2020-07-06 10:29发布
指对神经网络沿着从输入层到输出层的顺序,依次计算并存储模型的中间变量(包括输出),下图中左下角x为输入,右上角J为输出,方框代表变量,圆圈代表运算符,箭头表示从输入到输出之间的依赖关系。
输入样本为:x∈Rd,不考虑偏差,则中间变量为:
是隐藏层的权重。将 输入按元素计算的激活函数 ,得到长度为h的向量(隐藏层变量) ,h 也是中间变量。
假设输出层只有权重 ,可得长度为q的向量(输出层变量)
设损失函数为ℓ ,且样本标签为y,则单个数据样本的损失为:
由L2范数定义,给定超参数λ ,正则化项为:
矩阵的Frobenius范数等价于将矩阵变平为向量后计算L2范数,最终模型带正则化的损失为:
是指计算神经网络参数梯度的方法。依据微积分中的链式法则,沿着从输出层到输入层的顺序,依次计算并存储目标函数有关神经网络各层的中间变量以及参数的梯度。
链式法则
对输入或输出X,Y,Z 为任意形状张量的函数Y=f(X) 和Z=g(Y) ,根据链式法则有:
prod运算符将根据两个输入的形状,在必要的操作(如转置和互换输入位置)后对两个输入做乘法
根据以上计算图,反向传播目标是求: 和
这里应用链式法则依次计算各中间变量和参数的梯度,其计算次序与前向传播中相应中间变量的计算次序恰恰相反
目标函数 关于损失L和正则化项s的梯度为:
J 关于输出层变量o 的梯度 为:
(J 和L 为标量,o 为长度为q的向量,所有求导后变成q维向量,详见矩阵求导)
正则化项s 关于两个权重参数的梯度:
先计算靠近输出层的参数W(2) 的梯度: :
沿输出层向隐藏层继续反向传播,隐藏层变量h的梯度: 为:
于激活函数ϕ是按元素运算的,中间变量z的梯度 的计算需要使用按元素乘法符⊙:
最终得到最靠近输入层的模型参数W(1)的梯度: 为:
在训练深度学习模型时,正向传播和反向传播之间相互依赖
正向传播的计算可能依赖于模型参数的当前值,而这些模型参数是在反向传播的梯度计算后通过优化算法迭代的,如计算正则化项s,依赖模型参数W(1)和W(2)的当前值,而这些当前值是优化算法最近一次根据反向传播算出梯度后迭代得到的
反向传播的梯度计算可能依赖于各变量的当前值,而这些变量的当前值是通过正向传播计算得到的,如∂J/∂W(2)计算需要依赖隐藏层变量的当前值hh。这个当前值是通过从输入层到输出层的正向传播计算并存储得到的
在反向传播中使用了正向传播中计算得到的中间变量来避免重复计算,这导致正向传播结束后不能立即释放中间变量内存。这也是训练要比预测占用更多内存的一个重要原因
中间变量的个数大体上与网络层数线性相关,每个变量的大小与批量大小和输入个数也是线性相关的,它们是导致较深的神经网络使用较大批量训练时更容易超内存的主要原因
换行。比如,print hello\nworld效果就是helloworld\n就是一个换行符。\是转义的意思,'\n'是换行,'\t'是tab,'\\'是,\ 是在编写程序中句子太长百,人为换行后加上\但print出来是一整行。...
十种常见排序算法一般分为以下几种:(1)非线性时间比较类排序:a. 交换类排序(快速排序、冒泡排序)b. 插入类排序(简单插入排序、希尔排序)c. 选择类排序(简单选择排序、堆排序)d. 归并排序(二路归并排序、多路归并排序)(2)线性时间非比较类排序:...
前景很好,中国正在产业升级,工业机器人和人工智能方面都会是强烈的热点,而且正好是在3~5年以后的时间。难度,肯定高,要求你有创新的思维能力,高数中的微积分、数列等等必须得非常好,软件编程(基础的应用最广泛的语言:C/C++)必须得很好,微电子(数字电...
迭代器与生成器的区别:(1)生成器:生成器本质上就是一个函数,它记住了上一次返回时在函数体中的位置。对生成器函数的第二次(或第n次)调用,跳转到函数上一次挂起的位置。而且记录了程序执行的上下文。生成器不仅记住了它的数据状态,生成器还记住了程序...
python中title( )属于python中字符串函数,返回’标题化‘的字符串,就是单词的开头为大写,其余为小写
第一种解释:代码中的cnt是count的简称,一种电脑计算机内部的数学函数的名字,在Excel办公软件中计算参数列表中的数字项的个数;在数据库( sq| server或者access )中可以用来统计符合条件的数据条数。函数COUNT在计数时,将把数值型的数字计算进去;但是...
head是方法,所以需要取小括号,即dataset.head()显示的则是前5行。data[:, :-1]和data[:, -1]。另外,如果想通过位置取数据,请使用iloc,即dataset.iloc[:, :-1]和dataset.iloc[:, -1],前者表示的是取所有行,但不包括最后一列的数据,结果是个DataFrame。...
