1 import math2 for i in range(10000):3 #转化为整型值4 x = int(math.sqrt(i + 100))5 y = int(math.sqrt(i + 268))6 if(x * x == i + 100) and (y * y == i + 268):7 print i
1 from sys import stdout 2 n = int(raw_input("input number:\n")) 3 print "n = %d" % n 4 5 for i in range(2,n + 1): 6 while n != i: 7 if n % i == 0: 8 stdout.write(str(i)) 9 stdout.write("*")10 n = n / i11 else:12 break13 print "%d" % n
1 Tn = 0 2 Sn = [] 3 n = int(raw_input('n = :\n')) 4 a = int(raw_input('a = :\n')) 5 for count in range(n): 6 Tn = Tn + a 7 a = a * 10 8 Sn.append(Tn) 9 print Tn10 11 Sn = reduce(lambda x,y : x + y,Sn)12 print Sn
1 from sys import stdout 2 for j in range(2,1001): 3 k = [] 4 n = -1 5 s = j 6 for i in range(1,j): 7 if j % i == 0: 8 n += 1 9 s -= i10 k.append(i)11 12 if s == 0:13 print j14 for i in range(n):15 stdout.write(str(k[i]))16 stdout.write(' ')17 print k[n]
1 #!/usr/bin/python 2 # -*- coding: UTF-8 -*- 3 4 a = 2.0 5 b = 1.0 6 s = 0 7 for n in range(1,21): 8 s += a / b 9 t = a10 a = a + b11 b = t12 print s
方法二:
1 #!/usr/bin/python 2 # -*- coding: UTF-8 -*- 3 4 a = 2.0 5 b = 1.0 6 s = 0.0 7 for n in range(1,21): 8 s += a / b 9 b,a = a , a + b10 print s11 12 s = 0.013 for n in range(1,21):14 s += a / b15 b,a = a , a + b16 print s
方法三:
1 #!/usr/bin/python 2 # -*- coding: UTF-8 -*- 3 4 a = 2.0 5 b = 1.0 6 l = [] 7 for n in range(1,21): 8 b,a = a,a + b 9 l.append(a / b)10 print reduce(lambda x,y: x + y,l)
