2020-12-12 09:43发布
hbase写入流程:
1、Client 向 HregionServer 发送写请求;
2、HregionServer 将数据写到 HLog(write ahead log)。为了数据的持久化和恢复;
3、HregionServer 将数据写到内存(MemStore);
4、反馈 Client 写成功。
数据写入流程
第一部分:客户端的写入流程客户端流程解析:1、用户提交put请求后,HBase客户端会将put请求添加到本地buffer中,符合一定条件就会通过AsyncProcess异步批量提交。HBase默认设置autoflush=true,表示put请求直接会提交给服务器进行处理;2、用户可以设置autoflush=false,这样的话put请求会首先放到本地buffer,等到本地buffer大小超过一定阈值(默认为2M,可以通过配置文件配置)之后才会提交。很显然,后者采用group commit机制提交请求,可以极大地提升写入性能,但是因为没有保护机制,如果客户端崩溃的话会导致提交的请求丢失。//提示:cdh集群中hbase默认是使用autoflush=false 也就是首先会把数据放在本地的buffer中HBase 客户端写入缓冲hbase.client.write.buffer = 2M //写入缓冲区大小(以字节为单位)。较大缓冲区需要客户端和服务器中有较大内存,因为服务器将实例化已通过的写入缓冲区并进行处理,这会降低远程过程调用 (RPC) 的数量。为了估计服务器已使用内存的数量,请用值“hbase.client.write.buffer”乘以“hbase.regionserver.handler.count”。HBase Region Server 处理程序计数hbase.regionserver.handler.count = 30 //RegionServer 中启动的 RPC 服务器实例数量3、在提交给服务端之前,HBase会在元数据表.meta.中根据rowkey找到它们归属的region server,这个定位的过程是通过HConnection的locateRegion方法获得的。如果是批量请求的话还会把这些rowkey按照HRegionLocation分组,每个分组可以对应一次RPC请求。4、HBase会为每个HRegionLocation构造一个远程RPC请求MultiServerCallable,然后通过rpcCallerFactory. newCaller()执行调用,忽略掉失败重新提交和错误处理,客户端的提交操作到此结束。
第二部分:服务端写入流程服务端流程解析(1)获取行锁、Region更新共享锁 -》(2)开始写事务 -》(3)写缓存memstore -》(4)构造waledit并append hlog - 》 (5)释放行锁,共享锁 - 》 (6)sync hlog -》(7)结束写事务 - 》(8) flush memstore//解释(1)获取行锁、Region更新共享锁: HBase中使用行锁保证对同一行数据的更新都是互斥操作,用以保证更新的原子性,要么更新成功,要么失败。(2)开始写事务:获取write number,用于实现MVCC,实现数据的非锁定读,在保证读写一致性的前提下提高读取性能。(3)写缓存memstore:HBase中每列族都会对应一个store,用来存储该列数据。每个store都会有个写缓存memstore,用于缓存写入数据。HBase并不会直接将数据落盘,而是先写入缓存,等缓存满足一定大小之后再一起落盘。(4)Append HLog:HBase使用WAL机制保证数据可靠性,即首先写日志再写缓存,即使发生宕机,也可以通过恢复HLog还原出原始数据。该步骤就是将数据构造为WALEdit对象,然后顺序写入HLog中,此时不需要执行sync操作。0.98版本采用了新的写线程模式实现HLog日志的写入,可以使得整个数据更新性能得到极大提升,具体原理见下一个章节。(5)释放行锁以及共享锁(6)Sync HLog:HLog真正sync到HDFS,在释放行锁之后执行sync操作是为了尽量减少持锁时间,提升写性能。如果Sync失败,执行回滚操作将memstore中已经写入的数据移除。(7)结束写事务:此时该线程的更新操作才会对其他读请求可见,更新才实际生效。具体分析见文章《数据库事务系列-HBase行级事务模型》(8)flush memstore:当写缓存满128M之后,会启动flush线程将数据刷新到硬盘。刷新操作涉及到HFile相关结构,后面会详细对此进行介绍。//HBase Memstore 刷新大小hbase.hregion.memstore.flush.size = 128M //如 memstore 大小超过此值(字节数),Memstore 将刷新到磁盘。通过运行由 hbase.server.thread.wakefrequency 指定的频率的线程检查此值。
客户端流程解析:1、用户提交put请求后,HBase客户端会将put请求添加到本地buffer中,符合一定条件就会通过AsyncProcess异步批量提交。HBase默认设置autoflush=true,表示put请求直接会提交给服务器进行处理;2、用户可以设置autoflush=false,这样的话put请求会首先放到本地buffer,等到本地buffer大小超过一定阈值(默认为2M,可以通过配置文件配置)之后才会提交。很显然,后者采用group commit机制提交请求,可以极大地提升写入性能,但是因为没有保护机制,如果客户端崩溃的话会导致提交的请求丢失。//提示:cdh集群中hbase默认是使用autoflush=false 也就是首先会把数据放在本地的buffer中HBase 客户端写入缓冲hbase.client.write.buffer = 2M //写入缓冲区大小(以字节为单位)。较大缓冲区需要客户端和服务器中有较大内存,因为服务器将实例化已通过的写入缓冲区并进行处理,这会降低远程过程调用 (RPC) 的数量。为了估计服务器已使用内存的数量,请用值“hbase.client.write.buffer”乘以“hbase.regionserver.handler.count”。HBase Region Server 处理程序计数hbase.regionserver.handler.count = 30 //RegionServer 中启动的 RPC 服务器实例数量3、在提交给服务端之前,HBase会在元数据表.meta.中根据rowkey找到它们归属的region server,这个定位的过程是通过HConnection的locateRegion方法获得的。如果是批量请求的话还会把这些rowkey按照HRegionLocation分组,每个分组可以对应一次RPC请求。4、HBase会为每个HRegionLocation构造一个远程RPC请求MultiServerCallable,然后通过rpcCallerFactory. newCaller()执行调用,忽略掉失败重新提交和错误处理,客户端的提交操作到此结束。
1.部分:客户端的写入流程 客户端流程解析: 1、用户提交put请求后,HBase客户端会将put请求添加到本地buffer中,符合一定条件就会通过AsyncProcess异步批量提交。 HBase默认设置...
