2021-03-09 13:52发布
[图]1.已安装2.环境变量如下问题:pip 安装时报错,请问应该怎么解决呢?程序小白在线等? 显示全部
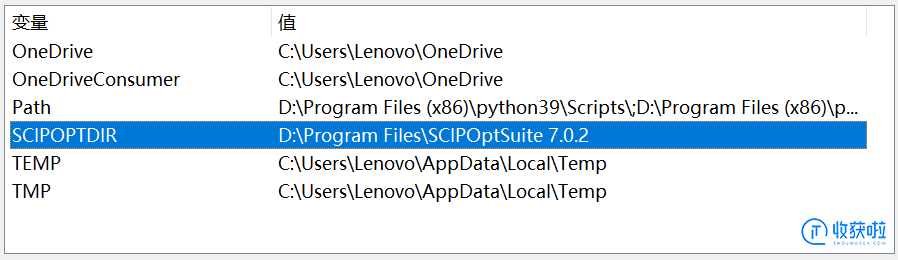
1.已安装
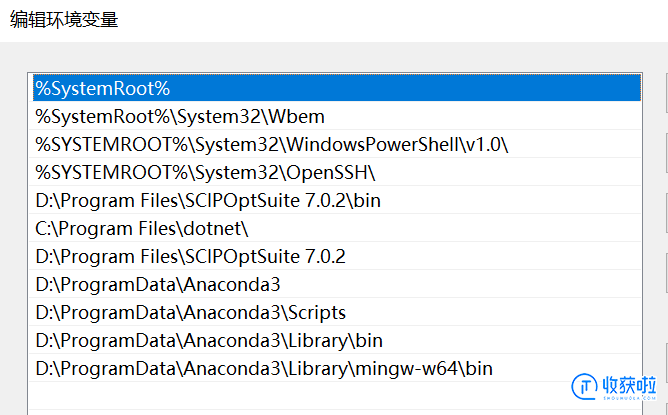
2.环境变量如下
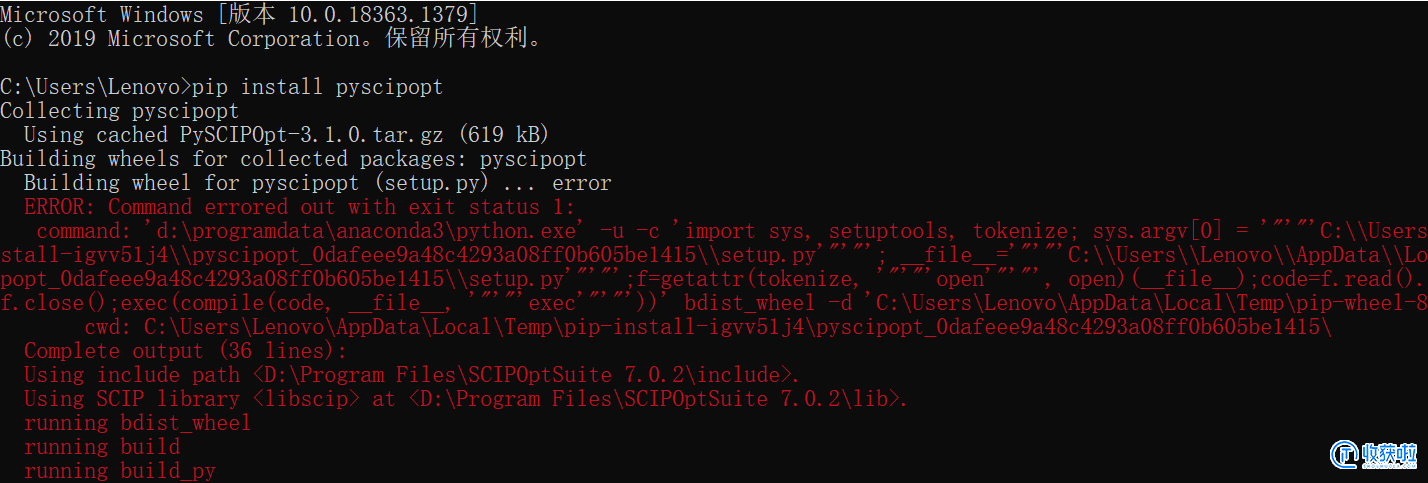
问题:pip 安装时报错,请问应该怎么解决呢?程序小白在线等?