以上实例输出结果为:
32.6602607986
十、算法题目:利用递归方法求5!。
程序分析:递归公式:fn=fn_1*4!
程序源代码:
1 #!/usr/bin/python 2 # -*- coding: UTF-8 -*- 3 4 def fact(j): 5 sum = 0 6 if j == 0: 7 sum = 1 8 else: 9 sum = j * fact(j - 1)10 return sum11 12 for i in range(5):13 print '%d! = %d' % (i,fact(i))
{var%20f='http://v.t.sina.com.cn/share/share.php?appkey=1515056452',u=z||d.location,p=['&url=',e(u),'&title=',e(t||d.title),'&source=',e(r),'&sourceUrl=',e(l),'&content=',c||'gb2312','&pic=',e(p||'')].join('');function%20a(){if(!window.open([f,p].join(''),'mb',['toolbar=0,status=0,resizable=1,width=440,height=430,left=',(s.width-440)/2,',top=',(s.height-430)/2].join('')))u.href=[f,p].join('');};if(/Firefox/.test(navigator.userAgent))setTimeout(a,0);else%20a();})(screen,document,encodeURIComponent,'','','/static/images/logo.png', '推荐 nove 的问题《python中有哪些简单的算法》','http://www.shouhuola.com/q-18426.html','页面编码gb2312|utf-8默认gb2312'));){kind=link}
十种常见排序算法一般分为以下几种:
(1)非线性时间比较类排序:
a. 交换类排序(快速排序、冒泡排序)
b. 插入类排序(简单插入排序、希尔排序)
c. 选择类排序(简单选择排序、堆排序)
d. 归并排序(二路归并排序、多路归并排序)
(2)线性时间非比较类排序:
a. 技术排序
b. 基数排序
c. 桶排序
总结:
(1)在比较类排序种,归并排序号称最快,其次是快速排序和堆排序,两者不相伯仲,但是有一点需要注意,数据初始排序状态对堆排序不会产生太大的影响,而快速排序却恰恰相反。
(2)线性时间非比较类排序一般要优于非线性时间比较类排序,但前者对待排序元素的要求较为严格,比如计数排序要求待待排序数的最大值不能太大,桶排序要求元素按照hash分桶后桶内元素的数量要均匀。线性时间非比计较类排序的典型特点是以空间换时间。
如下图: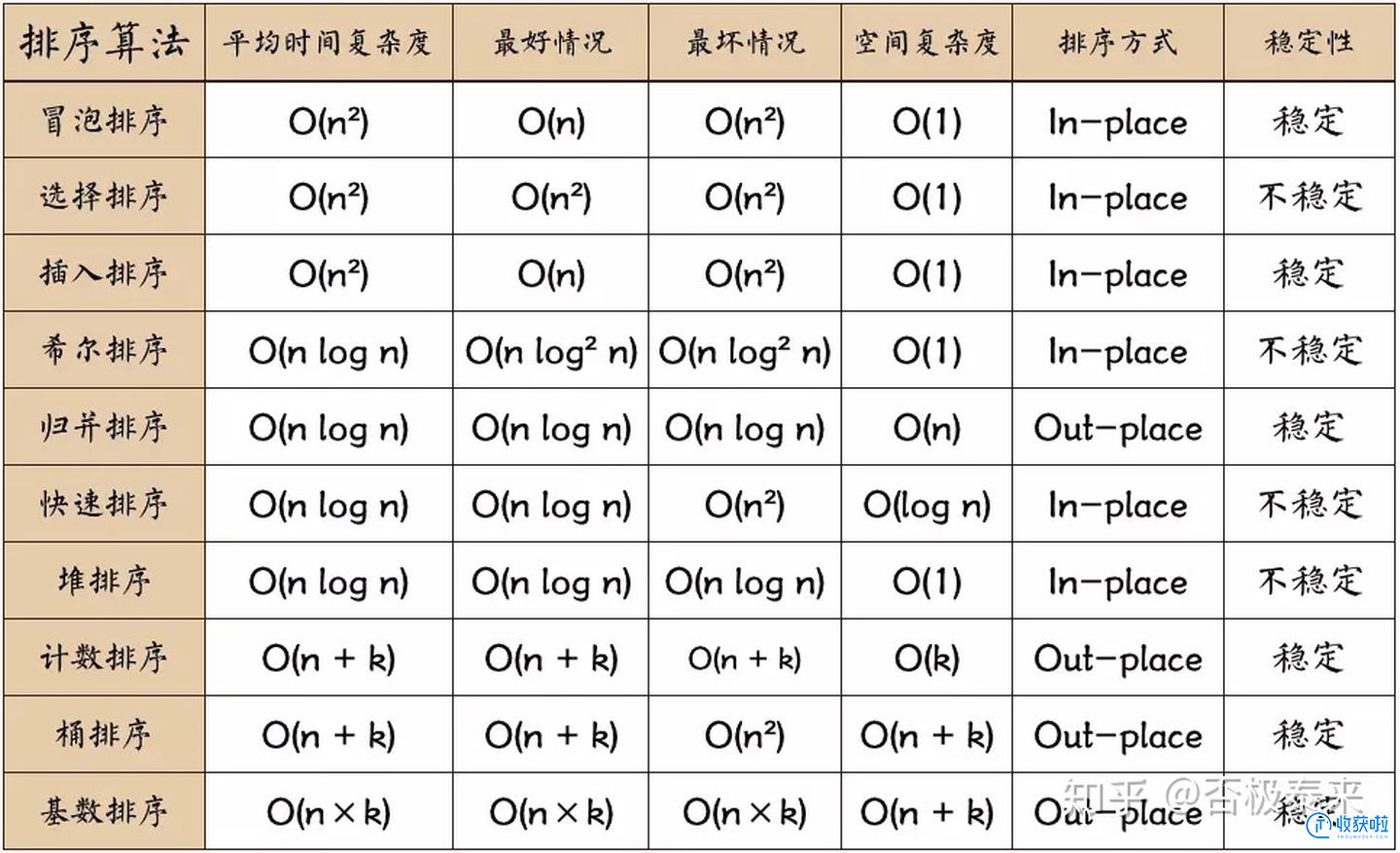
排序,查找等。使用起来都很简单
首先谢谢邀请,
python中有的算法还是比较多的?
python之所以火是因为人工智能的发展,人工智能的发展离不开算法!
