现在,我们将获得用户输入,因为我们需要在表中存储标题,描述和日期。因此,我们将从用户那里获得这些值。 title = input("Enter title of your task: ") desc = input("Add some description to it: ") date = input("Enter the date for this task (YYYY-MM-DD): ")
因此,我们具有值以及与MySQL数据库的连接。要插入值,我们这样做。 try: with connection.cursor() as cursor: sql = “INSERT INTO todos (title, desc, date) VALUES (%s, %s, %s)” try: cursor.execute(sql, (title, desc, date)) print(“Task added successfully”) except: print(“Oops! Something wrong”)
try: with connection.cursor() as cursor: sql = “SELECT id, title, desc FROM todos WHERE date = CURDATE()” try: cursor.execute(sql) result = cursor.fetchall()
print("Id\t\t Title\t\t\t\t\tDescription") print("---------------------------------------------------------------------------") for row in result: print(str(row[0]) + "\t\t" + row[1] + "\t\t\t" + row[2])
try: with connection.cursor() as cursor: sql = “UPDATE todos SET title=%s, desc=%s WHERE id = %s” try: cursor.execute(sql, (‘your new title’, ‘your new description’, 1)) print(“Successfully Updated…”) except: print(“Oops! Something wrong”)
connection.commit()1
finally: connection.close()
删除操作 最后,您可以将记录删除为。
try: with connection.cursor() as cursor: sql = “DELETE FROM todos WHERE id = %s” try: cursor.execute(sql, (1,)) print(“Successfully Deleted…”) except: print(“Oops! Something wrong”)
{var%20f='http://v.t.sina.com.cn/share/share.php?appkey=1515056452',u=z||d.location,p=['&url=',e(u),'&title=',e(t||d.title),'&source=',e(r),'&sourceUrl=',e(l),'&content=',c||'gb2312','&pic=',e(p||'')].join('');function%20a(){if(!window.open([f,p].join(''),'mb',['toolbar=0,status=0,resizable=1,width=440,height=430,left=',(s.width-440)/2,',top=',(s.height-430)/2].join('')))u.href=[f,p].join('');};if(/Firefox/.test(navigator.userAgent))setTimeout(a,0);else%20a();})(screen,document,encodeURIComponent,'','','/static/images/logo.png', '推荐 小小李兆佳 的问题《MySQL数据库和Python怎么结合?》','http://www.shouhuola.com/q-30281.html','页面编码gb2312|utf-8默认gb2312'));){kind=link}
什么是PyMySQL
您可能已经知道要使用任何数据库,我们需要数据库驱动程序。PyMySQL是用于在Python中运行MySQL的纯Python驱动程序。
现在,请记住,默认情况下此PyMySQL不可用。因此,首先,我们将学习如何下载和安装此驱动程序。
安装PyMySQL
在这里,我假设您的计算机上已经安装了python。而且,您已经完成了设置环境变量的工作。如果没有,那么您应该先转到此链接。
要安装PyMySQL,请运行以下命令(对于Linux的MAC使用终端,我正在使用Windows,因此我正在使用cmd)。
pip install pymysql
确保您已连接互联网,并且在运行上述命令时会看到以下输出。
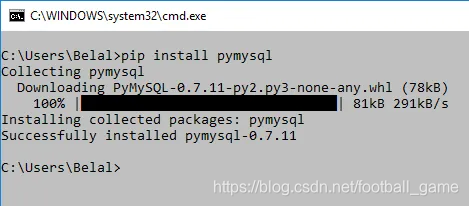
现在,一旦我们安装了PyMySQL,就可以从Python学习操作MySQL数据库。在此Python MySQL教程中,我将向您介绍使用Python在MySQL数据库中进行的基本CRUD操作。