2.部分:服务端写入流程 服务端流程解析 (1)获取行锁、Region更新共享锁 -》(2)开始写事务 -》(3)写缓存...
3.部分:WAL机制解析 1、WAL(Write-Ahead Logging)是一种高效的.
//提示:我们需要注意,在服务器端写数据的时候,有很多资料是先写到memstore中,再写到wal log中,但是,这样理解不是很准确,因为这好像,违背了wal log的容灾机制,所有,我们可以理解为先写入到wal log中再写入到memstore中的 //这一步源码中并没有完全的体现出来,可以理解为同步进行。理论上应该是先写wal log中,HBase这块实现是先写mem,后写WAL,hbase能够保证只有这两个都写完了用户才会可见(mvcc机制),而且如果mem写成功,wal写失败,mem会被回滚。这样做之所以it’s ok,是由于MVCC来保证的,在每个写线程开启事务的开头就会创建全局递增的write num,但是在HLog更新完毕之后才会去向前推进(roll forward)全局读取点。所以在此期间内,任何读取线程采用MVCC机制根据读取点读取数据,任何写入/更新操作在HLog未更新完毕之前是不会向前推进读取点的,因此即使数据已经写入memstore,对读线程也是不可见的。
第三部分:WAL机制解析1、WAL(Write-Ahead Logging)是一种高效的日志算法,几乎是所有非内存数据库提升写性能的不二法门,2、基本原理是在数据写入之前首先顺序写入日志,然后再写入缓存,等到缓存写满之后统一落盘。3、之所以能够提升写性能,是因为WAL将一次随机写转化为了一次顺序写加一次内存写。4、提升写性能的同时,WAL可以保证数据的可靠性,即在任何情况下数据不丢失。5、假如一次写入完成之后发生了宕机,即使所有缓存中的数据丢失,也可以通过恢复日志还原出丢失的数据。
WAL持久化等级HBase中可以通过设置WAL的持久化等级决定是否开启WAL机制、以及HLog的落盘方式。WAL的持久化等级分为如下四个等级:
SKIP_WAL:只写缓存,不写HLog日志。这种方式因为只写内存,因此可以极大的提升写入性能,但是数据有丢失的风险。在实际应用过程中并不建议设置此等级,除非确认不要求数据的可靠性。
ASYNC_WAL:异步将数据写入HLog日志中。
SYNC_WAL:同步将数据写入日志文件中,需要注意的是数据只是被写入文件系统中,并没有真正落盘。
FSYNC_WAL:同步将数据写入日志文件并强制落盘。最严格的日志写入等级,可以保证数据不会丢失,但是性能相对比较差。
USER_DEFAULT:默认如果用户没有指定持久化等级,HBase使用SYNC_WAL等级持久化数据。
用户可以通过客户端设置WAL持久化等级,代码:put.setDurability(Durability. SYNC_WAL );//cdh中WAL 提供程序hbase.wal.provider = //可选项为: //RegionServer 应用于提前写入日志的实施。RegionServer Default Group多个 HDFS WAL单个 HDFS WALHBase 默认设置(Single HDFS WAL)
WAL HSM 存储策略hbase.wal.storage.policyRegionServer Default Group所有副本都在 SSD 上一个副本在 SSD 上,其他副本均在 HDD 上无(全部在 HDD 上)
关于wal 和 hlog概念的的升入研究 见参考链接//HLog的写入模型。HLog的写入可以分为三个阶段,首先将数据对写入本地缓存,然后再将本地缓存写入文件系统,最后执行sync操作同步到磁盘
众所周知,HBase默认适用于写多读少的应用,正是依赖于它相当出色的写入性能:一个100台RS的集群可以轻松地支撑每天10T的写入量。当然,为了支持更高吞吐量的写入,HBase还在不断地进行优化和修正,这篇文章结合0.98版本的源码全面地分析HBase的写入流程,全文分为三个部分,第一部分介绍客户端的写入流程,第二部分介绍服务器端的写入流程,最后再重点分析WAL的工作原理。
hbase提供了对hbase进行一系列的管理涉及到对表的管理、数据的操作java api。 常用的api操作有: 1、 对表的创建、删除、显示以及修改等,可以用hbaseadmin,一旦创建了表,那么可以通过htable的实例来访问表,每次可以往表里增加数据
1、组件架构图
2、相关概念
1)Region
table在行的方向上分隔为多个Region,或者说是根据rowkey分割。Region是HBase中分布式存储和负载均衡的最小单元,即不同的region可以分别在不同的Region Server上,但同一个Region是不会拆分到多个server上。Region按大小分隔,表中每一行只能属于一个region。随着数据不断插入表,region不断增大,当region的某个列族达到一个阈值(默认256M)时就会分成两个新的region。
2)Store每一个region有一个或多个store组成,至少是一个store,hbase会把一起访问的数据放在一个store里面,即为每个ColumnFamily建一个store(即有几个ColumnFamily,也就有几个Store)。一个Store由一个memStore和0或多个StoreFile组成。
HBase以store的大小来判断是否需要切分region。
3)MemStore
MemStore是放在内存里的。保存修改的数据即keyValues。当MemStore的大小达到一个阀值(默认64MB)时,MemStore会被flush到文件,即生成一个快照。目前hbase 会有一个线程来负责MemStore的flush操作。
keyValues
默认64MB
flush
4)StoreFilememStore内存中的数据写到文件后就是StoreFile(即memstore的每次flush操作都会生成一个新的StoreFile),StoreFile底层是以HFile的格式保存。
5. HFileHFile是HBase中KeyValue数据的存储格式,是hadoop的二进制格式文件。一个StoreFile对应着一个HFile。而HFile是存储在HDFS之上的。HFile文件格式是基于Google Bigtable中的SSTable,如下图所示:
首先HFile文件是不定长的,长度固定的只有其中的两块:Trailer和FileInfo。Trailer中又指针指向其他数据块的起始点,FileInfo记录了文件的一些meta信息。
3、数据写入流程
关于wal 和 hlog概念的的升入研究 见参考链接//HLog的写入模型。HLog的写入可以分为三个阶段,首先将数据对写入本地缓存,然后再将本地缓存写入文件系统,最后执行sync操作同步到磁盘。
可以调一下系统时间,使用date命令,一般节点掉了都是时间不同步。
Hbase安装与启动一,前言二,前期准备 2.1 文件下载 2.2 服务器准备三,配置文件配置 3.1 hbase-env.sh 3.2 hbase-site.xml 3.3 regionservers 3.4 将hbase的bin目录添加到环境变量 3.5 Hbase的官方配置文档四,Hbase服务启动 4.1 ...