文章目录
前言一、安装SCIP二、安装PySCIPOpt及中间的坑
前言
Linux下安装SCIP+PySCIPOpt时常会出现如下的报错,本文记录一下对这个问题的解决。
fatalerrorC1083:Cannotopenincludefile:'scip/scip.h':Nosuchfileordirectory
在Windows平台的下载步骤可以参考这篇博文,十分详细。WIndows平台的安装步骤:https://www.cnblogs.com/dengfaheng/p/10041488.html
一、安装SCIP
建议在官网下载源代码官网地址是https://www.scipopt.org/index.php#download建议下载scipoptsuite.tgz
之后的安装命令为
cdscipoptsuite-4.0.0
mkdirbuild
cdbuild
cmake..
make
之后配置一下环境
vim~/.bashrc
exportPATH=$PATH:~/software/scip/scipoptsuite-4.0.0/build/bin/
source~/.bashrc
之后可以在bash中输入scip进行测试
二、安装PySCIPOpt及中间的坑
正常来说下面直接
pipinstallPySCIPOpt
或者下载源码编译安装就行了,但直接这样的话就会遇到这个bug
使用cd命令进入文件夹~/software/scip/scipoptsuite-4.0.0/build/bin/,发现确实没有include文件夹,更不用说里面的scip.h头文件了
那么include文件夹在哪儿呢?
实际上就在刚刚下载的scipoptsuite.tgz下面将其解压之后,拷贝到~/software/scip/scipoptsuite-4.0.0/build/bin/之后就大功告成了!
在下载源代码进行安装时,在
pythonsetup.pyinstall
之前,需要指定路径,即
exportSCIPOPTDIR=~/software/scip/scipoptsuite-4.0.0/build/bin
1.报错:ReadTimeoutError: HTTPSConnectionPool(host=’pypi.python.org’, port=443): Read timed out.
Downloading xgboost-0.6a2.tar.gz (1.2MB)
48% |███████████████▋ | 583kB 47kB/s eta 0:00:13Exception:
Traceback (most recent call last):
File "c:\python27\lib\site-packages\pip\basecommand.py", line 215, in main
status = self.run(options, args)
File "c:\python27\lib\site-packages\pip\commands\install.py", line 335, in run
wb.build(autobuilding=True)
File "c:\python27\lib\site-packages\pip\wheel.py", line 749, in build
self.requirement_set.prepare_files(self.finder)
File "c:\python27\lib\site-packages\pip\req\req_set.py", line 380, in prepare_files
ignore_dependencies=self.ignore_dependencies))
File "c:\python27\lib\site-packages\pip\req\req_set.py", line 620, in _prepare_file
session=self.session, hashes=hashes)
File "c:\python27\lib\site-packages\pip\download.py", line 821, in unpack_url
hashes=hashes
File "c:\python27\lib\site-packages\pip\download.py", line 659, in unpack_http_url
hashes)
File "c:\python27\lib\site-packages\pip\download.py", line 882, in _download_http_url
_download_url(resp, link, content_file, hashes)
File "c:\python27\lib\site-packages\pip\download.py", line 603, in _download_url
hashes.check_against_chunks(downloaded_chunks)
File "c:\python27\lib\site-packages\pip\utils\hashes.py", line 46, in check_against_chunks
for chunk in chunks:
File "c:\python27\lib\site-packages\pip\download.py", line 571, in written_chunks
File "c:\python27\lib\site-packages\pip\utils\ui.py", line 139, in iter
for x in it:
File "c:\python27\lib\site-packages\pip\download.py", line 560, in resp_read
decode_content=False):
File "c:\python27\lib\site-packages\pip\_vendor\requests\packages\urllib3\response.py", line 357, in stream
data = self.read(amt=amt, decode_content=decode_content)
File "c:\python27\lib\site-packages\pip\_vendor\requests\packages\urllib3\response.py", line 324, in read
flush_decoder = True
File "c:\python27\lib\contextlib.py", line 35, in __exit__
self.gen.throw(type, value, traceback)
File "c:\python27\lib\site-packages\pip\_vendor\requests\packages\urllib3\response.py", line 246, in _error_catcher
raise ReadTimeoutError(self._pool, None, 'Read timed out.')