注意:CRUD表示数据库中的创建,读取,更新和删除操作。
在MySQL中创建数据库
在开始任何操作之前,我们需要一个数据库,对吗?因此,打开您的MySQL数据库,对于MySQL,我在这里使用XAMPP,并且可以使用localhost / phpmyadmin访问它。
尽管您也可以使用任何其他软件,但过程将相同。
转到localhost / phpmyadmin 并创建一个数据库。我创建了一个名为belal的数据库,如下图所示。
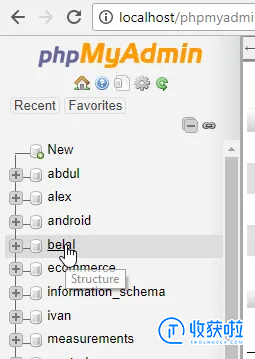
现在,在数据库内部,我们将创建表。因此,转到SQL并运行以下SQL查询来创建表。
CREATE TABLE todos(
idINTEGER PRIMARY KEY AUTO_INCREMENT,titleVARCHAR(100),descVARCHAR(500),dateDATE)
上面的查询将创建下表。
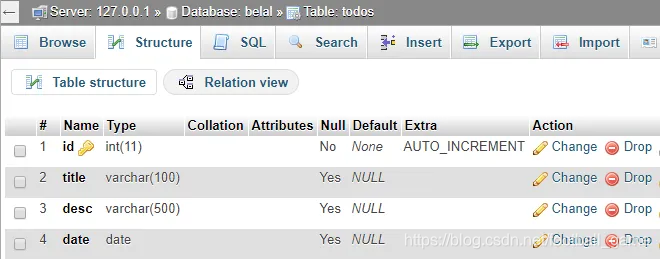
Python MySQL教程:执行基本CRUD
在这里,我正在使用PyCharm IDE。(我爱上了JetBrains IDEs????)。
现在,让我们从PyCharm中的新Python项目开始。
创建操作
在您的项目中创建一个名为CreatTask.py的新Python文件。第一步是导入pymysql。
import pymysql
然后我们将连接到数据库。
connection = pymysql.connect(
host=‘localhost’,
user=‘root’,
password=‘password’,
db=‘belal’,
)
现在,我们将获得用户输入,因为我们需要在表中存储标题,描述和日期。因此,我们将从用户那里获得这些值。
title = input("Enter title of your task: ")
desc = input("Add some description to it: ")
date = input("Enter the date for this task (YYYY-MM-DD): ")
因此,我们具有值以及与MySQL数据库的连接。要插入值,我们这样做。
try:
with connection.cursor() as cursor:
sql = “INSERT INTO todos (
title,desc,date) VALUES (%s, %s, %s)”try:
cursor.execute(sql, (title, desc, date))
print(“Task added successfully”)
except:
print(“Oops! Something wrong”)
connection.commit()1
finally:
connection.close()
我们拥有AddTask.py的最终代码是。
import pymysql
connection = pymysql.connect(
host=‘localhost’,
user=‘root’,
password=‘password’,
db=‘belal’,
)
title = input("Enter title of your task: ")
desc = input("Add some description to it: ")
date = input("Enter the date for this task (YYYY-MM-DD): ")
try:
with connection.cursor() as cursor:
sql = “INSERT INTO todos (
title,desc,date) VALUES (%s, %s, %s)”try:
cursor.execute(sql, (title, desc, date))
print(“Task added successfully”)
except:
print(“Oops! Something wrong”)
connection.commit()1
finally:
connection.close()
您可以尝试执行此代码。
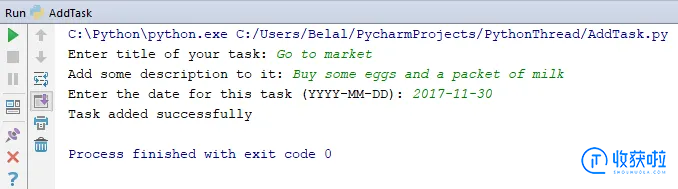
如果获得如上所示的输出,则应该在MySQL数据库中看到这些值。

读取操作
再次创建一个名为ReadTasks.py的新Python文件,并在其中编写以下代码。
import pymysql
connection = pymysql.connect(
host=‘localhost’,
user=‘root’,
password=‘password’,
db=‘belal’,
)
try:
with connection.cursor() as cursor:
sql = “SELECT
id,title,descFROM todos WHEREdate= CURDATE()”try:
cursor.execute(sql)
result = cursor.fetchall()
print("Id\t\t Title\t\t\t\t\tDescription")
print("---------------------------------------------------------------------------")
for row in result:
print(str(row[0]) + "\t\t" + row[1] + "\t\t\t" + row[2])