首先介绍部署 HBase 之前需要做的准备工作,如 Java、SSH 和 Hadoop 这些先决条件的配置;然后介绍如何安装 HBase,以及如何配置集群中相关文件。同时需要注意的是,本节介绍的是分布式 HBase 集群的部署,在对一台机器修改配置文件后需要同步到集群中的所有...
HBase安装HBase的安装也分为三种,单机版、伪分布式、分布式。我们首先来安装单机版。单机版首先我们去官网下载好HBase的安装包;接下来,将压缩包解压缩到你想安装的目录(我解压到的是/app目录):tar -zxvf hbase-2.1.0-bin.tar.gz /app安装单机版很简...
HBase分布式数据库具有如下的显著特点:容量大:HBase分布式数据库中的表可以存储成千上万的行和列组成的数据。面向列:HBase是面向列的存储和权限控制,并支持独立检索。列存储,其数据在表中是按照某列存储的,根据数据动态的增加列,并且可以单独对列进行...
1、查看单行记录:get '表名称', '行名称'2、查看表中的记录总数:count '表名称'3、查看表所有记录:scan 表名称4、查看表某个列所有记录:scan 表名称 , ['列名称:']5、查看有哪些表:list6、查看表结构:describe '表...
hbase与传统数据库的区别1.数据类型:Hbase只有简单的数据类型,只保留字符串;传统数据库有丰富的数据类型。2.数据操作:Hbase只有简单的插入、查询、删除、清空等操作,表和表之间是分离的,没有复杂的表和表之间的关系;传统数据库通常有各式各样的函数和连...
1、HBase写快读慢,HBase的读取时长通常是几毫秒,而Redis的读取时长通常是几十微秒。性能相差非常大。2、HBase和Redis都支持KV类型。但是Redis支持List、Set等更丰富的类型。3、Redis支持的数据量通常受内存限制,而HBase没有这个限制,可以存储远超内存大小...
启动HBase集群:bin/start-hbase.sh单独启动一个HMaster进程:bin/hbase-daemon.sh start master单独启动一个HRegionServer进程:bin/hbase-daemon.sh start regionserver
hbase的八大应用场景1、对象存储:我们知道不少的头条类、新闻类的的新闻、网页、图片存储在HBase之中,一些病毒公司的病毒库也是存储在HBase之中2、时序数据:HBase之上有OpenTSDB模块,可以满足时序类场景的需求3、推荐画像:特别是用户的画像,是一个比较...
1、频繁刷写我们知道Region的一个列族对应一个MemStore,假设HBase表都有统一的1个列族配置,则每个Region只包含一个MemStore。通常HBase的一个MemStore默认大小为128 MB,见参数hbase.hregion.memstore.flush.size。当可用内存足够时,每个MemStore可以分配...
避免HBase经常split,产生不必要的资源消耗,提高HBase的性能。
HBase每张表在底层存储上是由至少一个Region组成,Region实际上就是HBase表的分区。HBase新建一张表时默认Region即分区的数量为1,一般在生产环境中我们都会手动给Table提前做 预分区,使用合适的分区策略创建好一定数量的分区并使分区均匀分布在不同regions...
关于每个regionserver节点分区数量大致合理的范围,HBase官网上也给出了定义:Generally less regions makes for a smoother running cluster (you can always manually split the big regions later (if necessary) to spread the data, or re......
最多设置5个标签!
