2020-08-21 19:30发布
大数据HIVE优化有哪些方案?
一、整体架构优化现在hive的整体框架如下,计算引擎不仅仅支持Map/Reduce,并且还支持Tez、Spark等。根据不同的计算引擎又可以使用不同的资源调度和存储系统。 整体架构优化点:1、根据不同业务需求进行日期分区,并执行类型动态分区。相关参数设置:0.14中默认hive.exec.dynamic.partition=ture2、为了减少磁盘存储空间以及I/O次数,对数据进行压缩相关参数设置:job输出文件按照BLOCK以Gzip方式进行压缩。
[AppleScript] 纯文本查看 复制代码
?
mapreduce.output.fileoutputformat.compress
=
true
mapreduce.output.fileoutputformat.compress.type
BLOCK
mapreduce.output.fileoutputformat.compress.codec
org.apache.hadoop.io.compress.GzipCodec
map输出结果也以Gzip进行压缩。
mapreduce.map.output.compress
mapreduce.map.output.compress.codec
对hive输出结果和中间结果进行压缩。
hive.exec.compress.output
hive.exec.compress.intermediate
3、hive中间表以SequenceFile保存,可以节约序列化和反序列化的时间相关参数设置:hive.query.result.fileformat=SequenceFile4、yarn优化,在此不再展开,后面专门介绍。二、MR阶段优化hive操作符有: 执行流程为: reduce切割算法:相关参数设置,默认为:hive.exec.reducers.max=999hive.exec.reducers.bytes.per.reducer=1G reduce task num=min{reducers.max,input.size/bytes.per.reducer},可以根据实际需求来调整reduce的个数。三、JOB优化1、本地执行默认关闭了本地执行模式,小数据可以使用本地执行模式,加快执行速度。相关参数设置:hive.exec.mode.local.auto=true 默认本地执行的条件是,hive.exec.mode.local.auto.inputbytes.max=128MB, hive.exec.mode.local.auto.tasks.max=4,reduce task最多1个。 性能测试:数据量(万) 操作 正常执行时间(秒) 本地执行时间(秒)170 group by 36 1680 count 34 62、mapjoin默认mapjoin是打开的, hive.auto.convert.join.noconditionaltask.size=10MB装载到内存的表必须是通过scan的表(不包括group by等操作),如果join的两个表都满足上面的条件,/*mapjoin*/指定表格不起作用,只会装载小表到内存,否则就会选那个满足条件的scan表。四、SQL优化整体的优化策略如下:
去除查询中不需要的column
Where条件判断等在TableScan阶段就进行过滤
利用Partition信息,只读取符合条件的Partition
Map端join,以大表作驱动,小表载入所有mapper内存中
调整Join顺序,确保以大表作为驱动表
对于数据分布不均衡的表Group by时,为避免数据集中到少数的reducer上,分成两个map-reduce阶段。第一个阶段先用Distinct列进行shuffle,然后在reduce端部分聚合,减小数据规模,第二个map-reduce阶段再按group-by列聚合。
在map端用hash进行部分聚合,减小reduce端数据处理规模。
五、平台优化1、hive on tez 2、spark SQL大趋势
创建test文件夹hadoop fs -mkdir /test
Hadoop的三大核心组件分别是:1、HDFS(Hadoop Distribute File System):hadoop的数据存储工具。2、YARN(Yet Another Resource Negotiator,另一种资源协调者):Hadoop 的资源管理器。3、Hadoop MapReduce:分布式计算框架。HDFS是一个高度容错性的系统,适合部...
hbase依靠HDFS来存储底层数据。Hadoop分布式文件系统(HDFS)为HBase提供了高可靠性的底层存储支持,HBase中的所有数据文件都存储在Hadoop HDFS文件系统上。
HBase分布式数据库具有如下的显著特点:容量大:HBase分布式数据库中的表可以存储成千上万的行和列组成的数据。面向列:HBase是面向列的存储和权限控制,并支持独立检索。列存储,其数据在表中是按照某列存储的,根据数据动态的增加列,并且可以单独对列进行...
解决问题的层面不一样首先,Hadoop和Apache Spark两者都是大数据框架,但是各自存在的目的不尽相同。Hadoop实质上更多是一个分布式数据基础设施: 它将巨大的数据集分派到一个由普通计算机组成的集群中的多个节点进行存储,意味着您不需要购买和维护昂贵的服务...