ReadTimeoutError: HTTPSConnectionPool(host='pypi.python.org', port=443): Read timed out.
错误原因:连不上pip的源,下载依赖包失败
解决1(推荐):在pip安装所在文件夹路径下,创造python文件(.py)
import os
ini="""[global]
index-url = https://pypi.doubanio.com/simple/
[install]
trusted-host=pypi.doubanio.com
"""
pippath=os.environ["USERPROFILE"]+"\\pip\\"
if not os.path.exists(pippath):
os.mkdir(pippath)
with open(pippath+"pip.ini","w+") as f:
f.write(ini)
在cmd上运行这个.py文件即可
之后再用pip install安装指令下载速度会非常快
解决2:修改加大超时时间
pip --default-timeout=100 install -U pip
1
如下指令安装
pip --default-timeout=100 install -U scrapy(库名)
解决3:到https://pypi.python.org/simple/pip/下载相对应的.whl文件
下载完之后,在用pip安装:
pip install (path)/pip-8.1.2-py2.py3-none-any.whl
更换下载源:
豆瓣源 : http://pypi.douban.com/simple/
清华源: https://pypi.tuna.tsinghua.edu.cn/simple
使用方法 : pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pyscipopt
python通过pyscipopt包来调用安装好的SCIPOptSuite,所以还需要安装pyscipopt,直接pip install pyscipopt==版本号 安装pyscipopt包,建议直接指定版本号,默认的有时候会出错。
pip install pyscipopt==版本号
1、如果出现报错,注意看是什么,如果缺少依赖则安装相应依赖即可
2、如果是版本问题则要注意pyscipopt的版本是否和SCIPOptSuite的版本匹配,匹配关系见https://github.com/SCIP-Interfaces/PySCIPOpt/blob/master/INSTALL.md
另外一种特殊情况,如果没有指定版本号,即直接pip install pyscipopt默认的PySCIPOpt包版本不对,就像这样子,所以最好指定版本号。
pip install pyscipopt
换行。比如,print hello\nworld效果就是helloworld\n就是一个换行符。\是转义的意思,'\n'是换行,'\t'是tab,'\\'是,\ 是在编写程序中句子太长百,人为换行后加上\但print出来是一整行。...
十种常见排序算法一般分为以下几种:(1)非线性时间比较类排序:a. 交换类排序(快速排序、冒泡排序)b. 插入类排序(简单插入排序、希尔排序)c. 选择类排序(简单选择排序、堆排序)d. 归并排序(二路归并排序、多路归并排序)(2)线性时间非比较类排序:...
前景很好,中国正在产业升级,工业机器人和人工智能方面都会是强烈的热点,而且正好是在3~5年以后的时间。难度,肯定高,要求你有创新的思维能力,高数中的微积分、数列等等必须得非常好,软件编程(基础的应用最广泛的语言:C/C++)必须得很好,微电子(数字电...
迭代器与生成器的区别:(1)生成器:生成器本质上就是一个函数,它记住了上一次返回时在函数体中的位置。对生成器函数的第二次(或第n次)调用,跳转到函数上一次挂起的位置。而且记录了程序执行的上下文。生成器不仅记住了它的数据状态,生成器还记住了程序...
python中title( )属于python中字符串函数,返回’标题化‘的字符串,就是单词的开头为大写,其余为小写
第一种解释:代码中的cnt是count的简称,一种电脑计算机内部的数学函数的名字,在Excel办公软件中计算参数列表中的数字项的个数;在数据库( sq| server或者access )中可以用来统计符合条件的数据条数。函数COUNT在计数时,将把数值型的数字计算进去;但是...
head是方法,所以需要取小括号,即dataset.head()显示的则是前5行。data[:, :-1]和data[:, -1]。另外,如果想通过位置取数据,请使用iloc,即dataset.iloc[:, :-1]和dataset.iloc[:, -1],前者表示的是取所有行,但不包括最后一列的数据,结果是个DataFrame。...