感觉有本书比较适合你,不过可惜的是这本书没有电子版,只有纸质的。
这本书对于算法从基本的入门到实现,循序渐进的介绍,比如里面就涵盖了数学建模的常用算法。
回答: 2021-11-24 14:39
跟你详细说一下python的常用8大算法:
1、插入排序
插入排序的基本操作就是将一个数据插入到已经排好序的有序数据中,从而得到一个新的、个数加一的有序数据,算法适用于少量数据的排序,时间复杂度为O(n^2)。是稳定的排序方法。插入算法把要排序的数组分成两部分:第一部分包含了这个数组的所有元素,但将最后一个元素除外(让数组多一个空间才有插入的位置),而第二部分就只包含这一个元素(即待插入元素)。在第一部分排序完成后,再将这个最后元素插入到已排好序的第一部分中。
2、希尔排序
希尔排序(Shell Sort)是插入排序的一种。也称缩小增量排序,是直接插入排序算法的一种更高效的改进版本。希尔排序是非稳定排序算法。该方法因DL.Shell于1959年提出而得名。 希尔排序是把记录按下标的一定增量分组,对每组使用直接插入排序算法排序;随着增量逐渐减少,每组包含的关键词越来越多,当增量减至1时,整个文件恰被分成一组,算法便终止。
3、冒泡排序
它重复地走访过要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来。走访数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成。
4、快速排序
通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列。
5、直接选择排序
基本思想:第1趟,在待排序记录r1 ~ r[n]中选出最小的记录,将它与r1交换;第2趟,在待排序记录r2 ~ r[n]中选出最小的记录,将它与r2交换;以此类推,第i趟在待排序记录r[i] ~ r[n]中选出最小的记录,将它与r[i]交换,使有序序列不断增长直到全部排序完毕。
6、堆排序
堆排序(Heapsort)是指利用堆积树(堆)这种数据结构所设计的一种排序算法,它是选择排序的一种。可以利用数组的特点快速定位指定索引的元素。堆分为大根堆和小根堆,是完全二叉树。大根堆的要求是每个节点的值都不大于其父节点的值,即A[PARENT[i]] >= A[i]。在数组的非降序排序中,需要使用的就是大根堆,因为根据大根堆的要求可知,最大的值一定在堆顶。
7、归并排序
归并排序是建立在归并操作上的一种有效的排序算法,该算法是采用分治法(Divide and Conquer)的一个非常典型的应用。将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成一个有序表,称为二路归并。
归并过程为:比较a[i]和a[j]的大小,若a[i]≤a[j],则将第一个有序表中的元素a[i]复制到r[k]中,并令i和k分别加上1;否则将第二个有序表中的元素a[j]复制到r[k]中,并令j和k分别加上1,如此循环下去,直到其中一个有序表取完,然后再将另一个有序表中剩余的元素复制到r中从下标k到下标t的单元。归并排序的算法我们通常用递归实现,先把待排序区间[s,t]以中点二分,接着把左边子区间排序,再把右边子区间排序,最后把左区间和右区间用一次归并操作合并成有序的区间[s,t]。
8、基数排序
基数排序(radix sort)属于“分配式排序”(distribution sort),又称“桶子法”(bucket sort)或bin sort,顾名思义,它是透过键值的部分资讯,将要排序的元素分配至某些“桶”中,藉以达到排序的作用,基数排序法是属于稳定性的排序,其时间复杂度为O (nlog(r)m),其中r为所采取的基数,而m为堆数,在某些时候,基数排序法的效率高于其它的稳定性排序法。
1.线性回归算法 在线性回归中,我们想要建立一个模型,来拟合一个因变量 y 与一个或多个独立自变量(预测变量) x 之间的关系。 是一个目标变量,它是一个标量 线性回归模型可以理解为一个非常简单的神经网络
2.Logistic 回归算法 在Logistic 回归中,我们试图对给定输入特征的线性组合进行建模,来得到其二元变量的输出结果。例如,我们可以尝试使用竞选候选人花费的金钱和时间信息来预测选举的结果(胜或负)
回答: 2021-11-12 10:27
python相对于其他语言编写算法还是比较简单的。
常用的算法有:排序,查找等。使用起来都很简单。并且python还内置了排序算法和查找算法,使用非常方面。
一、算法题目:有1、2、3、4个数字,能组成多少个互不相同且无重复数字的三位数?都是多少?