1、HBase写快读慢,HBase的读取时长通常是几毫秒,而Redis的读取时长通常是几十微秒。性能相差非常大。2、HBase和Redis都支持KV类型。但是Redis支持List、Set等更丰富的类型。3、Redis支持的数据量通常受内存限制,而HBase没有这个限制,可以存储远超内存大小...
列式存储格式是指以列为单位存储数据的数据存储格式,相比于传统的行式存储格式,它具有压缩比高、读I/O少(此处指可避免无意义的读I/O)等优点,目前被广泛应用于各种存储引擎中。对于HBase而言,它并不是一个列式存储引擎,而是列簇式存储引擎,即同一列簇中...
一、简单理解Hadoop是一个大象:一个hadoop集群主要包含三个主要的模块:Mapreduce,hdfs,yarn。mapreduce是一个分离在合并的计算框架,注意他不是一个集群,而是一个编程框架。hdfs是一个分布式文件系统,是一个分布式集群,用于存放数据。yarn集群是负责集群...
01 网络公开数据集02 数据报采集03 网络爬虫04 日志收集05 社会调查06 业务数据集07 埋点采集08 传感器采集09 数据交易平台10 个人数据收集
1 Hadoop 各个目录的解释bin:Hadoop管理脚本和使用脚本所在目录, sbin目录下的脚本都是使用此目录下的脚本实现的。etc:Hadoop的所有配置文件所在的目录,所有hadoop的配置在etc/hadoop目录下include:对外提供的库的头文件lib :对外提供的动态编程库和静态...
HDFS存储机制,包括HDFS的写入过程和读取过程两个部分: 1、写入过程: 1)客户端向namenode请求上传文件,namenode检查目标文件是否已存在,父目录是否存在。2)namenode返回是否可以上传。3)客户端请求第一个 block上传到哪几个datanode服务器上。4)nam...
adoop核心:MapReduce原理。 MR的核心是shuffle,被称为奇迹发生的地方。 shuffle,弄乱,洗牌的意思。partition 分区,sort 排序,spill溢出,disk 磁盘下面是官方对shuffle的配图: phase 阶段,fetch 最终,merge 合并...
Shuffle阶段分为两部分:Map端和Reduce端。一 map端shuffle过程;1-内存预排序:默认每个map有100M内存进行预排序(为了效率),超过阈值,会把内容写到磁盘; 此过程使用快速排序算法;2-根据key和reducer的数量进行分区和排序;首先根据数据所属的Parti...
大数据时代需要1存储大量数据2快速的处理大量数据3从大量数据中进行分析
hadoop的四种模式。1、本地模式:本地模式就是解压源码包,不需要做任何的配置。通常用于开发调试,或者感受hadoop。2、伪分布模式:在学习当中一般都是使用这种模式,伪分布模式就是在一台机器的多个进程运行多个模块。虽然每一个模块都有相应的进程,但是却...
进入和退出安全模式 [root@localhost bin]# ./hdfs dfsadmin -safemode enter15/08/03 07:26:24 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where ......
最多设置5个标签!
{var%20f='http://v.t.sina.com.cn/share/share.php?appkey=1515056452',u=z||d.location,p=['&url=',e(u),'&title=',e(t||d.title),'&source=',e(r),'&sourceUrl=',e(l),'&content=',c||'gb2312','&pic=',e(p||'')].join('');function%20a(){if(!window.open([f,p].join(''),'mb',['toolbar=0,status=0,resizable=1,width=440,height=430,left=',(s.width-440)/2,',top=',(s.height-430)/2].join('')))u.href=[f,p].join('');};if(/Firefox/.test(navigator.userAgent))setTimeout(a,0);else%20a();})(screen,document,encodeURIComponent,'','','/static/images/logo.png', '推荐 steven 的问题《大数据HIVE优化有哪些方案?》','http://www.shouhuola.com/q-27865.html','页面编码gb2312|utf-8默认gb2312'));){kind=link}
一、整体架构优化