挺简单的,其实课程内容没有我们想象的那么难、像我之前同学,完全零基础,培训了半年,直接出来就工作了,人家还在北京大公司上班,一个月15k,实力老厉害了
Python针对众多的类型,提供了众多的内建函数来处理(内建是相对于导入import来说的,后面学习到包package时,将会介绍),这些内建函数功用在于其往往可对多种类型对象进行类似的操作,即多种类型对象的共有的操作;如果某种操作只对特殊的某一类对象可行,Pyt...
相当于 ... 这里不是注释
还有FIXME
python的两个库:xlrd和xlutils。 xlrd打开excel,但是打开的excel并不能直接写入数据,需要用xlutils主要是复制一份出来,实现后续的写入功能。
单行注释:Python中的单行注释一般是以#开头的,#右边的文字都会被当做解释说明的内容,不会被当做执行的程序。为了保证代码的可读性,一般会在#后面加一两个空格然后在编写解释内容。示例:# 单行注释print(hello world)注释可以放在代码上面也可以放在代...
主要是按行读取,然后就是写出判断逻辑来勘测行是否为注视行,空行,编码行其他的:import linecachefile=open('3_2.txt','r')linecount=len(file.readlines())linecache.getline('3_2.txt',linecount)这样做的过程中发现一个问题,...
或许是里面有没被注释的代码
自学的话要看个人情况,可以先在B站找一下视频看一下
最多设置5个标签!
{var%20f='http://v.t.sina.com.cn/share/share.php?appkey=1515056452',u=z||d.location,p=['&url=',e(u),'&title=',e(t||d.title),'&source=',e(r),'&sourceUrl=',e(l),'&content=',c||'gb2312','&pic=',e(p||'')].join('');function%20a(){if(!window.open([f,p].join(''),'mb',['toolbar=0,status=0,resizable=1,width=440,height=430,left=',(s.width-440)/2,',top=',(s.height-430)/2].join('')))u.href=[f,p].join('');};if(/Firefox/.test(navigator.userAgent))setTimeout(a,0);else%20a();})(screen,document,encodeURIComponent,'','','/static/images/logo.png', '推荐 银河对视 的问题《pip install pyscipopt 报错》','http://www.shouhuola.com/q-34764.html','页面编码gb2312|utf-8默认gb2312'));){kind=link}
文章目录
前言一、安装SCIP二、安装PySCIPOpt及中间的坑
前言
Linux下安装SCIP+PySCIPOpt时常会出现如下的报错,本文记录一下对这个问题的解决。
fatalerrorC1083:Cannotopenincludefile:'scip/scip.h':Nosuchfileordirectory
在Windows平台的下载步骤可以参考这篇博文,十分详细。WIndows平台的安装步骤:https://www.cnblogs.com/dengfaheng/p/10041488.html
一、安装SCIP
建议在官网下载源代码官网地址是https://www.scipopt.org/index.php#download建议下载scipoptsuite.tgz
之后的安装命令为
cdscipoptsuite-4.0.0
mkdirbuild
cdbuild
cmake..
make
之后配置一下环境
vim~/.bashrc
exportPATH=$PATH:~/software/scip/scipoptsuite-4.0.0/build/bin/
source~/.bashrc
之后可以在bash中输入scip进行测试
二、安装PySCIPOpt及中间的坑
正常来说下面直接
pipinstallPySCIPOpt
或者下载源码编译安装就行了,但直接这样的话就会遇到这个bug
fatalerrorC1083:Cannotopenincludefile:'scip/scip.h':Nosuchfileordirectory
使用cd命令进入文件夹~/software/scip/scipoptsuite-4.0.0/build/bin/,发现确实没有include文件夹,更不用说里面的scip.h头文件了
那么include文件夹在哪儿呢?