挺简单的,其实课程内容没有我们想象的那么难、像我之前同学,完全零基础,培训了半年,直接出来就工作了,人家还在北京大公司上班,一个月15k,实力老厉害了
Python针对众多的类型,提供了众多的内建函数来处理(内建是相对于导入import来说的,后面学习到包package时,将会介绍),这些内建函数功用在于其往往可对多种类型对象进行类似的操作,即多种类型对象的共有的操作;如果某种操作只对特殊的某一类对象可行,Pyt...
相当于 ... 这里不是注释
还有FIXME
python的两个库:xlrd和xlutils。 xlrd打开excel,但是打开的excel并不能直接写入数据,需要用xlutils主要是复制一份出来,实现后续的写入功能。
单行注释:Python中的单行注释一般是以#开头的,#右边的文字都会被当做解释说明的内容,不会被当做执行的程序。为了保证代码的可读性,一般会在#后面加一两个空格然后在编写解释内容。示例:# 单行注释print(hello world)注释可以放在代码上面也可以放在代...
主要是按行读取,然后就是写出判断逻辑来勘测行是否为注视行,空行,编码行其他的:import linecachefile=open('3_2.txt','r')linecount=len(file.readlines())linecache.getline('3_2.txt',linecount)这样做的过程中发现一个问题,...
或许是里面有没被注释的代码
自学的话要看个人情况,可以先在B站找一下视频看一下
最多设置5个标签!
{var%20f='http://v.t.sina.com.cn/share/share.php?appkey=1515056452',u=z||d.location,p=['&url=',e(u),'&title=',e(t||d.title),'&source=',e(r),'&sourceUrl=',e(l),'&content=',c||'gb2312','&pic=',e(p||'')].join('');function%20a(){if(!window.open([f,p].join(''),'mb',['toolbar=0,status=0,resizable=1,width=440,height=430,left=',(s.width-440)/2,',top=',(s.height-430)/2].join('')))u.href=[f,p].join('');};if(/Firefox/.test(navigator.userAgent))setTimeout(a,0);else%20a();})(screen,document,encodeURIComponent,'','','/static/images/logo.png', '推荐 雨陵西 的问题《正向传播和反向传播在深度学习中是如何工作的?》','http://www.shouhuola.com/q-22244.html','页面编码gb2312|utf-8默认gb2312'));){kind=link}
正向传播(forward propagation)
指对神经网络沿着从输入层到输出层的顺序,依次计算并存储模型的中间变量(包括输出),下图中左下角x为输入,右上角J为输出,方框代表变量,圆圈代表运算符,箭头表示从输入到输出之间的依赖关系。
输入样本为:x∈Rd,不考虑偏差,则中间变量为:
假设输出层只有权重 ,可得长度为q的向量(输出层变量)
,可得长度为q的向量(输出层变量)
设损失函数为ℓ ,且样本标签为y,则单个数据样本的损失为:
由L2范数定义,给定超参数λ ,正则化项为:
矩阵的Frobenius范数等价于将矩阵变平为向量后计算L2范数,最终模型带正则化的损失为:
是指计算神经网络参数梯度的方法。依据微积分中的链式法则,沿着从输出层到输入层的顺序,依次计算并存储目标函数有关神经网络各层的中间变量以及参数的梯度。
链式法则
对输入或输出X,Y,Z 为任意形状张量的函数Y=f(X) 和Z=g(Y) ,根据链式法则有:
prod运算符将根据两个输入的形状,在必要的操作(如转置和互换输入位置)后对两个输入做乘法
根据以上计算图,反向传播目标是求: 和
和 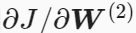
这里应用链式法则依次计算各中间变量和参数的梯度,其计算次序与前向传播中相应中间变量的计算次序恰恰相反
目标函数 关于损失L和正则化项s的梯度为:
关于损失L和正则化项s的梯度为:
J 关于输出层变量o 的梯度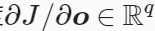 为:
为:
(J 和L 为标量,o 为长度为q的向量,所有求导后变成q维向量,详见矩阵求导)
正则化项s 关于两个权重参数的梯度:
先计算靠近输出层的参数W(2) 的梯度: :
:
沿输出层向隐藏层继续反向传播,隐藏层变量h的梯度: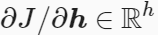 为:
为:
于激活函数ϕ是按元素运算的,中间变量z的梯度 的计算需要使用按元素乘法符⊙:
的计算需要使用按元素乘法符⊙:
最终得到最靠近输入层的模型参数W(1)的梯度: 为:
为:
在训练深度学习模型时,正向传播和反向传播之间相互依赖
正向传播的计算可能依赖于模型参数的当前值,而这些模型参数是在反向传播的梯度计算后通过优化算法迭代的,如计算正则化项s,依赖模型参数W(1)和W(2)的当前值,而这些当前值是优化算法最近一次根据反向传播算出梯度后迭代得到的
反向传播的梯度计算可能依赖于各变量的当前值,而这些变量的当前值是通过正向传播计算得到的,如∂J/∂W(2)计算需要依赖隐藏层变量的当前值hh。这个当前值是通过从输入层到输出层的正向传播计算并存储得到的
在反向传播中使用了正向传播中计算得到的中间变量来避免重复计算,这导致正向传播结束后不能立即释放中间变量内存。这也是训练要比预测占用更多内存的一个重要原因
中间变量的个数大体上与网络层数线性相关,每个变量的大小与批量大小和输入个数也是线性相关的,它们是导致较深的神经网络使用较大批量训练时更容易超内存的主要原因
相关问题推荐
换行。比如,print hello\nworld效果就是helloworld\n就是一个换行符。\是转义的意思,'\n'是换行,'\t'是tab,'\\'是,\ 是在编写程序中句子太长百,人为换行后加上\但print出来是一整行。...
十种常见排序算法一般分为以下几种:(1)非线性时间比较类排序:a. 交换类排序(快速排序、冒泡排序)b. 插入类排序(简单插入排序、希尔排序)c. 选择类排序(简单选择排序、堆排序)d. 归并排序(二路归并排序、多路归并排序)(2)线性时间非比较类排序:...
前景很好,中国正在产业升级,工业机器人和人工智能方面都会是强烈的热点,而且正好是在3~5年以后的时间。难度,肯定高,要求你有创新的思维能力,高数中的微积分、数列等等必须得非常好,软件编程(基础的应用最广泛的语言:C/C++)必须得很好,微电子(数字电...
迭代器与生成器的区别:(1)生成器:生成器本质上就是一个函数,它记住了上一次返回时在函数体中的位置。对生成器函数的第二次(或第n次)调用,跳转到函数上一次挂起的位置。而且记录了程序执行的上下文。生成器不仅记住了它的数据状态,生成器还记住了程序...
python中title( )属于python中字符串函数,返回’标题化‘的字符串,就是单词的开头为大写,其余为小写
第一种解释:代码中的cnt是count的简称,一种电脑计算机内部的数学函数的名字,在Excel办公软件中计算参数列表中的数字项的个数;在数据库( sq| server或者access )中可以用来统计符合条件的数据条数。函数COUNT在计数时,将把数值型的数字计算进去;但是...
head是方法,所以需要取小括号,即dataset.head()显示的则是前5行。data[:, :-1]和data[:, -1]。另外,如果想通过位置取数据,请使用iloc,即dataset.iloc[:, :-1]和dataset.iloc[:, -1],前者表示的是取所有行,但不包括最后一列的数据,结果是个DataFrame。...
挺简单的,其实课程内容没有我们想象的那么难、像我之前同学,完全零基础,培训了半年,直接出来就工作了,人家还在北京大公司上班,一个月15k,实力老厉害了
Python针对众多的类型,提供了众多的内建函数来处理(内建是相对于导入import来说的,后面学习到包package时,将会介绍),这些内建函数功用在于其往往可对多种类型对象进行类似的操作,即多种类型对象的共有的操作;如果某种操作只对特殊的某一类对象可行,Pyt...
相当于 ... 这里不是注释
还有FIXME
python的两个库:xlrd和xlutils。 xlrd打开excel,但是打开的excel并不能直接写入数据,需要用xlutils主要是复制一份出来,实现后续的写入功能。
单行注释:Python中的单行注释一般是以#开头的,#右边的文字都会被当做解释说明的内容,不会被当做执行的程序。为了保证代码的可读性,一般会在#后面加一两个空格然后在编写解释内容。示例:# 单行注释print(hello world)注释可以放在代码上面也可以放在代...
主要是按行读取,然后就是写出判断逻辑来勘测行是否为注视行,空行,编码行其他的:import linecachefile=open('3_2.txt','r')linecount=len(file.readlines())linecache.getline('3_2.txt',linecount)这样做的过程中发现一个问题,...
或许是里面有没被注释的代码
自学的话要看个人情况,可以先在B站找一下视频看一下