{var%20f='http://v.t.sina.com.cn/share/share.php?appkey=1515056452',u=z||d.location,p=['&url=',e(u),'&title=',e(t||d.title),'&source=',e(r),'&sourceUrl=',e(l),'&content=',c||'gb2312','&pic=',e(p||'')].join('');function%20a(){if(!window.open([f,p].join(''),'mb',['toolbar=0,status=0,resizable=1,width=440,height=430,left=',(s.width-440)/2,',top=',(s.height-430)/2].join('')))u.href=[f,p].join('');};if(/Firefox/.test(navigator.userAgent))setTimeout(a,0);else%20a();})(screen,document,encodeURIComponent,'','','/static/images/logo.png', '推荐 上瘾入骨i 的问题《【hbase基础】hbase写入数据库的流程》','http://www.shouhuola.com/q-31746.html','页面编码gb2312|utf-8默认gb2312'));){kind=link}
hbase写入流程:
1、Client 向 HregionServer 发送写请求;
2、HregionServer 将数据写到 HLog(write ahead log)。为了数据的持久化和恢复;
3、HregionServer 将数据写到内存(MemStore);
4、反馈 Client 写成功。
数据写入流程
第一部分:客户端的写入流程,然后通过rpcCallerFactory. newCaller()执行调用,忽略掉失败重新提交和错误处理,客户端的提交操作到此结束。
客户端流程解析:
1、用户提交put请求后,HBase客户端会将put请求添加到本地buffer中,符合一定条件就会通过AsyncProcess异步批量提交。
HBase默认设置autoflush=true,表示put请求直接会提交给服务器进行处理;
2、用户可以设置autoflush=false,这样的话put请求会首先放到本地buffer,等到本地buffer大小超过一定阈值(默认为2M,可以通过配置文件配置)之后才会提交。很显然,后者采用group commit机制提交请求,可以极大地提升写入性能,但是因为没有保护机制,如果客户端崩溃的话会导致提交的请求丢失。
//提示:
cdh集群中hbase默认是使用autoflush=false 也就是首先会把数据放在本地的buffer中
HBase 客户端写入缓冲
hbase.client.write.buffer = 2M //写入缓冲区大小(以字节为单位)。较大缓冲区需要客户端和服务器中有较大内存,因为服务器将实例化已通过的写入缓冲区并进行处理,这会降低远程过程调用 (RPC) 的数量。为了估计服务器已使用内存的数量,请用值“hbase.client.write.buffer”乘以“hbase.regionserver.handler.count”。
HBase Region Server 处理程序计数
hbase.regionserver.handler.count = 30 //RegionServer 中启动的 RPC 服务器实例数量
3、在提交给服务端之前,HBase会在元数据表.meta.中根据rowkey找到它们归属的region server,这个定位的过程是通过HConnection的locateRegion方法获得的。如果是批量请求的话还会把这些rowkey按照HRegionLocation分组,每个分组可以对应一次RPC请求。
4、HBase会为每个HRegionLocation构造一个远程RPC请求MultiServerCallable
第二部分:服务端写入流程
服务端流程解析
(1)获取行锁、Region更新共享锁 -》(2)开始写事务 -》(3)写缓存memstore -》(4)构造waledit并append hlog - 》 (5)
释放行锁,共享锁 - 》 (6)sync hlog -》(7)结束写事务 - 》(8) flush memstore
//解释
(1)获取行锁、Region更新共享锁: HBase中使用行锁保证对同一行数据的更新都是互斥操作,用以保证更新的原子性,要么更新成功,要么失败。
(2)开始写事务:获取write number,用于实现MVCC,实现数据的非锁定读,在保证读写一致性的前提下提高读取性能。
(3)写缓存memstore:HBase中每列族都会对应一个store,用来存储该列数据。每个store都会有个写缓存memstore,用于缓存写入数据。HBase并不会直接将数据落盘,而是先写入缓存,等缓存满足一定大小之后再一起落盘。
(4)Append HLog:HBase使用WAL机制保证数据可靠性,即首先写日志再写缓存,即使发生宕机,也可以通过恢复HLog还原出原始数据。该步骤就是将数据构造为WALEdit对象,然后顺序写入HLog中,此时不需要执行sync操作。0.98版本采用了新的写线程模式实现HLog日志的写入,可以使得整个数据更新性能得到极大提升,具体原理见下一个章节。
(5)释放行锁以及共享锁
(6)Sync HLog:HLog真正sync到HDFS,在释放行锁之后执行sync操作是为了尽量减少持锁时间,提升写性能。如果Sync失败,执行回滚操作将memstore中已经写入的数据移除。
(7)结束写事务:此时该线程的更新操作才会对其他读请求可见,更新才实际生效。具体分析见文章《数据库事务系列-HBase行级事务模型》
(8)flush memstore:当写缓存满128M之后,会启动flush线程将数据刷新到硬盘。刷新操作涉及到HFile相关结构,后面会详细对此进行介绍。
//HBase Memstore 刷新大小
hbase.hregion.memstore.flush.size = 128M //如 memstore 大小超过此值(字节数),Memstore 将刷新到磁盘。通过运行由 hbase.server.thread.wakefrequency 指定的频率的线程检查此值。
客户端流程解析:,然后通过rpcCallerFactory. newCaller()执行调用,忽略掉失败重新提交和错误处理,客户端的提交操作到此结束。
1、用户提交put请求后,HBase客户端会将put请求添加到本地buffer中,符合一定条件就会通过AsyncProcess异步批量提交。
HBase默认设置autoflush=true,表示put请求直接会提交给服务器进行处理;
2、用户可以设置autoflush=false,这样的话put请求会首先放到本地buffer,等到本地buffer大小超过一定阈值(默认为2M,可以通过配置文件配置)之后才会提交。很显然,后者采用group commit机制提交请求,可以极大地提升写入性能,但是因为没有保护机制,如果客户端崩溃的话会导致提交的请求丢失。
//提示:
cdh集群中hbase默认是使用autoflush=false 也就是首先会把数据放在本地的buffer中
HBase 客户端写入缓冲
hbase.client.write.buffer = 2M //写入缓冲区大小(以字节为单位)。较大缓冲区需要客户端和服务器中有较大内存,因为服务器将实例化已通过的写入缓冲区并进行处理,这会降低远程过程调用 (RPC) 的数量。为了估计服务器已使用内存的数量,请用值“hbase.client.write.buffer”乘以“hbase.regionserver.handler.count”。
HBase Region Server 处理程序计数
hbase.regionserver.handler.count = 30 //RegionServer 中启动的 RPC 服务器实例数量
3、在提交给服务端之前,HBase会在元数据表.meta.中根据rowkey找到它们归属的region server,这个定位的过程是通过HConnection的locateRegion方法获得的。如果是批量请求的话还会把这些rowkey按照HRegionLocation分组,每个分组可以对应一次RPC请求。
4、HBase会为每个HRegionLocation构造一个远程RPC请求MultiServerCallable
1.部分:客户端的写入流程 客户端流程解析: 1、用户提交put请求后,HBase客户端会将put请求添加到本地buffer中,符合一定条件就会通过AsyncProcess异步批量提交。 HBase默认设置...