程序分析:可填在百位、十位、个位的数字都是1、2、3、4。组成所有的排列后再去 掉不满足条件的排列。
程序源代码:
实例输出结果为:
二、算法题目:一个整数,它加上100和加上268后都是一个完全平方数,请问该数是多少?
程序分析:在10000以内判断,将该数加上100后再开方,加上268后再开方,如果开方后的结果满足如下条件,即是结果。请看具体分析:
程序源代码:
实例输出结果为:
三、算法题目:输入某年某月某日,判断这一天是这一年的第几天?
程序分析:以3月5日为例,应该先把前两个月的加起来,然后再加上5天即本年的第几天,特殊情况,闰年且输入月份大于3时需考虑多加一天:
程序源代码:
1 year = int(raw_input('year:\n')) 2 month = int(raw_input('month:\n')) 3 day = int(raw_input('day:\n')) 4 5 months = (0,31,59,90,120,151,181,212,243,273,304,334) 6 if 0 < month <= 12: 7 sum = months[month - 1] 8 else: 9 print 'data error'10 sum += day11 leap = 012 if (year % 400 == 0) or ((year % 4 == 0) and (year % 100 != 0)):13 leap = 114 if (leap == 1) and (month > 2):15 sum += 116 print 'it is the %dth day.' % sum实例输出结果为:
四、算法题目:斐波那契数列。
程序分析:斐波那契数列(Fibonacci sequence),又称黄金分割数列,指的是这样一个数列:0、1、1、2、3、5、8、13、21、34、……。
在数学上,费波那契数列是以递归的方法来定义:
程序源代码:
方法一
方法二
以上实例输出了第10个斐波那契数列,结果为:
方法三
如果你需要输出指定个数的斐波那契数列,可以使用以下代码:
程序运行输出结果为:
五、算法题目:打印出所有的"水仙花数",所谓"水仙花数"是指一个三位数,其各位数字立方和等于该数本身。例如:153是一个"水仙花数",因为153=1的三次方+5的三次方+3的三次方。
程序分析:利用for循环控制100-999个数,每个数分解出个位,十位,百位。
程序源代码:
实例输出结果为:
六、算法题目:将一个正整数分解质因数。例如:输入90,打印出90=2*3*3*5。
程序分析:对n进行分解质因数,应先找到一个最小的质数k,然后按下述步骤完成:
(1)如果这个质数恰等于n,则说明分解质因数的过程已经结束,打印出即可。
(2)如果n<>k,但n能被k整除,则应打印出k的值,并用n除以k的商,作为新的正整数你n,重复执行第一步。
(3)如果n不能被k整除,则用k+1作为k的值,重复执行第一步。
程序源代码:
1 from sys import stdout 2 n = int(raw_input("input number:\n")) 3 print "n = %d" % n 4 5 for i in range(2,n + 1): 6 while n != i: 7 if n % i == 0: 8 stdout.write(str(i)) 9 stdout.write("*")10 n = n / i11 else:12 break13 print "%d" % n实例输出结果为:
七、算法题目:求s=a+aa+aaa+aaaa+aa...a的值,其中a是一个数字。例如2+22+222+2222+22222(此时共有5个数相加),几个数相加有键盘控制。
程序分析:关键是计算出每一项的值。
程序源代码:
1 Tn = 0 2 Sn = [] 3 n = int(raw_input('n = :\n')) 4 a = int(raw_input('a = :\n')) 5 for count in range(n): 6 Tn = Tn + a 7 a = a * 10 8 Sn.append(Tn) 9 print Tn10 11 Sn = reduce(lambda x,y : x + y,Sn)12 print Sn实例输出结果为:
八、算法题目:一个数如果恰好等于它的因子之和,这个数就称为"完数"。例如6=1+2+3.编程找出1000以内的所有完数。
程序分析:对n进行分解质因数,应先找到一个最小的质数k,然后按下述步骤完成:
(1)如果这个质数恰等于n,则说明分解质因数的过程已经结束,打印出即可。
(2)如果n<>k,但n能被k整除,则应打印出k的值,并用n除以k的商,作为新的正整数你n,重复执行第一步。
(3)如果n不能被k整除,则用k+1作为k的值,重复执行第一步。
程序源代码:
1 from sys import stdout 2 for j in range(2,1001): 3 k = [] 4 n = -1 5 s = j 6 for i in range(1,j): 7 if j % i == 0: 8 n += 1 9 s -= i10 k.append(i)11 12 if s == 0:13 print j14 for i in range(n):15 stdout.write(str(k[i]))16 stdout.write(' ')17 print k[n]实例输出结果为:
九、算法题目:有一分数序列:2/1,3/2,5/3,8/5,13/8,21/13...求出这个数列的前20项之和。
程序分析:请抓住分子与分母的变化规律。
程序源代码:
方法一:
方法二:
方法三:
以上实例输出结果为:
十、算法题目:利用递归方法求5!。
程序分析:递归公式:fn=fn_1*4!
