Configuration(); // conf.set(fs.defaultFS, hdfs://hadoop01:8020); c...
Hello, world! ]]>
Hadoop是由java语言编写的,在分布式服务器集群上存储海量数据并运行分布式分析应用的开源框架,其核心部件是HDFS与MapReduce。 HDFS是一个分布式文件系统:引入存放文件元数据信息的服务器Namenode和实际存放数据的服务器Datanode,对数据进行分布...
Hadoop的三大核心组件 分别是 :HDFS(Hadoop Distribute File System):hadoop的数据存储 工具。YARN(Yet Another Resource Negotiator,另一种 资源协调者):Hadoop 的资源管理 器。Hadoop MapReduce:分布式计算 框架...
最多设置5个标签!
{var%20f='http://v.t.sina.com.cn/share/share.php?appkey=1515056452',u=z||d.location,p=['&url=',e(u),'&title=',e(t||d.title),'&source=',e(r),'&sourceUrl=',e(l),'&content=',c||'gb2312','&pic=',e(p||'')].join('');function%20a(){if(!window.open([f,p].join(''),'mb',['toolbar=0,status=0,resizable=1,width=440,height=430,left=',(s.width-440)/2,',top=',(s.height-430)/2].join('')))u.href=[f,p].join('');};if(/Firefox/.test(navigator.userAgent))setTimeout(a,0);else%20a();})(screen,document,encodeURIComponent,'','','/static/images/logo.png', '推荐 上瘾入骨i 的问题《【Hadoop】hadoop最低硬件配置》','http://www.shouhuola.com/q-30919.html','页面编码gb2312|utf-8默认gb2312'));){kind=link}
1、hadoop简单介绍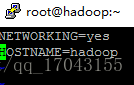
Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。
Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,则MapReduce为海量的数据提供了计算。
2、hadoop版本说明
hadoop现在分两个版本1.0和2.0(17年1月推出了3.0版本 在这先不介绍)
1.0版本,hadoop有两个核心模块:HDFS+MapReduce
2.0版本,hadoop有三个核心模块:HDFS+Yarn+MapReduce
yarn 是资源协调管理框架。
1.0时hadoop只有一种计算框架。在2.0之后推出yarn后,既可以运行mr,也可以运行Spark,storm等其他框架。
3、Hadoop安装
模式:
1、单机模式,不能使用HDFS,只能使用MR,一般用于测试MR代码
2、伪分布模式,也就是用一台机器,用多个进程模拟多台机器。HDFS和MR都能使用
3、完全分布模式,用多个机器或多个虚拟机来搭建(之后有一节专门来说)
实现步骤:
1、准备一台虚拟机,要求工作内存最低1G,否则有可能出现错误。
2、关闭防火墙(注意,这只是自己用的时候为了简单,在工作中是不能关闭的 只要打开hadoop所需要的几个端口就可,50070、90000、50020等端口。
3、配置主机名hostsname、配置hosts文件,为了之后使用方便
4、配置免密钥登陆,方便之后的登陆跨服务器传文件登陆用
5、安装配置jdk,因为hadoop就是java开发的需要jdk环境
6、最后安装配置hadoop
安装步骤:
1、关闭防火墙:service iptables off 这个指令关闭防火墙之后,重启后防火墙还会开启,执行chkconfig iptables off这个命令之后重启也不会开启了(这个只是自己的虚拟机下使用,生产线上是不能的,当然这些都不是我这个小兵所关心的)。
2、配置hostsname等:
vim /etc/sysconfig/network
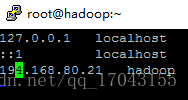
