2020-08-26 18:15发布
serilazable级别较重,对象被序列化后,会附带很多额外的信息(各种校验信息,header,继承体系等),不便于在网络中高效传输,hadoop自己的序列化机制whitable格式化后数据比较紧凑,利于传输
序列化概述
序列化定义
序列化的应用
Hadoop序列化
Hadoop序列化的特点
Hadoop对应Java序列化类
Hadoop 自定义对象序列化
序列化就是把内存中的对象转换成字节序列 (或者其他数据传输协议) 以便于储存到磁盘 (持久化) 和网络传输。
反序列化就是将接收到的字节序列 (或其他数据传输协议) 或者是磁盘持久化数据,转换成为内存中的对象。
对象只存在于内存中,关机断电就没有了,而且激活的对象只能由本地的进程使用,不能被发送到网络上的另一台计算机上。序列化是程序数据存储的一种形式。储存的数据可以被再次提取以及发送到另一台设备上。
Java的序列化是一个重量级的序列化框架 (Serializable),一个对象被序列化后,会附带很多额外的信息(各种校验信息,Header,继承体系等),不便于在网络中高效的传输。所以,Hadoop自己开发了一套序列化机制(Writable)。
紧凑: 高效使用储存空间。
快速:读写数据的额外开销小。
可扩展:随着通信协议的升级而可以升级。
互操作:支持多种语言交互。
Java中的常用类型,在Hadoop中都有对应的序列化实现类。其对应关系如下图所示:
在企业开发中往往常用的基本序列化类型不能满足所有需求,比如在Hadoop框架内部传递一个bean对象,那么该对象就需要实现序列化接口。具体实现bean对象序列化步骤如下7步。
必须实现Writable接口
反序列化时,需要反射调用空参构造函数,所以必须有空参构造
public Bean() { super();}123
重写序列化方法
@Overridepublic void write(DataOutput out) throws IOException { out.writeLong(attr1); out.writeLong(attr2); out.writeLong(attr3);}123456
重写反序列化方法
@Overridepublic void readFields(DataInput in) throws IOException { attr1 = in.readLong(); attr2 = in.readLong(); attr3 = in.readLong();}123456
注意反序列化的顺序和序列化的顺序完全一致
如果需要将自定义的bean放在key中传输,则还需要实现Comparable接口,因为MapReduce框中的Shuffle过程要求对key必须能排序。
java序列化很全面, 包含所有类的信息, 但是这样的代价就是导致序列化后的对象占用很大的空间, 而hadoop这样的大数据的运算会将这种代价放大, 所以会采用一些比较简单模式对对象的内容进行描述,
比如 avro这样的序列化工具, 只包含对象中的信息就可以了。
简单说一下:1 java的序列化机制在每个类的对象第一次出现的时候保存了每个类的信息, 比如类名, 第二次出现的类对象会有一个类的reference, 导致空间的浪费2 有成千上万(打个比方,不止这么多)的对象要反序列化, 而java序列化机制不能复用对象, java反序列化的时候, 每次要构造出新的对象. 在hadoop的序列化机制中, 反序列化的对象是可以复用的.3 自我实现把控力更好
创建test文件夹hadoop fs -mkdir /test
Hadoop的三大核心组件分别是:1、HDFS(Hadoop Distribute File System):hadoop的数据存储工具。2、YARN(Yet Another Resource Negotiator,另一种资源协调者):Hadoop 的资源管理器。3、Hadoop MapReduce:分布式计算框架。HDFS是一个高度容错性的系统,适合部...
hbase依靠HDFS来存储底层数据。Hadoop分布式文件系统(HDFS)为HBase提供了高可靠性的底层存储支持,HBase中的所有数据文件都存储在Hadoop HDFS文件系统上。
HBase分布式数据库具有如下的显著特点:容量大:HBase分布式数据库中的表可以存储成千上万的行和列组成的数据。面向列:HBase是面向列的存储和权限控制,并支持独立检索。列存储,其数据在表中是按照某列存储的,根据数据动态的增加列,并且可以单独对列进行...
解决问题的层面不一样首先,Hadoop和Apache Spark两者都是大数据框架,但是各自存在的目的不尽相同。Hadoop实质上更多是一个分布式数据基础设施: 它将巨大的数据集分派到一个由普通计算机组成的集群中的多个节点进行存储,意味着您不需要购买和维护昂贵的服务...