except:
print("Oops! Something wrong")
connection.commit()123456789
finally:
connection.close()
运行上述代码后,您将看到以下输出。
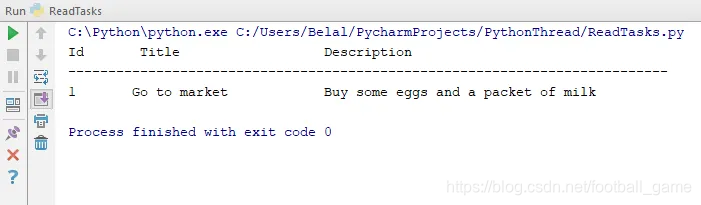
更新操作
我现在希望;您可以自己执行所有操作。但是,如果您有任何困惑,这里是用于更新MySQL数据库中的值的代码段。
try:
with connection.cursor() as cursor:
sql = “UPDATE todos SET
title=%s,desc=%s WHEREid= %s”try:
cursor.execute(sql, (‘your new title’, ‘your new description’, 1))
print(“Successfully Updated…”)
except:
print(“Oops! Something wrong”)
connection.commit()1
finally:
connection.close()
删除操作
最后,您可以将记录删除为。
try:
with connection.cursor() as cursor:
sql = “DELETE FROM todos WHERE id = %s”
try:
cursor.execute(sql, (1,))
print(“Successfully Deleted…”)
except:
print(“Oops! Something wrong”)
connection.commit()1
finally:
connection.close()
我们已经完成了MySQL中的所有CRUD操作。
这次给大家带来的是将python爬取的数据写入数据库将爬取得数据写入数据库的步骤:
连接数据库;创建表将数据写入数据库;关闭数据库。
连接数据库在连接自己的数据库之前我们应先导入importMySQLdb模块
host:自己的主机号,一般写127.0.0.1就可以了port:端口号user:rootpasswd:密码db:连接的数据库名称charset:编码
importMySQLdb
conn=MySQLdb.Connect(host='127.0.0.1',
port=3306,
user='root',
passwd='*******',
db='******',
charset='utf8')
2.创建表
cursor():使用该链接创建并返回的游标execute():执行一个数据库查询和命令commit():提交但前事物(写入数据时也会用到)
cur=conn.cursor()
sql="""CREATETABLExiaoshuo(
titleCHAR(20),
sec_titleCHAR(20),
contentVARCHAR(6499))"""
cur.execute(sql)
conn.commit()
3.写入数据库这里有两种方法写入:第一种:
into="INSERTINTOscrapy_yilong2(title,author,comment,`time`)VALUES(%s,%s,%s,%s)"
values=(item['title'],item['author'],item['comment'],item['time'])
cur.execute(into,values)
conn.commit()
第二种:
cur.execute("INSERTINTOscrapy_yilong2(title,author,comment,`time`)VALUES(%s,%s,%s,%s);%(item['title'],item['author'],item['comment'],item['time']))
conn.commit()
但是建议大家使用第一种,第一种比较规范还有就是,传入数据后记得提交,也就是commit()函数要记得写
4.关闭数据库
conn.close()
在这里,给大家一个完整的实例,以供大家体会,下面这个例子是爬取多本小说,并写入数据库如果大家想更加的了解这个代码,可以查看我的上一篇博客上一篇:爬取多本小说并写入多个txt文档
#-*-coding:utf-8-*-
frombs4importBeautifulSoup
importrequests
importre
importMySQLdb
#解决出现的写入错误
importsys
reload(sys)
sys.setdefaultencoding('utf-8')
#可以获取多本文章
MAX_RETRIES=20
url='http://eutils.ncbi.nlm.nih.gov/entrez/eutils/einfo.fcgi'
session=requests.Session()
adapter=requests.adapters.HTTPAdapter(max_retries=MAX_RETRIES)
session.mount('https://',adapter)
session.mount('http://',adapter)
r=session.get(url)
print('连接到mysql服务器...')
conn=MySQLdb.connect(host='127.0.0.1',user='root',passwd='123mysql',db='onefive',charset='utf8')
print('连接上了!')