配置hosts 内容 vim /etc/hosts
3、配置免密钥登陆:
执行 ssh-keygen 一直回车 ,生成节点的公钥和私钥,生成的文件会放在/root/.ssh的目录下。
然后把公钥发往远程机器,比如发往本机,本机免密钥登陆:ssh-copy-id root@hadoop,此时,hadoop节点就是把收到的hadoop密钥保存在/root/.ssh/authorized_keys这个文件里,这个文件相当于访问的白名单,凡是在此白名单存储的密钥对应的机器,登陆时是免密码登陆的。两个机器分别进行一次则两方登陆时都是免密码的,之后做真分布式hadoop时要进行多个免密钥登陆的。
4、安装配置jdk
在这里就不写了。
5、安装配置hadoop
在这我是用的hadoop安装包进行的安装的。
我的安装包是hadoop-2.7.1的,我会上传的。
执行 tar -zxvf hadoop-2.7.1_64bit.tar.gz,之后解压生成相应的文件。其中由多个目录:
bin目录:命令脚本
etc/hadoop:存放hadoop的配置文件(之后修改配置文件,将在这里进行)
lib目录:hadoop运行的依赖jar包
sbin目录:启动和关闭hadoop命令都在这里
libexec目录:存放的也是hadoop命令,但是一般不适用。
修改配置文件 切换到 etc/hadoop里面修改。
配置hadoop-env.sh
这个文件里写的是hadoop的环境变量,主要修改hadoop的java_home路径。在这里面主要修改export java_home 写成自己jdk的安装目录,export hadoop_conf_dir 写成hadoop的安装目录
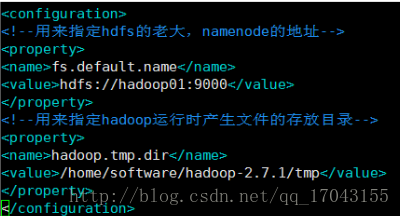
配置core-site.xml
配置如下:
配置hdfs-site.xml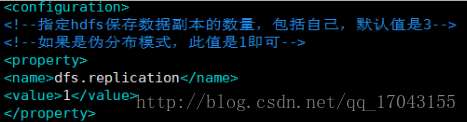
如下:
修改配置mapred-site.xml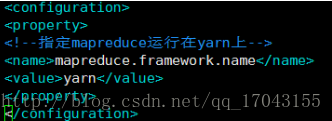
 这里写图片描述" title="" style="box-sizing: border-box; outline: none; border: 0px none; margin: 24px 0px; overflow-wrap: break-word; cursor: zoom-in;"/>
这里写图片描述" title="" style="box-sizing: border-box; outline: none; border: 0px none; margin: 24px 0px; overflow-wrap: break-word; cursor: zoom-in;"/> 
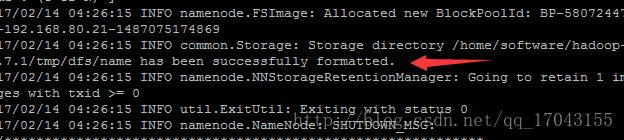 代表格式化成功之后启动就可以了
代表格式化成功之后启动就可以了 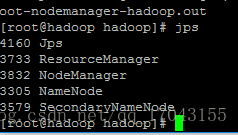 这样是都启动起来了,也可以在浏览器上输入:http://192.168.80.21:50070 出现相应的页面。
这样是都启动起来了,也可以在浏览器上输入:http://192.168.80.21:50070 出现相应的页面。
这个文件初始时是没有的,有的是模板文件mapred-site.xml.temple 复制这个文件命名为mapred-site.xml 修改就可以了。配置如下:
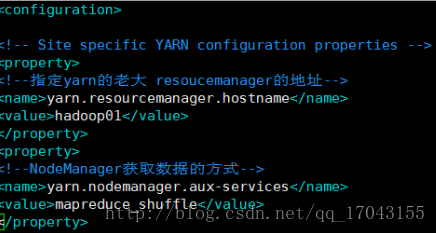
yarn是资源协调工具。
修改yarn-site.xml
配置如下:
配置slaves文件
(这个文件也是在etc/hadoop里面。
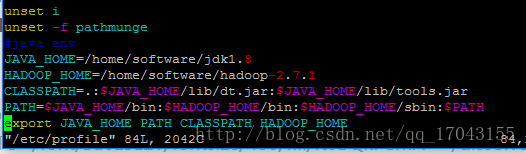
配置hadoop的环境变量 vim /etc/profile 主要是环境变量如图:
JAVA_HOME=/home/software/jdk1.8
HADOOP_HOME=/home/software/hadoop-2.7.1
CLASSPATH=.:JAVA_HOME/lib/tools.jar
PATH=HADOOP_HOME/bin:PATH
export JAVA_HOME PATH CLASSPATH HADOOP_HOME
完成这些配置之后要格式化namenode
出现
启动hadoop 直接 输入start-all.sh就可以启动所有的服务,也可以单个的启动相应的服务。
启动完后 数据jps检查启动情况
Hadoop常用指令:
1.执行:hadoop fs -mkdir /test 在hdfs的根目录下,创建park目录