1、HBase写快读慢,HBase的读取时长通常是几毫秒,而Redis的读取时长通常是几十微秒。性能相差非常大。2、HBase和Redis都支持KV类型。但是Redis支持List、Set等更丰富的类型。3、Redis支持的数据量通常受内存限制,而HBase没有这个限制,可以存储远超内存大小...
列式存储格式是指以列为单位存储数据的数据存储格式,相比于传统的行式存储格式,它具有压缩比高、读I/O少(此处指可避免无意义的读I/O)等优点,目前被广泛应用于各种存储引擎中。对于HBase而言,它并不是一个列式存储引擎,而是列簇式存储引擎,即同一列簇中...
一、简单理解Hadoop是一个大象:一个hadoop集群主要包含三个主要的模块:Mapreduce,hdfs,yarn。mapreduce是一个分离在合并的计算框架,注意他不是一个集群,而是一个编程框架。hdfs是一个分布式文件系统,是一个分布式集群,用于存放数据。yarn集群是负责集群...
01 网络公开数据集02 数据报采集03 网络爬虫04 日志收集05 社会调查06 业务数据集07 埋点采集08 传感器采集09 数据交易平台10 个人数据收集
1 Hadoop 各个目录的解释bin:Hadoop管理脚本和使用脚本所在目录, sbin目录下的脚本都是使用此目录下的脚本实现的。etc:Hadoop的所有配置文件所在的目录,所有hadoop的配置在etc/hadoop目录下include:对外提供的库的头文件lib :对外提供的动态编程库和静态...
HDFS存储机制,包括HDFS的写入过程和读取过程两个部分: 1、写入过程: 1)客户端向namenode请求上传文件,namenode检查目标文件是否已存在,父目录是否存在。2)namenode返回是否可以上传。3)客户端请求第一个 block上传到哪几个datanode服务器上。4)nam...
adoop核心:MapReduce原理。 MR的核心是shuffle,被称为奇迹发生的地方。 shuffle,弄乱,洗牌的意思。partition 分区,sort 排序,spill溢出,disk 磁盘下面是官方对shuffle的配图: phase 阶段,fetch 最终,merge 合并...
Shuffle阶段分为两部分:Map端和Reduce端。一 map端shuffle过程;1-内存预排序:默认每个map有100M内存进行预排序(为了效率),超过阈值,会把内容写到磁盘; 此过程使用快速排序算法;2-根据key和reducer的数量进行分区和排序;首先根据数据所属的Parti...
大数据时代需要1存储大量数据2快速的处理大量数据3从大量数据中进行分析
hadoop的四种模式。1、本地模式:本地模式就是解压源码包,不需要做任何的配置。通常用于开发调试,或者感受hadoop。2、伪分布模式:在学习当中一般都是使用这种模式,伪分布模式就是在一台机器的多个进程运行多个模块。虽然每一个模块都有相应的进程,但是却...
进入和退出安全模式 [root@localhost bin]# ./hdfs dfsadmin -safemode enter15/08/03 07:26:24 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where ......
最多设置5个标签!
{var%20f='http://v.t.sina.com.cn/share/share.php?appkey=1515056452',u=z||d.location,p=['&url=',e(u),'&title=',e(t||d.title),'&source=',e(r),'&sourceUrl=',e(l),'&content=',c||'gb2312','&pic=',e(p||'')].join('');function%20a(){if(!window.open([f,p].join(''),'mb',['toolbar=0,status=0,resizable=1,width=440,height=430,left=',(s.width-440)/2,',top=',(s.height-430)/2].join('')))u.href=[f,p].join('');};if(/Firefox/.test(navigator.userAgent))setTimeout(a,0);else%20a();})(screen,document,encodeURIComponent,'','','/static/images/logo.png', '推荐 