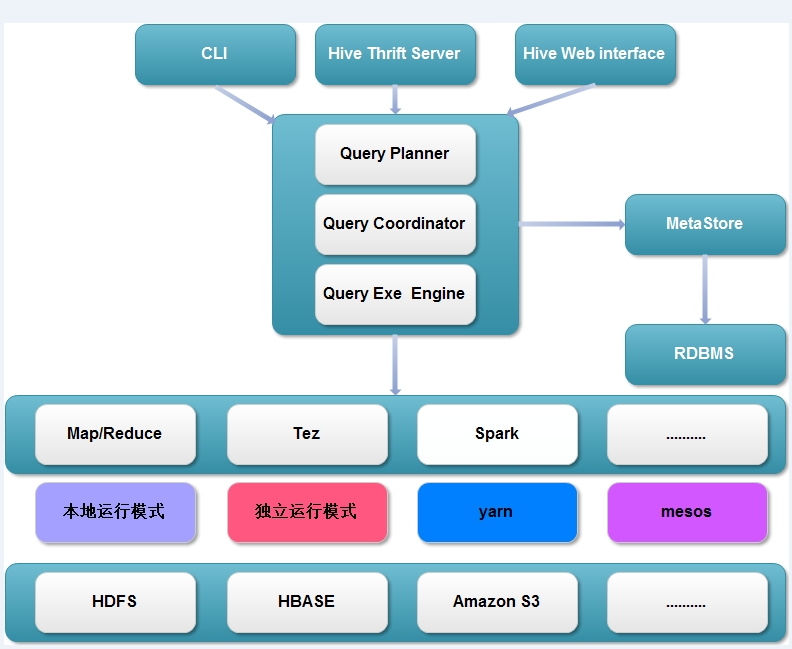
现在hive的整体框架如下,计算引擎不仅仅支持Map/Reduce,并且还支持Tez、Spark等。根据不同的计算引擎又可以使用不同的资源调度和存储系统。
整体架构优化点:
1、根据不同业务需求进行日期分区,并执行类型动态分区。
相关参数设置:
0.14中默认hive.exec.dynamic.partition=ture
2、为了减少磁盘存储空间以及I/O次数,对数据进行压缩
相关参数设置:
job输出文件按照BLOCK以Gzip方式进行压缩。
[AppleScript] 纯文本查看 复制代码
?
mapreduce.output.fileoutputformat.compress=truemapreduce.output.fileoutputformat.compress.type=BLOCKmapreduce.output.fileoutputformat.compress.codec=org.apache.hadoop.io.compress.GzipCodecmap输出结果也以Gzip进行压缩。
[AppleScript] 纯文本查看 复制代码
?
mapreduce.map.output.compress=truemapreduce.map.output.compress.codec=org.apache.hadoop.io.compress.GzipCodec对hive输出结果和中间结果进行压缩。
[AppleScript] 纯文本查看 复制代码
?
hive.exec.compress.output=truehive.exec.compress.intermediate=true3、hive中间表以SequenceFile保存,可以节约序列化和反序列化的时间
相关参数设置:
hive.query.result.fileformat=SequenceFile
4、yarn优化,在此不再展开,后面专门介绍。
二、MR阶段优化
hive操作符有:
执行流程为:
reduce切割算法:
相关参数设置,默认为:
hive.exec.reducers.max=999
hive.exec.reducers.bytes.per.reducer=1G
reduce task num=min{reducers.max,input.size/bytes.per.reducer},可以根据实际需求来调整reduce的个数。
三、JOB优化
1、本地执行
默认关闭了本地执行模式,小数据可以使用本地执行模式,加快执行速度。
相关参数设置:
hive.exec.mode.local.auto=true
默认本地执行的条件是,hive.exec.mode.local.auto.inputbytes.max=128MB, hive.exec.mode.local.auto.tasks.max=4,reduce task最多1个。 性能测试:
数据量(万) 操作 正常执行时间(秒) 本地执行时间(秒)
170 group by 36 16
80 count 34 6
2、mapjoin
默认mapjoin是打开的, hive.auto.convert.join.noconditionaltask.size=10MB
装载到内存的表必须是通过scan的表(不包括group by等操作),如果join的两个表都满足上面的条件,/*mapjoin*/指定表格不起作用,只会装载小表到内存,否则就会选那个满足条件的scan表。
四、SQL优化
整体的优化策略如下:
去除查询中不需要的column
Where条件判断等在TableScan阶段就进行过滤
利用Partition信息,只读取符合条件的Partition
Map端join,以大表作驱动,小表载入所有mapper内存中
调整Join顺序,确保以大表作为驱动表
对于数据分布不均衡的表Group by时,为避免数据集中到少数的reducer上,分成两个map-reduce阶段。第一个阶段先用Distinct列进行shuffle,然后在reduce端部分聚合,减小数据规模,第二个map-reduce阶段再按group-by列聚合。
在map端用hash进行部分聚合,减小reduce端数据处理规模。
五、平台优化
1、hive on tez
2、spark SQL大趋势
相关问题推荐
创建test文件夹hadoop fs -mkdir /test
Hadoop的三大核心组件分别是:1、HDFS(Hadoop Distribute File System):hadoop的数据存储工具。2、YARN(Yet Another Resource Negotiator,另一种资源协调者):Hadoop 的资源管理器。3、Hadoop MapReduce:分布式计算框架。HDFS是一个高度容错性的系统,适合部...