2.部分:服务端写入流程 服务端流程解析 (1)获取行锁、Region更新共享锁 -》(2)开始写事务 -》(3)写缓存...
3.部分:WAL机制解析 1、WAL(Write-Ahead Logging)是一种高效的.
第一部分:客户端的写入流程,然后通过rpcCallerFactory. newCaller()执行调用,忽略掉失败重新提交和错误处理,客户端的提交操作到此结束。
客户端流程解析:
1、用户提交put请求后,HBase客户端会将put请求添加到本地buffer中,符合一定条件就会通过AsyncProcess异步批量提交。
HBase默认设置autoflush=true,表示put请求直接会提交给服务器进行处理;
2、用户可以设置autoflush=false,这样的话put请求会首先放到本地buffer,等到本地buffer大小超过一定阈值(默认为2M,可以通过配置文件配置)之后才会提交。很显然,后者采用group commit机制提交请求,可以极大地提升写入性能,但是因为没有保护机制,如果客户端崩溃的话会导致提交的请求丢失。
//提示:
cdh集群中hbase默认是使用autoflush=false 也就是首先会把数据放在本地的buffer中
HBase 客户端写入缓冲
hbase.client.write.buffer = 2M //写入缓冲区大小(以字节为单位)。较大缓冲区需要客户端和服务器中有较大内存,因为服务器将实例化已通过的写入缓冲区并进行处理,这会降低远程过程调用 (RPC) 的数量。为了估计服务器已使用内存的数量,请用值“hbase.client.write.buffer”乘以“hbase.regionserver.handler.count”。
HBase Region Server 处理程序计数
hbase.regionserver.handler.count = 30 //RegionServer 中启动的 RPC 服务器实例数量
3、在提交给服务端之前,HBase会在元数据表.meta.中根据rowkey找到它们归属的region server,这个定位的过程是通过HConnection的locateRegion方法获得的。如果是批量请求的话还会把这些rowkey按照HRegionLocation分组,每个分组可以对应一次RPC请求。
4、HBase会为每个HRegionLocation构造一个远程RPC请求MultiServerCallable
第二部分:服务端写入流程
服务端流程解析
(1)获取行锁、Region更新共享锁 -》(2)开始写事务 -》(3)写缓存memstore -》(4)构造waledit并append hlog - 》 (5)
释放行锁,共享锁 - 》 (6)sync hlog -》(7)结束写事务 - 》(8) flush memstore
//解释
(1)获取行锁、Region更新共享锁: HBase中使用行锁保证对同一行数据的更新都是互斥操作,用以保证更新的原子性,要么更新成功,要么失败。
(2)开始写事务:获取write number,用于实现MVCC,实现数据的非锁定读,在保证读写一致性的前提下提高读取性能。
(3)写缓存memstore:HBase中每列族都会对应一个store,用来存储该列数据。每个store都会有个写缓存memstore,用于缓存写入数据。HBase并不会直接将数据落盘,而是先写入缓存,等缓存满足一定大小之后再一起落盘。
(4)Append HLog:HBase使用WAL机制保证数据可靠性,即首先写日志再写缓存,即使发生宕机,也可以通过恢复HLog还原出原始数据。该步骤就是将数据构造为WALEdit对象,然后顺序写入HLog中,此时不需要执行sync操作。0.98版本采用了新的写线程模式实现HLog日志的写入,可以使得整个数据更新性能得到极大提升,具体原理见下一个章节。
(5)释放行锁以及共享锁
(6)Sync HLog:HLog真正sync到HDFS,在释放行锁之后执行sync操作是为了尽量减少持锁时间,提升写性能。如果Sync失败,执行回滚操作将memstore中已经写入的数据移除。
(7)结束写事务:此时该线程的更新操作才会对其他读请求可见,更新才实际生效。具体分析见文章《数据库事务系列-HBase行级事务模型》
(8)flush memstore:当写缓存满128M之后,会启动flush线程将数据刷新到硬盘。刷新操作涉及到HFile相关结构,后面会详细对此进行介绍。
//HBase Memstore 刷新大小
hbase.hregion.memstore.flush.size = 128M //如 memstore 大小超过此值(字节数),Memstore 将刷新到磁盘。通过运行由 hbase.server.thread.wakefrequency 指定的频率的线程检查此值。
//提示:
我们需要注意,在服务器端写数据的时候,有很多资料是先写到memstore中,再写到wal log中,但是,这样理解不是很准确,因为这好像,违背了wal log的容灾机制,所有,我们可以理解为
先写入到wal log中再写入到memstore中的 //这一步源码中并没有完全的体现出来,可以理解为同步进行。
理论上应该是先写wal log中,HBase这块实现是先写mem,后写WAL,hbase能够保证只有这两个都写完了用户才会可见(mvcc机制),而且如果mem写成功,wal写失败,mem会被回滚。
这样做之所以it’s ok,是由于MVCC来保证的,在每个写线程开启事务的开头就会创建全局递增的write num,但是在HLog更新完毕之后才会去向前推进(roll forward)全局读取点。
所以在此期间内,任何读取线程采用MVCC机制根据读取点读取数据,任何写入/更新操作在HLog未更新完毕之前是不会向前推进读取点的,因此即使数据已经写入memstore,对读线程也是不可见的。