宝藏秦公子 的问题《hadoop为什么不用Java的序列化 serilazable》','http://www.shouhuola.com/q-28172.html','页面编码gb2312|utf-8默认gb2312'));){kind=link}
serilazable级别较重,对象被序列化后,会附带很多额外的信息(各种校验信息,header,继承体系等),不便于在网络中高效传输,hadoop自己的序列化机制whitable格式化后数据比较紧凑,利于传输
文章目录
序列化概述
序列化定义
序列化的应用
Hadoop序列化
Hadoop序列化的特点
Hadoop对应Java序列化类
Hadoop 自定义对象序列化
序列化就是把内存中的对象转换成字节序列 (或者其他数据传输协议) 以便于储存到磁盘 (持久化) 和网络传输。
反序列化就是将接收到的字节序列 (或其他数据传输协议) 或者是磁盘持久化数据,转换成为内存中的对象。
对象只存在于内存中,关机断电就没有了,而且激活的对象只能由本地的进程使用,不能被发送到网络上的另一台计算机上。序列化是程序数据存储的一种形式。储存的数据可以被再次提取以及发送到另一台设备上。
Java的序列化是一个重量级的序列化框架 (Serializable),一个对象被序列化后,会附带很多额外的信息(各种校验信息,Header,继承体系等),不便于在网络中高效的传输。所以,Hadoop自己开发了一套序列化机制(Writable)。
紧凑: 高效使用储存空间。
快速:读写数据的额外开销小。
可扩展:随着通信协议的升级而可以升级。
互操作:支持多种语言交互。
Java中的常用类型,在Hadoop中都有对应的序列化实现类。其对应关系如下图所示:
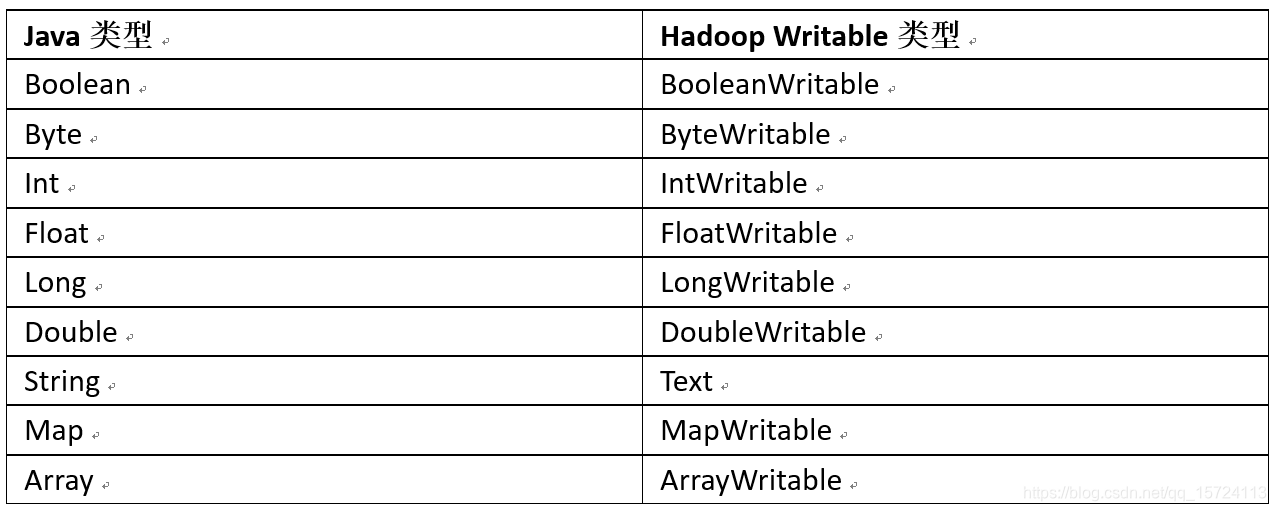
在企业开发中往往常用的基本序列化类型不能满足所有需求,比如在Hadoop框架内部传递一个bean对象,那么该对象就需要实现序列化接口。
具体实现bean对象序列化步骤如下7步。
必须实现Writable接口
反序列化时,需要反射调用空参构造函数,所以必须有空参构造
public Bean() { super();}123重写序列化方法
@Overridepublic void write(DataOutput out) throws IOException { out.writeLong(attr1); out.writeLong(attr2); out.writeLong(attr3);}123456重写反序列化方法
@Overridepublic void readFields(DataInput in) throws IOException { attr1 = in.readLong(); attr2 = in.readLong(); attr3 = in.readLong();}123456注意反序列化的顺序和序列化的顺序完全一致
如果需要将自定义的bean放在key中传输,则还需要实现Comparable接口,因为MapReduce框中的Shuffle过程要求对key必须能排序。
java序列化很全面, 包含所有类的信息, 但是这样的代价就是导致序列化后的对象占用很大的空间, 而hadoop这样的大数据的运算会将这种代价放大, 所以会采用一些比较简单模式对对象的内容进行描述,
比如 avro这样的序列化工具, 只包含对象中的信息就可以了。
简单说一下:
1 java的序列化机制在每个类的对象第一次出现的时候保存了每个类的信息, 比如类名, 第二次出现的类对象会有一个类的reference, 导致空间的浪费
2 有成千上万(打个比方,不止这么多)的对象要反序列化, 而java序列化机制不能复用对象, java反序列化的时候, 每次要构造出新的对象. 在hadoop的序列化机制中, 反序列化的对象是可以复用的.