2.执行:hadoop fs -ls / 查看hdfs根目录下有哪些目录
3.hadoop fs -put /home/1.txt /test 将linux系统home 目录下的1.txt文档放到hdfs的test目录下
4.hadoop fs -get /test/1.txt /home 把hdfs文件系统下test目录的文档下载到/home目录下
5.hadoop fs -rm /test/文件名 删除test目录下的指定文件
6.hadoop fs -rmdir /test 删除test目录,但是前提目录是没有文件的
7.hadoop fs -rmr /test 删除test目录,无论有无文件都删除
8.hadoop fs -cat /test/1.txt 查看test目录下1.txt文件
9.hadoop fs -tail /test/1.txt 查看test目录下1.txt文件末尾的数据
10.hadoop jar xxx.jar 执行jar包
11.hadoop fs -mv /test /test1 将hdfs上的test目录重名为test1
12.hadoop fs -mv /test/1.txt /test1 将1.txt转移到test1目录下
13.hadoop fs -touch /test/2.txt 创建一个2.txt空文件
14.hadoop fs -getmerge /test /root 将test目录下的所有文件合并成一个文件,并下载到linux 的/root目录下
15.hadoop dfsadmin -safemode leave 离开安全模式
16.hadoop dfsadmin -safemode enter 进入安全模式
17.hadoop dfsadmin -rollEdits 手动执行fsimage 文件和Edis文件合并元数据
18.hadoop dfsadmin -report 查看存活的datanode节点
19.hadoop fsck /test 汇报/test目录健康状况
20.hadoop fsck /test/1.txt -files -blocks -locations -racks 查看1.txt这个文件block信息以及机架信息,元数据信息,包括:文件名,文件大小,文件块数量,文件块编号,文件存储的Datanode信息。
21.hadoop fs -du /test/1.txt 查看hdfs上某个文件的大小,也可以查看制定目录
22.hadoop fs -copyFormLocal /test/1.txt /home 将文件拷贝到本地文件系统
23.hadoop fs -lsr / 递归查看指定目录下的所有文件
Hadoop的运行模式有以下三种:
单机模式
伪分布模式
完全分布模式
Hadoop的安装步骤大致分为8步:
安装运行环境
修改主机名和用户名
配置静态IP
配置SSH无密码连接
安装JDK
配置Hadoop
格式和HDFS
启动Hadoop并验证安装
双路四核 2.6GHz CPU*1
DDR3内存 24G
双千兆以太网网卡
SAS驱动器控制器
SATA II驱动器的JBOD配置*2
提高我们的客户开始使用Hadoop时的第一个问题是关于选择合适的硬件,为他们的Hadoop集群。这个博客帖子描述Hadoop的管理员考虑到各种因素。我们鼓励其他人也附和他们的经验生产Hadoop集群配置。虽然Hadoop是设计行业标准的硬件上运行,建议一个理想的集群配置是不一样只是提供了硬件规格列表容易。选择硬件提供了一个给定的工作负载的性能和经济的最佳平衡,需要测试和验证。例如,用户IO密集型工作负载将投资在些每核心主轴。在这个博客后,我们将讨论的工作量评价和它在硬件的选择起着至关重要的作用。
存储和计算的融合
在过去十年中,IT组织有标准化的刀片服务器和SAN(存储区域网络),以满足他们的网格和处理密集型工作负载。虽然这种模式使一些标准的应用,如Web服务器,应用服务器,规模较小的结构化数据库和简单的ETL(提取,转换,装载)基础设施的要求有很大的意义已经发生变化的数据量和数量用户已经成长。 Web服务器现在前端使用缓存层,数据库使用大规模并行与本地磁盘,ETL作业正在推动更多的数据比他们可以在本地处理。硬件厂商建立创新体系,以满足这些要求包括存储刀片,SAS(串行连接SCSI)开关,外部SATA阵列和更大容量的机架单元。
Hadoop的目的是基于一种新的方法来存储和处理复杂的数据。海量存储和可靠性进行处理然后移动到刀片的集合,而不是依靠在SAN上,Hadoop的处理大数据量和可靠性,在软件层。 Hadoop的数据分布到集群上,处理平衡,并使用复制,以确保数据的可靠性和容错。因为数据的分布式计算能力的机器上,处理可以直接发送到存储数据的机器。由于每个机器在一个Hadoop集群的存储和处理数据,他们需要进行配置,以满足数据存储和处理要求。