第三部分:WAL机制解析
1、WAL(Write-Ahead Logging)是一种高效的日志算法,几乎是所有非内存数据库提升写性能的不二法门,
2、基本原理是在数据写入之前首先顺序写入日志,然后再写入缓存,等到缓存写满之后统一落盘。
3、之所以能够提升写性能,是因为WAL将一次随机写转化为了一次顺序写加一次内存写。
4、提升写性能的同时,WAL可以保证数据的可靠性,即在任何情况下数据不丢失。
5、假如一次写入完成之后发生了宕机,即使所有缓存中的数据丢失,也可以通过恢复日志还原出丢失的数据。
WAL持久化等级
HBase中可以通过设置WAL的持久化等级决定是否开启WAL机制、以及HLog的落盘方式。
WAL的持久化等级分为如下四个等级:
SKIP_WAL:只写缓存,不写HLog日志。这种方式因为只写内存,因此可以极大的提升写入性能,但是数据有丢失的风险。在实际应用过程中并不建议设置此等级,除非确认不要求数据的可靠性。
ASYNC_WAL:异步将数据写入HLog日志中。
SYNC_WAL:同步将数据写入日志文件中,需要注意的是数据只是被写入文件系统中,并没有真正落盘。
FSYNC_WAL:同步将数据写入日志文件并强制落盘。最严格的日志写入等级,可以保证数据不会丢失,但是性能相对比较差。
USER_DEFAULT:默认如果用户没有指定持久化等级,HBase使用SYNC_WAL等级持久化数据。
用户可以通过客户端设置WAL持久化等级,代码:put.setDurability(Durability. SYNC_WAL );
//cdh中
WAL 提供程序
hbase.wal.provider = //可选项为: //RegionServer 应用于提前写入日志的实施。
RegionServer Default Group
多个 HDFS WAL
单个 HDFS WAL
HBase 默认设置(Single HDFS WAL)
WAL HSM 存储策略
hbase.wal.storage.policy
RegionServer Default Group
所有副本都在 SSD 上
一个副本在 SSD 上,其他副本均在 HDD 上
无(全部在 HDD 上)
关于wal 和 hlog概念的的升入研究 见参考链接写入本地缓存,然后再将本地缓存写入文件系统,最后执行sync操作同步到磁盘
//HLog的写入模型。HLog的写入可以分为三个阶段,首先将数据对
众所周知,HBase默认适用于写多读少的应用,正是依赖于它相当出色的写入性能:一个100台RS的集群可以轻松地支撑每天10T的写入量。当然,为了支持更高吞吐量的写入,HBase还在不断地进行优化和修正,这篇文章结合0.98版本的源码全面地分析HBase的写入流程,全文分为三个部分,第一部分介绍客户端的写入流程,第二部分介绍服务器端的写入流程,最后再重点分析WAL的工作原理。
1、组件架构图
2、相关概念
1)Region
table在行的方向上分隔为多个Region,或者说是根据rowkey分割。Region是HBase中分布式存储和负载均衡的最小单元,即不同的region可以分别在不同的Region Server上,但同一个Region是不会拆分到多个server上。Region按大小分隔,表中每一行只能属于一个region。随着数据不断插入表,region不断增大,当region的某个列族达到一个阈值(默认256M)时就会分成两个新的region。
2)Store
每一个region有一个或多个store组成,至少是一个store,hbase会把一起访问的数据放在一个store里面,即为每个ColumnFamily建一个store(即有几个ColumnFamily,也就有几个Store)。一个Store由一个memStore和0或多个StoreFile组成。
HBase以store的大小来判断是否需要切分region。
3)MemStore
MemStore是放在内存里的。保存修改的数据即
keyValues。当MemStore的大小达到一个阀值(默认64MB)时,MemStore会被flush到文件,即生成一个快照。目前hbase 会有一个线程来负责MemStore的flush操作。4)StoreFile
memStore内存中的数据写到文件后就是StoreFile(即memstore的每次flush操作都会生成一个新的StoreFile),StoreFile底层是以HFile的格式保存。
5. HFile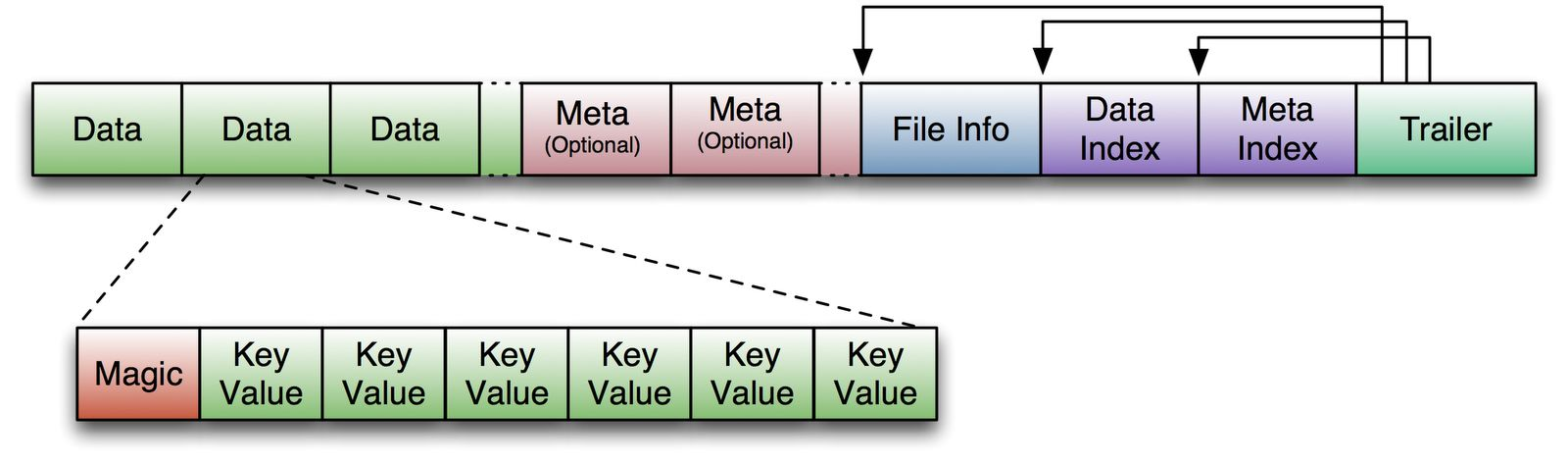
HFile是HBase中KeyValue数据的存储格式,是hadoop的二进制格式文件。一个StoreFile对应着一个HFile。而HFile是存储在HDFS之上的。HFile文件格式是基于Google Bigtable中的SSTable,如下图所示:
首先HFile文件是不定长的,长度固定的只有其中的两块:Trailer和FileInfo。Trailer中又指针指向其他数据块的起始点,FileInfo记录了文件的一些meta信息。
3、数据写入流程
第一部分:客户端的写入流程,然后通过rpcCallerFactory. newCaller()执行调用,忽略掉失败重新提交和错误处理,客户端的提交操作到此结束。
客户端流程解析:
1、用户提交put请求后,HBase客户端会将put请求添加到本地buffer中,符合一定条件就会通过AsyncProcess异步批量提交。
HBase默认设置autoflush=true,表示put请求直接会提交给服务器进行处理;
2、用户可以设置autoflush=false,这样的话put请求会首先放到本地buffer,等到本地buffer大小超过一定阈值(默认为2M,可以通过配置文件配置)之后才会提交。很显然,后者采用group commit机制提交请求,可以极大地提升写入性能,但是因为没有保护机制,如果客户端崩溃的话会导致提交的请求丢失。