实际上就在刚刚下载的scipoptsuite.tgz下面将其解压之后,拷贝到~/software/scip/scipoptsuite-4.0.0/build/bin/之后就大功告成了!
在下载源代码进行安装时,在
pythonsetup.pyinstall
之前,需要指定路径,即
exportSCIPOPTDIR=~/software/scip/scipoptsuite-4.0.0/build/bin
1.报错:ReadTimeoutError: HTTPSConnectionPool(host=’pypi.python.org’, port=443): Read timed out.
Downloading xgboost-0.6a2.tar.gz (1.2MB)
48% |███████████████▋ | 583kB 47kB/s eta 0:00:13Exception:
Traceback (most recent call last):
File "c:\python27\lib\site-packages\pip\basecommand.py", line 215, in main
status = self.run(options, args)
File "c:\python27\lib\site-packages\pip\commands\install.py", line 335, in run
wb.build(autobuilding=True)
File "c:\python27\lib\site-packages\pip\wheel.py", line 749, in build
self.requirement_set.prepare_files(self.finder)
File "c:\python27\lib\site-packages\pip\req\req_set.py", line 380, in prepare_files
ignore_dependencies=self.ignore_dependencies))
File "c:\python27\lib\site-packages\pip\req\req_set.py", line 620, in _prepare_file
session=self.session, hashes=hashes)
File "c:\python27\lib\site-packages\pip\download.py", line 821, in unpack_url
hashes=hashes
File "c:\python27\lib\site-packages\pip\download.py", line 659, in unpack_http_url
hashes)
File "c:\python27\lib\site-packages\pip\download.py", line 882, in _download_http_url
_download_url(resp, link, content_file, hashes)
File "c:\python27\lib\site-packages\pip\download.py", line 603, in _download_url
hashes.check_against_chunks(downloaded_chunks)
File "c:\python27\lib\site-packages\pip\utils\hashes.py", line 46, in check_against_chunks
for chunk in chunks:
File "c:\python27\lib\site-packages\pip\download.py", line 571, in written_chunks
for chunk in chunks:
File "c:\python27\lib\site-packages\pip\utils\ui.py", line 139, in iter
for x in it:
File "c:\python27\lib\site-packages\pip\download.py", line 560, in resp_read
decode_content=False):
File "c:\python27\lib\site-packages\pip\_vendor\requests\packages\urllib3\response.py", line 357, in stream
data = self.read(amt=amt, decode_content=decode_content)
File "c:\python27\lib\site-packages\pip\_vendor\requests\packages\urllib3\response.py", line 324, in read
flush_decoder = True
File "c:\python27\lib\contextlib.py", line 35, in __exit__
self.gen.throw(type, value, traceback)
File "c:\python27\lib\site-packages\pip\_vendor\requests\packages\urllib3\response.py", line 246, in _error_catcher
raise ReadTimeoutError(self._pool, None, 'Read timed out.')
ReadTimeoutError: HTTPSConnectionPool(host='pypi.python.org', port=443): Read timed out.
错误原因:连不上pip的源,下载依赖包失败
解决1(推荐):在pip安装所在文件夹路径下,创造python文件(.py)
import os
ini="""[global]
index-url = https://pypi.doubanio.com/simple/
[install]
trusted-host=pypi.doubanio.com
"""
pippath=os.environ["USERPROFILE"]+"\\pip\\"
if not os.path.exists(pippath):
os.mkdir(pippath)
with open(pippath+"pip.ini","w+") as f:
f.write(ini)
在cmd上运行这个.py文件即可
之后再用pip install安装指令下载速度会非常快
解决2:修改加大超时时间
pip --default-timeout=100 install -U pip
1
如下指令安装
pip --default-timeout=100 install -U scrapy(库名)
1
解决3:到https://pypi.python.org/simple/pip/下载相对应的.whl文件
下载完之后,在用pip安装:
pip install (path)/pip-8.1.2-py2.py3-none-any.whl
更换下载源:
豆瓣源 : http://pypi.douban.com/simple/
清华源: https://pypi.tuna.tsinghua.edu.cn/simple
使用方法 : pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pyscipopt
python通过pyscipopt包来调用安装好的SCIPOptSuite,所以还需要安装pyscipopt,直接
pip install pyscipopt==版本号安装pyscipopt包,建议直接指定版本号,默认的有时候会出错。1、如果出现报错,注意看是什么,如果缺少依赖则安装相应依赖即可
2、如果是版本问题则要注意pyscipopt的版本是否和SCIPOptSuite的版本匹配,匹配关系见https://github.com/SCIP-Interfaces/PySCIPOpt/blob/master/INSTALL.md
另外一种特殊情况,如果没有指定版本号,即直接
pip install pyscipopt默认的PySCIPOpt包版本不对,就像这样子,所以最好指定版本号。相关问题推荐
换行。比如,print hello\nworld效果就是helloworld\n就是一个换行符。\是转义的意思,'\n'是换行,'\t'是tab,'\\'是,\ 是在编写程序中句子太长百,人为换行后加上\但print出来是一整行。...