hbase依靠HDFS来存储底层数据。Hadoop分布式文件系统(HDFS)为HBase提供了高可靠性的底层存储支持,HBase中的所有数据文件都存储在Hadoop HDFS文件系统上。
HBase分布式数据库具有如下的显著特点:容量大:HBase分布式数据库中的表可以存储成千上万的行和列组成的数据。面向列:HBase是面向列的存储和权限控制,并支持独立检索。列存储,其数据在表中是按照某列存储的,根据数据动态的增加列,并且可以单独对列进行...
解决问题的层面不一样首先,Hadoop和Apache Spark两者都是大数据框架,但是各自存在的目的不尽相同。Hadoop实质上更多是一个分布式数据基础设施: 它将巨大的数据集分派到一个由普通计算机组成的集群中的多个节点进行存储,意味着您不需要购买和维护昂贵的服务...
1、HBase写快读慢,HBase的读取时长通常是几毫秒,而Redis的读取时长通常是几十微秒。性能相差非常大。2、HBase和Redis都支持KV类型。但是Redis支持List、Set等更丰富的类型。3、Redis支持的数据量通常受内存限制,而HBase没有这个限制,可以存储远超内存大小...
列式存储格式是指以列为单位存储数据的数据存储格式,相比于传统的行式存储格式,它具有压缩比高、读I/O少(此处指可避免无意义的读I/O)等优点,目前被广泛应用于各种存储引擎中。对于HBase而言,它并不是一个列式存储引擎,而是列簇式存储引擎,即同一列簇中...
一、简单理解Hadoop是一个大象:一个hadoop集群主要包含三个主要的模块:Mapreduce,hdfs,yarn。mapreduce是一个分离在合并的计算框架,注意他不是一个集群,而是一个编程框架。hdfs是一个分布式文件系统,是一个分布式集群,用于存放数据。yarn集群是负责集群...
01 网络公开数据集02 数据报采集03 网络爬虫04 日志收集05 社会调查06 业务数据集07 埋点采集08 传感器采集09 数据交易平台10 个人数据收集
1 Hadoop 各个目录的解释bin:Hadoop管理脚本和使用脚本所在目录, sbin目录下的脚本都是使用此目录下的脚本实现的。etc:Hadoop的所有配置文件所在的目录,所有hadoop的配置在etc/hadoop目录下include:对外提供的库的头文件lib :对外提供的动态编程库和静态...
HDFS存储机制,包括HDFS的写入过程和读取过程两个部分: 1、写入过程: 1)客户端向namenode请求上传文件,namenode检查目标文件是否已存在,父目录是否存在。2)namenode返回是否可以上传。3)客户端请求第一个 block上传到哪几个datanode服务器上。4)nam...
adoop核心:MapReduce原理。 MR的核心是shuffle,被称为奇迹发生的地方。 shuffle,弄乱,洗牌的意思。partition 分区,sort 排序,spill溢出,disk 磁盘下面是官方对shuffle的配图: phase 阶段,fetch 最终,merge 合并...
Shuffle阶段分为两部分:Map端和Reduce端。一 map端shuffle过程;1-内存预排序:默认每个map有100M内存进行预排序(为了效率),超过阈值,会把内容写到磁盘; 此过程使用快速排序算法;2-根据key和reducer的数量进行分区和排序;首先根据数据所属的Parti...
大数据时代需要1存储大量数据2快速的处理大量数据3从大量数据中进行分析
hadoop的四种模式。1、本地模式:本地模式就是解压源码包,不需要做任何的配置。通常用于开发调试,或者感受hadoop。2、伪分布模式:在学习当中一般都是使用这种模式,伪分布模式就是在一台机器的多个进程运行多个模块。虽然每一个模块都有相应的进程,但是却...
进入和退出安全模式 [root@localhost bin]# ./hdfs dfsadmin -safemode enter15/08/03 07:26:24 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where ......