//提示:
cdh集群中hbase默认是使用autoflush=false 也就是首先会把数据放在本地的buffer中
HBase 客户端写入缓冲
hbase.client.write.buffer = 2M //写入缓冲区大小(以字节为单位)。较大缓冲区需要客户端和服务器中有较大内存,因为服务器将实例化已通过的写入缓冲区并进行处理,这会降低远程过程调用 (RPC) 的数量。为了估计服务器已使用内存的数量,请用值“hbase.client.write.buffer”乘以“hbase.regionserver.handler.count”。
HBase Region Server 处理程序计数
hbase.regionserver.handler.count = 30 //RegionServer 中启动的 RPC 服务器实例数量
3、在提交给服务端之前,HBase会在元数据表.meta.中根据rowkey找到它们归属的region server,这个定位的过程是通过HConnection的locateRegion方法获得的。如果是批量请求的话还会把这些rowkey按照HRegionLocation分组,每个分组可以对应一次RPC请求。
4、HBase会为每个HRegionLocation构造一个远程RPC请求MultiServerCallable
第二部分:服务端写入流程
服务端流程解析
(1)获取行锁、Region更新共享锁 -》(2)开始写事务 -》(3)写缓存memstore -》(4)构造waledit并append hlog - 》 (5)
释放行锁,共享锁 - 》 (6)sync hlog -》(7)结束写事务 - 》(8) flush memstore
//解释
(1)获取行锁、Region更新共享锁: HBase中使用行锁保证对同一行数据的更新都是互斥操作,用以保证更新的原子性,要么更新成功,要么失败。
(2)开始写事务:获取write number,用于实现MVCC,实现数据的非锁定读,在保证读写一致性的前提下提高读取性能。
(3)写缓存memstore:HBase中每列族都会对应一个store,用来存储该列数据。每个store都会有个写缓存memstore,用于缓存写入数据。HBase并不会直接将数据落盘,而是先写入缓存,等缓存满足一定大小之后再一起落盘。
(4)Append HLog:HBase使用WAL机制保证数据可靠性,即首先写日志再写缓存,即使发生宕机,也可以通过恢复HLog还原出原始数据。该步骤就是将数据构造为WALEdit对象,然后顺序写入HLog中,此时不需要执行sync操作。0.98版本采用了新的写线程模式实现HLog日志的写入,可以使得整个数据更新性能得到极大提升,具体原理见下一个章节。
(5)释放行锁以及共享锁
(6)Sync HLog:HLog真正sync到HDFS,在释放行锁之后执行sync操作是为了尽量减少持锁时间,提升写性能。如果Sync失败,执行回滚操作将memstore中已经写入的数据移除。
(7)结束写事务:此时该线程的更新操作才会对其他读请求可见,更新才实际生效。具体分析见文章《数据库事务系列-HBase行级事务模型》
(8)flush memstore:当写缓存满128M之后,会启动flush线程将数据刷新到硬盘。刷新操作涉及到HFile相关结构,后面会详细对此进行介绍。
//HBase Memstore 刷新大小
hbase.hregion.memstore.flush.size = 128M //如 memstore 大小超过此值(字节数),Memstore 将刷新到磁盘。通过运行由 hbase.server.thread.wakefrequency 指定的频率的线程检查此值。
//提示:
我们需要注意,在服务器端写数据的时候,有很多资料是先写到memstore中,再写到wal log中,但是,这样理解不是很准确,因为这好像,违背了wal log的容灾机制,所有,我们可以理解为
先写入到wal log中再写入到memstore中的 //这一步源码中并没有完全的体现出来,可以理解为同步进行。
理论上应该是先写wal log中,HBase这块实现是先写mem,后写WAL,hbase能够保证只有这两个都写完了用户才会可见(mvcc机制),而且如果mem写成功,wal写失败,mem会被回滚。
这样做之所以it’s ok,是由于MVCC来保证的,在每个写线程开启事务的开头就会创建全局递增的write num,但是在HLog更新完毕之后才会去向前推进(roll forward)全局读取点。
所以在此期间内,任何读取线程采用MVCC机制根据读取点读取数据,任何写入/更新操作在HLog未更新完毕之前是不会向前推进读取点的,因此即使数据已经写入memstore,对读线程也是不可见的。
第三部分:WAL机制解析
1、WAL(Write-Ahead Logging)是一种高效的日志算法,几乎是所有非内存数据库提升写性能的不二法门,
2、基本原理是在数据写入之前首先顺序写入日志,然后再写入缓存,等到缓存写满之后统一落盘。
3、之所以能够提升写性能,是因为WAL将一次随机写转化为了一次顺序写加一次内存写。
4、提升写性能的同时,WAL可以保证数据的可靠性,即在任何情况下数据不丢失。
5、假如一次写入完成之后发生了宕机,即使所有缓存中的数据丢失,也可以通过恢复日志还原出丢失的数据。
WAL持久化等级
HBase中可以通过设置WAL的持久化等级决定是否开启WAL机制、以及HLog的落盘方式。
WAL的持久化等级分为如下四个等级:
SKIP_WAL:只写缓存,不写HLog日志。这种方式因为只写内存,因此可以极大的提升写入性能,但是数据有丢失的风险。在实际应用过程中并不建议设置此等级,除非确认不要求数据的可靠性。