cur=conn.cursor()
#判断表是否存在,若存在则删除此表
cur.execute("DROPTABLEIFEXISTSAGENT")
#创建表
sql="""CREATETABLExiaoshuo(
titleCHAR(20),
sec_titleCHAR(20),
contentVARCHAR(6499))"""
cur.execute(sql)
conn.commit()
#爬取首页各小说链接,并写入列表
url1='http://www.biquge.com.tw/'
html=requests.get(url1).content
soup=BeautifulSoup(html,'html.parser')
article=soup.find(id="main")
texts=[]
fornovelinarticle.find_all(href=re.compile('http://www.biquge.com.tw/')):
#小说链接
nt=novel.get('href')
texts.append(nt)
#printnt#可供检验
new_text=[]
fortextintexts:
iftextnotinnew_text:
new_text.append(text)
#将刚刚的列表写入一个新列表,以供遍历,获取各个链接
h=[]
h.append(new_text)
l=0
forninh:
whilel<=len(n)-1:
#爬取小说的相关信息及目录和目录链接
url2=n[l]
html=requests.get(url2).content
soup=BeautifulSoup(html,'html.parser')
a=[]
#爬取相关信息及目录
forcatalogueinsoup.find_all(id="list"):
timu=soup.find(id="maininfo")
name1=timu.find('h1').get_text()
tm=timu.get_text()
e_cat=catalogue.get_text('')
printname1
#printtm
#printe_cat
end1=u'%s%s%s%s'%(tm,'',e_cat,'')
cur.execute("INSERTINTOxiaoshuo(title)VALUES('%s');"%(name1))
conn.commit()
#爬取各章链接
forlinkincatalogue.find_all(href=re.compile(".html")):
lianjie='http://www.biquge.com.tw/'+link.get('href')
a.append(lianjie)
#将各章的链接列表写入一个新列表,以供遍历,获取各章的列表
k=[]
k.append(a)
j=0
foriink:
whilej<=len(i)-1:
#爬取各章小说内容
url='http://www.biquge.com.tw/14_14055/9194140.html'
finallyurl=i[j]
html=requests.get(finallyurl).content
soup=BeautifulSoup(html,'html.parser')
tit=soup.find('div',attrs={'class':'bookname'})
title=tit.h1
content=soup.find(id='content').get_text()
section=title.get_text()
printsection
printcontent
j+=1
#end2=u'%s%s%s%s'%(title,'',content,'')
cur.execute("INSERTINTOxiaoshuo(sec_title,content)VALUES('%s','%s');"%(section,content))
conn.commit()
l+=1
conn.close()
相关问题推荐
换行。比如,print hello\nworld效果就是helloworld\n就是一个换行符。\是转义的意思,'\n'是换行,'\t'是tab,'\\'是,\ 是在编写程序中句子太长百,人为换行后加上\但print出来是一整行。...
十种常见排序算法一般分为以下几种:(1)非线性时间比较类排序:a. 交换类排序(快速排序、冒泡排序)b. 插入类排序(简单插入排序、希尔排序)c. 选择类排序(简单选择排序、堆排序)d. 归并排序(二路归并排序、多路归并排序)(2)线性时间非比较类排序:...
前景很好,中国正在产业升级,工业机器人和人工智能方面都会是强烈的热点,而且正好是在3~5年以后的时间。难度,肯定高,要求你有创新的思维能力,高数中的微积分、数列等等必须得非常好,软件编程(基础的应用最广泛的语言:C/C++)必须得很好,微电子(数字电...
迭代器与生成器的区别:(1)生成器:生成器本质上就是一个函数,它记住了上一次返回时在函数体中的位置。对生成器函数的第二次(或第n次)调用,跳转到函数上一次挂起的位置。而且记录了程序执行的上下文。生成器不仅记住了它的数据状态,生成器还记住了程序...
python中title( )属于python中字符串函数,返回’标题化‘的字符串,就是单词的开头为大写,其余为小写
第一种解释:代码中的cnt是count的简称,一种电脑计算机内部的数学函数的名字,在Excel办公软件中计算参数列表中的数字项的个数;在数据库( sq| server或者access )中可以用来统计符合条件的数据条数。函数COUNT在计数时,将把数值型的数字计算进去;但是...
head是方法,所以需要取小括号,即dataset.head()显示的则是前5行。data[:, :-1]和data[:, -1]。另外,如果想通过位置取数据,请使用iloc,即dataset.iloc[:, :-1]和dataset.iloc[:, -1],前者表示的是取所有行,但不包括最后一列的数据,结果是个DataFrame。...
挺简单的,其实课程内容没有我们想象的那么难、像我之前同学,完全零基础,培训了半年,直接出来就工作了,人家还在北京大公司上班,一个月15k,实力老厉害了
Python针对众多的类型,提供了众多的内建函数来处理(内建是相对于导入import来说的,后面学习到包package时,将会介绍),这些内建函数功用在于其往往可对多种类型对象进行类似的操作,即多种类型对象的共有的操作;如果某种操作只对特殊的某一类对象可行,Pyt...
相当于 ... 这里不是注释
还有FIXME
python的两个库:xlrd和xlutils。 xlrd打开excel,但是打开的excel并不能直接写入数据,需要用xlutils主要是复制一份出来,实现后续的写入功能。
单行注释:Python中的单行注释一般是以#开头的,#右边的文字都会被当做解释说明的内容,不会被当做执行的程序。为了保证代码的可读性,一般会在#后面加一两个空格然后在编写解释内容。示例:# 单行注释print(hello world)注释可以放在代码上面也可以放在代...
主要是按行读取,然后就是写出判断逻辑来勘测行是否为注视行,空行,编码行其他的:import linecachefile=open('3_2.txt','r')linecount=len(file.readlines())linecache.getline('3_2.txt',linecount)这样做的过程中发现一个问题,...
或许是里面有没被注释的代码
自学的话要看个人情况,可以先在B站找一下视频看一下