3 自我实现把控力更好
相关问题推荐
创建test文件夹hadoop fs -mkdir /test
Hadoop的三大核心组件分别是:1、HDFS(Hadoop Distribute File System):hadoop的数据存储工具。2、YARN(Yet Another Resource Negotiator,另一种资源协调者):Hadoop 的资源管理器。3、Hadoop MapReduce:分布式计算框架。HDFS是一个高度容错性的系统,适合部...
hbase依靠HDFS来存储底层数据。Hadoop分布式文件系统(HDFS)为HBase提供了高可靠性的底层存储支持,HBase中的所有数据文件都存储在Hadoop HDFS文件系统上。
HBase分布式数据库具有如下的显著特点:容量大:HBase分布式数据库中的表可以存储成千上万的行和列组成的数据。面向列:HBase是面向列的存储和权限控制,并支持独立检索。列存储,其数据在表中是按照某列存储的,根据数据动态的增加列,并且可以单独对列进行...
解决问题的层面不一样首先,Hadoop和Apache Spark两者都是大数据框架,但是各自存在的目的不尽相同。Hadoop实质上更多是一个分布式数据基础设施: 它将巨大的数据集分派到一个由普通计算机组成的集群中的多个节点进行存储,意味着您不需要购买和维护昂贵的服务...
1、HBase写快读慢,HBase的读取时长通常是几毫秒,而Redis的读取时长通常是几十微秒。性能相差非常大。2、HBase和Redis都支持KV类型。但是Redis支持List、Set等更丰富的类型。3、Redis支持的数据量通常受内存限制,而HBase没有这个限制,可以存储远超内存大小...
列式存储格式是指以列为单位存储数据的数据存储格式,相比于传统的行式存储格式,它具有压缩比高、读I/O少(此处指可避免无意义的读I/O)等优点,目前被广泛应用于各种存储引擎中。对于HBase而言,它并不是一个列式存储引擎,而是列簇式存储引擎,即同一列簇中...
一、简单理解Hadoop是一个大象:一个hadoop集群主要包含三个主要的模块:Mapreduce,hdfs,yarn。mapreduce是一个分离在合并的计算框架,注意他不是一个集群,而是一个编程框架。hdfs是一个分布式文件系统,是一个分布式集群,用于存放数据。yarn集群是负责集群...
01 网络公开数据集02 数据报采集03 网络爬虫04 日志收集05 社会调查06 业务数据集07 埋点采集08 传感器采集09 数据交易平台10 个人数据收集
1 Hadoop 各个目录的解释bin:Hadoop管理脚本和使用脚本所在目录, sbin目录下的脚本都是使用此目录下的脚本实现的。etc:Hadoop的所有配置文件所在的目录,所有hadoop的配置在etc/hadoop目录下include:对外提供的库的头文件lib :对外提供的动态编程库和静态...
HDFS存储机制,包括HDFS的写入过程和读取过程两个部分: 1、写入过程: 1)客户端向namenode请求上传文件,namenode检查目标文件是否已存在,父目录是否存在。2)namenode返回是否可以上传。3)客户端请求第一个 block上传到哪几个datanode服务器上。4)nam...
adoop核心:MapReduce原理。 MR的核心是shuffle,被称为奇迹发生的地方。 shuffle,弄乱,洗牌的意思。partition 分区,sort 排序,spill溢出,disk 磁盘下面是官方对shuffle的配图: phase 阶段,fetch 最终,merge 合并...
Shuffle阶段分为两部分:Map端和Reduce端。一 map端shuffle过程;1-内存预排序:默认每个map有100M内存进行预排序(为了效率),超过阈值,会把内容写到磁盘; 此过程使用快速排序算法;2-根据key和reducer的数量进行分区和排序;首先根据数据所属的Parti...
大数据时代需要1存储大量数据2快速的处理大量数据3从大量数据中进行分析
hadoop的四种模式。1、本地模式:本地模式就是解压源码包,不需要做任何的配置。通常用于开发调试,或者感受hadoop。2、伪分布模式:在学习当中一般都是使用这种模式,伪分布模式就是在一台机器的多个进程运行多个模块。虽然每一个模块都有相应的进程,但是却...
进入和退出安全模式 [root@localhost bin]# ./hdfs dfsadmin -safemode enter15/08/03 07:26:24 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where ......