任务压力问题
MapReduce作业,在几乎所有情况下,将遇到一个瓶颈,从磁盘或从网络(作为IO时限的工作“),或在处理数据读取的数据(CPU绑定)。 IO绑定工作的一个例子是排序,这就需要非常小的加工(简单的比较)和大量的读取和写入磁盘。一个CPU密集型的工作的一个例子是分类,其中一些输入数据处理非常复杂的方式来确定一个本体。
这里有几个例子IO绑定的工作量:
1.索引
2.搜索
3.分组
4.解码/解压缩
5.数据导入和导出
这里有几个CPU密集型工作负载的例子:
1.机器学习
2.复杂的文本挖掘
3.自然语言处理
4.特征提取
由于我们的客户需要了解他们的工作量,为了充分优化他们的Hadoop的硬件,在开始的时候,我们经常用一个典型的鸡和蛋的问题。最多的团队寻求建立一个Hadoop集群还不知道他们的工作量,往往是组织运行Hadoop的第一份任务的,远超过他们的想像。此外,有些工作负载可能会在无法预料的方式约束。例如,有时理论IO绑定的工作量实际上可能是因为用户的选择压缩的CPU绑定。有时可能会改变一个算法的不同实现MapReduce作业的限制。由于这些原因,是有道理的投资时,团队是不熟悉的工作,他们将运行在一个平衡的Hadoop集群,团队能够基准的MapReduce工作,一旦他们的平衡群集上运行,了解他们的必然。
它是直接测量现场工作量,并确定将在地方上的Hadoop集群的全面监测的瓶颈。我们建议安装Ganglia的所有Hadoop的机器提供实时统计,有关CPU,磁盘和网络负载。与Ganglia的安装了Hadoop的管理员可以运行自己的MapReduce工作,并检查Ganglia的仪表盘怎么看每一台机器正在执行。了解整个集群节点的更多信息。
除了建立集群适当的工作量,我们鼓励我们的客户能够与硬件厂商和了解电力和冷却的经济。由于Hadoop的运行几十,几百或上千个节点,一个运营团队,可以节省相当数量的钱,在低功耗的硬件投资。每个硬件厂商将能够提供如何监控电源和冷却的工具和建议。
如何挑选适合你的Hadoop集群的硬件
在选择机器配置的第一步是要了解你的运营团队已经管理的硬件类型。运营团队往往有关于购买新机器的意见,,他们已经熟悉的硬件工作。 Hadoop是不是唯一的系统,从规模效益的好处。记得使用一个初始的群集到Hadoop时,如果你还不知道你的工作量均衡的硬件规划。
一个基本的Hadoop集群中的节点有四种类型。我们这里指的是为执行特定任务的机器上的一个节点。大部分的机器将作为双方的Datanode的TaskTracker。正如我们所描述的,这些节点存储数据和执行处理功能。我们建议Datanode的/在一个平衡的Hadoop集群的TaskTracker以下规格:
在JBOD(简单磁盘捆绑)配置41TB硬盘
2四核CPU,运行至少2-2.5GHz的
1624GBs的内存(如果你考虑HBase的24-32GBs)
千兆以太网
namenode负责协调数据存储集群,jobtracker协调数据处理任务。最后的节点类型是secondarynamenode的,它可以为小群的namenode机器上同一位置,将较大的群集namenode节点相同的硬件上运行。我们建议我们的客户购买Power的服务器,为运行的namenodes和jobtrackers的冗余电源和搜查的企业级磁盘。 namenodes也需要更多的RAM,相对集群中的数据块数量。一个好的经验法则是假设的名称节点的分布式文件系统中存储的每个一百万块内存1GB。与100的Datanode在集群名称节点上的RAM32GBs提供充足的成长空间。我们也建议有一个备用机,以取代的情况下,当其中之一失败突然namenode或jobtracker。
当您希望您的Hadoop集群增长超过20台机器,我们建议初始群集配置,因为它是跨越两个机架,每个机架有机架千兆交换机顶部,这些交换机连接10千兆以太网的互连或核心切换。有两个逻辑机架,运营团队的内部机架的网络要求更好地理解和跨机架的沟通。
与Hadoop集群可以开始确定工作量和准备这些工作负载基准,以确定CPU和IO瓶颈。经过一段时间的基准和监测,该小组将有一个很好的了解,更多的机器应该如何进行配置。这是常见的有Hadoop集群,特别是因为它们的规模增长。一套机器不适合你的工作量时,将不会是一种浪费。
下面是各种硬件配置不同的工作负载,包括我们原来的“基点”的建议名单:
轻型处理配置(1U/machine)的:两个四核CPU,8GB内存,4个磁盘驱动器(1TB或2TB)。注意CPU密集型的工作,如自然语言处理涉及加载到RAM的大型模型在数据处理之前,应配置2GB内存每核心,而不是1GB内存每核心。