程序源代码:
实例输出结果为:
找些简单的算法拿来敲一敲~!
python相对于其他语言编写算法还是比较简单的。
常用的算法有:排序,查找等。使用起来都很简单。并且python还内置了排序算法和查找算法,使用非常方面。
归并算法,二分算法,贪心算法,等等等
很多简单的算法比如。(Algorithm)是指解题方案的准确而完整的描述,是一系列解决问题的清晰指令,算法代表着用系统的方法描述解决问题的策略机制。常用的算法:选择排序、快速排序、二分查找、广度优先搜索、贪婪算法,等等。”
相关问题推荐
换行。比如,print hello\nworld效果就是helloworld\n就是一个换行符。\是转义的意思,'\n'是换行,'\t'是tab,'\\'是,\ 是在编写程序中句子太长百,人为换行后加上\但print出来是一整行。...
前景很好,中国正在产业升级,工业机器人和人工智能方面都会是强烈的热点,而且正好是在3~5年以后的时间。难度,肯定高,要求你有创新的思维能力,高数中的微积分、数列等等必须得非常好,软件编程(基础的应用最广泛的语言:C/C++)必须得很好,微电子(数字电...
迭代器与生成器的区别:(1)生成器:生成器本质上就是一个函数,它记住了上一次返回时在函数体中的位置。对生成器函数的第二次(或第n次)调用,跳转到函数上一次挂起的位置。而且记录了程序执行的上下文。生成器不仅记住了它的数据状态,生成器还记住了程序...
python中title( )属于python中字符串函数,返回’标题化‘的字符串,就是单词的开头为大写,其余为小写
第一种解释:代码中的cnt是count的简称,一种电脑计算机内部的数学函数的名字,在Excel办公软件中计算参数列表中的数字项的个数;在数据库( sq| server或者access )中可以用来统计符合条件的数据条数。函数COUNT在计数时,将把数值型的数字计算进去;但是...
head是方法,所以需要取小括号,即dataset.head()显示的则是前5行。data[:, :-1]和data[:, -1]。另外,如果想通过位置取数据,请使用iloc,即dataset.iloc[:, :-1]和dataset.iloc[:, -1],前者表示的是取所有行,但不包括最后一列的数据,结果是个DataFrame。...
挺简单的,其实课程内容没有我们想象的那么难、像我之前同学,完全零基础,培训了半年,直接出来就工作了,人家还在北京大公司上班,一个月15k,实力老厉害了
Python针对众多的类型,提供了众多的内建函数来处理(内建是相对于导入import来说的,后面学习到包package时,将会介绍),这些内建函数功用在于其往往可对多种类型对象进行类似的操作,即多种类型对象的共有的操作;如果某种操作只对特殊的某一类对象可行,Pyt...
相当于 ... 这里不是注释
还有FIXME
python的两个库:xlrd和xlutils。 xlrd打开excel,但是打开的excel并不能直接写入数据,需要用xlutils主要是复制一份出来,实现后续的写入功能。
单行注释:Python中的单行注释一般是以#开头的,#右边的文字都会被当做解释说明的内容,不会被当做执行的程序。为了保证代码的可读性,一般会在#后面加一两个空格然后在编写解释内容。示例:# 单行注释print(hello world)注释可以放在代码上面也可以放在代...
主要是按行读取,然后就是写出判断逻辑来勘测行是否为注视行,空行,编码行其他的:import linecachefile=open('3_2.txt','r')linecount=len(file.readlines())linecache.getline('3_2.txt',linecount)这样做的过程中发现一个问题,...
或许是里面有没被注释的代码
自学的话要看个人情况,可以先在B站找一下视频看一下