ASYNC_WAL:异步将数据写入HLog日志中。
SYNC_WAL:同步将数据写入日志文件中,需要注意的是数据只是被写入文件系统中,并没有真正落盘。
FSYNC_WAL:同步将数据写入日志文件并强制落盘。最严格的日志写入等级,可以保证数据不会丢失,但是性能相对比较差。
USER_DEFAULT:默认如果用户没有指定持久化等级,HBase使用SYNC_WAL等级持久化数据。
用户可以通过客户端设置WAL持久化等级,代码:put.setDurability(Durability. SYNC_WAL );
//cdh中
WAL 提供程序
hbase.wal.provider = //可选项为: //RegionServer 应用于提前写入日志的实施。
RegionServer Default Group
多个 HDFS WAL
单个 HDFS WAL
HBase 默认设置(Single HDFS WAL)
WAL HSM 存储策略
hbase.wal.storage.policy
RegionServer Default Group
所有副本都在 SSD 上
一个副本在 SSD 上,其他副本均在 HDD 上
无(全部在 HDD 上)
关于wal 和 hlog概念的的升入研究 见参考链接写入本地缓存,然后再将本地缓存写入文件系统,最后执行sync操作同步到磁盘。
//HLog的写入模型。HLog的写入可以分为三个阶段,首先将数据对
相关问题推荐
可以调一下系统时间,使用date命令,一般节点掉了都是时间不同步。
Hbase安装与启动一,前言二,前期准备 2.1 文件下载 2.2 服务器准备三,配置文件配置 3.1 hbase-env.sh 3.2 hbase-site.xml 3.3 regionservers 3.4 将hbase的bin目录添加到环境变量 3.5 Hbase的官方配置文档四,Hbase服务启动 4.1 ...
首先介绍部署 HBase 之前需要做的准备工作,如 Java、SSH 和 Hadoop 这些先决条件的配置;然后介绍如何安装 HBase,以及如何配置集群中相关文件。同时需要注意的是,本节介绍的是分布式 HBase 集群的部署,在对一台机器修改配置文件后需要同步到集群中的所有...
HBase安装HBase的安装也分为三种,单机版、伪分布式、分布式。我们首先来安装单机版。单机版首先我们去官网下载好HBase的安装包;接下来,将压缩包解压缩到你想安装的目录(我解压到的是/app目录):tar -zxvf hbase-2.1.0-bin.tar.gz /app安装单机版很简...
HBase分布式数据库具有如下的显著特点:容量大:HBase分布式数据库中的表可以存储成千上万的行和列组成的数据。面向列:HBase是面向列的存储和权限控制,并支持独立检索。列存储,其数据在表中是按照某列存储的,根据数据动态的增加列,并且可以单独对列进行...
1、查看单行记录:get '表名称', '行名称'2、查看表中的记录总数:count '表名称'3、查看表所有记录:scan 表名称4、查看表某个列所有记录:scan 表名称 , ['列名称:']5、查看有哪些表:list6、查看表结构:describe '表...
hbase与传统数据库的区别1.数据类型:Hbase只有简单的数据类型,只保留字符串;传统数据库有丰富的数据类型。2.数据操作:Hbase只有简单的插入、查询、删除、清空等操作,表和表之间是分离的,没有复杂的表和表之间的关系;传统数据库通常有各式各样的函数和连...
1、HBase写快读慢,HBase的读取时长通常是几毫秒,而Redis的读取时长通常是几十微秒。性能相差非常大。2、HBase和Redis都支持KV类型。但是Redis支持List、Set等更丰富的类型。3、Redis支持的数据量通常受内存限制,而HBase没有这个限制,可以存储远超内存大小...
启动HBase集群:bin/start-hbase.sh单独启动一个HMaster进程:bin/hbase-daemon.sh start master单独启动一个HRegionServer进程:bin/hbase-daemon.sh start regionserver
hbase的八大应用场景1、对象存储:我们知道不少的头条类、新闻类的的新闻、网页、图片存储在HBase之中,一些病毒公司的病毒库也是存储在HBase之中2、时序数据:HBase之上有OpenTSDB模块,可以满足时序类场景的需求3、推荐画像:特别是用户的画像,是一个比较...
1、频繁刷写我们知道Region的一个列族对应一个MemStore,假设HBase表都有统一的1个列族配置,则每个Region只包含一个MemStore。通常HBase的一个MemStore默认大小为128 MB,见参数hbase.hregion.memstore.flush.size。当可用内存足够时,每个MemStore可以分配...
避免HBase经常split,产生不必要的资源消耗,提高HBase的性能。
HBase每张表在底层存储上是由至少一个Region组成,Region实际上就是HBase表的分区。HBase新建一张表时默认Region即分区的数量为1,一般在生产环境中我们都会手动给Table提前做 预分区,使用合适的分区策略创建好一定数量的分区并使分区均匀分布在不同regions...
关于每个regionserver节点分区数量大致合理的范围,HBase官网上也给出了定义:Generally less regions makes for a smoother running cluster (you can always manually split the big regions later (if necessary) to spread the data, or re......