十种常见排序算法一般分为以下几种:(1)非线性时间比较类排序:a. 交换类排序(快速排序、冒泡排序)b. 插入类排序(简单插入排序、希尔排序)c. 选择类排序(简单选择排序、堆排序)d. 归并排序(二路归并排序、多路归并排序)(2)线性时间非比较类排序:...
前景很好,中国正在产业升级,工业机器人和人工智能方面都会是强烈的热点,而且正好是在3~5年以后的时间。难度,肯定高,要求你有创新的思维能力,高数中的微积分、数列等等必须得非常好,软件编程(基础的应用最广泛的语言:C/C++)必须得很好,微电子(数字电...
迭代器与生成器的区别:(1)生成器:生成器本质上就是一个函数,它记住了上一次返回时在函数体中的位置。对生成器函数的第二次(或第n次)调用,跳转到函数上一次挂起的位置。而且记录了程序执行的上下文。生成器不仅记住了它的数据状态,生成器还记住了程序...
python中title( )属于python中字符串函数,返回’标题化‘的字符串,就是单词的开头为大写,其余为小写
第一种解释:代码中的cnt是count的简称,一种电脑计算机内部的数学函数的名字,在Excel办公软件中计算参数列表中的数字项的个数;在数据库( sq| server或者access )中可以用来统计符合条件的数据条数。函数COUNT在计数时,将把数值型的数字计算进去;但是...
head是方法,所以需要取小括号,即dataset.head()显示的则是前5行。data[:, :-1]和data[:, -1]。另外,如果想通过位置取数据,请使用iloc,即dataset.iloc[:, :-1]和dataset.iloc[:, -1],前者表示的是取所有行,但不包括最后一列的数据,结果是个DataFrame。...
挺简单的,其实课程内容没有我们想象的那么难、像我之前同学,完全零基础,培训了半年,直接出来就工作了,人家还在北京大公司上班,一个月15k,实力老厉害了
Python针对众多的类型,提供了众多的内建函数来处理(内建是相对于导入import来说的,后面学习到包package时,将会介绍),这些内建函数功用在于其往往可对多种类型对象进行类似的操作,即多种类型对象的共有的操作;如果某种操作只对特殊的某一类对象可行,Pyt...
相当于 ... 这里不是注释
还有FIXME
python的两个库:xlrd和xlutils。 xlrd打开excel,但是打开的excel并不能直接写入数据,需要用xlutils主要是复制一份出来,实现后续的写入功能。
单行注释:Python中的单行注释一般是以#开头的,#右边的文字都会被当做解释说明的内容,不会被当做执行的程序。为了保证代码的可读性,一般会在#后面加一两个空格然后在编写解释内容。示例:# 单行注释print(hello world)注释可以放在代码上面也可以放在代...
主要是按行读取,然后就是写出判断逻辑来勘测行是否为注视行,空行,编码行其他的:import linecachefile=open('3_2.txt','r')linecount=len(file.readlines())linecache.getline('3_2.txt',linecount)这样做的过程中发现一个问题,...
或许是里面有没被注释的代码
自学的话要看个人情况,可以先在B站找一下视频看一下