平衡计算配置(1U/machine)的两个四核CPU,16到24GB内存,4个磁盘驱动器直接连接使用的主板控制器(1TB或2TB)。这些往往是因为有两个主板和8个驱动器在一个单一的2U机柜的。
重配置存储(2U/machine):两个四核CPU,16到24GB的内存,和12个磁盘驱动器(1TB或2TB)。这种类型的机器的功耗开始〜200W左右,处于闲置状态,可以去〜350W高活动时。
计算密集配置(2U/machine):两个四核CPU,48-72GB的内存,8个磁盘驱动器(1TB或2TB)。这些都需要一个大的内存模型和沉重的参考数据缓存的组合时经常使用。
其他硬件方面的考虑
当我们遇到的应用程序产生大量的中间数据,我们建议一个以太网卡或双通道,太网卡提供2 Gbps的每台机器上的两个端口。另外,对于那些已经转移到10千兆以太网或Infiniband的客户,这些解决方案可以用来解决网络绑定的工作量。可以肯定,你的操作系统和BIOS是兼容的,如果你正在考虑切换到10千兆以太网。
当计算内存需求,Java使用管理虚拟机到10%的因素。我们建议配置Hadoop的使用严格的堆大小的限制,以避免内存交换到磁盘。交换大大影响MapReduce作业性能,可避免更多的RAM配置的机器。
同样重要的是优化RAM的内存通道宽度。例如,当使用双通道内存每台机器应该对DIMM配置。随着三通道内存,每台机器应该有三胞胎的DIMM。这意味着一台机器可能18GBs(9x2GB)内存,而不是16GBs(4x4GB)结束。
结论
Hadoop集群购买相应的硬件要求基准和精心策划,充分理解的工作量。然而,Hadoop集群是常用异构,我们建议与平衡的规格部署开始时的初始硬件。
提高我们的客户开始使用Hadoop时的第一个问题是关于选择合适的硬件,为他们的Hadoop集群。这个博客帖子描述Hadoop的管理员考虑到各种因素。我们鼓励其他人也附和他们的经验生产Hadoop集群配置。虽然Hadoop是设计行业标准的硬件上运行,建议一个理想的集群配置是不一样只是提供了硬件规格列表容易。选择硬件提供了一个给定的工作负载的性能和经济的最佳平衡,需要测试和验证。例如,用户IO密集型工作负载将投资在些每核心主轴。在这个博客后,我们将讨论的工作量评价和它在硬件的选择起着至关重要的作用。
相关问题推荐
/data/hadoop-2.7.0/logsgedit hadoop-neworigin-datanode-s100.log查看clusterID发现datanode和namenode之间的ID不一致进入hdfs-site.xml 配置文件查看:[hdfs-site.xml]dfs.namenode.name.dir/home/neworigin/hadoop/hdfs/namedfs.data......
Kafka是一个高吞吐量分布式消息系统。linkedin开源的kafka。 Kafka就跟这个名字一样,设计非常独特。首先,kafka的开发者们认为不需要在内存里缓存什么数据,操作系统的文件缓存已经足够完善和强大,只要你不搞随机写,顺序读写的性能是非常高效的。kafka的数...
将 hadoop执行job命令写到shell脚本中。类似 hadoop jar x.jar ×××.MainClassName inputPath outputPath这种命令。hadoop客户机在本地,使用 Process执行shell脚本,java执行本地shell脚本的代码 1234Process process =null;String command1 ...
1
public static void test1(String user, String keytab, String dir) throws Exception { Configuration conf = new Configuration(); // conf.set(fs.defaultFS, hdfs://hadoop01:8020); c...
Hello, world! ]]>
Hadoop是由java语言编写的,在分布式服务器集群上存储海量数据并运行分布式分析应用的开源框架,其核心部件是HDFS与MapReduce。 HDFS是一个分布式文件系统:引入存放文件元数据信息的服务器Namenode和实际存放数据的服务器Datanode,对数据进行分布...
Hadoop的三大核心组件 分别是 :HDFS(Hadoop Distribute File System):hadoop的数据存储 工具。YARN(Yet Another Resource Negotiator,另一种 资源协调者):Hadoop 的资源管理 器。Hadoop MapReduce:分布式计算 框架...